Spark笔记之使用UDAF(User Defined Aggregate Function)
一、UDAF简介
先解释一下什么是UDAF(User Defined Aggregate Function),即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组(一般是多行)输入然后产生一个输出,即将一组的值想办法聚合一下。
关于UDAF的一个误区
我们可能下意识的认为UDAF是需要和group by一起使用的,实际上UDAF可以跟group by一起使用,也可以不跟group by一起使用,这个其实比较好理解,联想到mysql中的max、min等函数,可以:
select max(foo) from foobar group by bar;
表示根据bar字段分组,然后求每个分组的最大值,这时候的分组有很多个,使用这个函数对每个分组进行处理,也可以:
select max(foo) from foobar;
这种情况可以将整张表看做是一个分组,然后在这个分组(实际上就是一整张表)中求最大值。所以聚合函数实际上是对分组做处理,而不关心分组中记录的具体数量。
二、UDAF使用
2.1 继承UserDefinedAggregateFunction
使用UserDefinedAggregateFunction的套路:
1. 自定义类继承UserDefinedAggregateFunction,对每个阶段方法做实现
2. 在spark中注册UDAF,为其绑定一个名字
3. 然后就可以在sql语句中使用上面绑定的名字调用
下面写一个计算平均值的UDAF例子,首先定义一个类继承UserDefinedAggregateFunction:
package cc11001100.spark.sql.udaf import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._ object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction { // 聚合函数的输入数据结构
override def inputSchema: StructType = StructType(StructField("input", LongType) :: Nil) // 缓存区数据结构
override def bufferSchema: StructType = StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil) // 聚合函数返回值数据结构
override def dataType: DataType = DoubleType // 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出
override def deterministic: Boolean = true // 初始化缓冲区
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
} // 给聚合函数传入一条新数据进行处理
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (input.isNullAt(0)) return
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
} // 合并聚合函数缓冲区
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
} // 计算最终结果
override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble / buffer.getLong(1) }
然后注册并使用它:
package cc11001100.spark.sql.udaf
import org.apache.spark.sql.SparkSession
object SparkSqlUDAFDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkStudy").getOrCreate()
spark.read.json("data/user").createOrReplaceTempView("v_user")
spark.udf.register("u_avg", AverageUserDefinedAggregateFunction)
// 将整张表看做是一个分组对求所有人的平均年龄
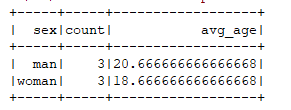
spark.sql("select count(1) as count, u_avg(age) as avg_age from v_user").show()
// 按照性别分组求平均年龄
spark.sql("select sex, count(1) as count, u_avg(age) as avg_age from v_user group by sex").show()
}
}
使用到的数据集:
{"id": 1001, "name": "foo", "sex": "man", "age": 20}
{"id": 1002, "name": "bar", "sex": "man", "age": 24}
{"id": 1003, "name": "baz", "sex": "man", "age": 18}
{"id": 1004, "name": "foo1", "sex": "woman", "age": 17}
{"id": 1005, "name": "bar2", "sex": "woman", "age": 19}
{"id": 1006, "name": "baz3", "sex": "woman", "age": 20}
运行结果:

2.2 继承Aggregator
还有另一种方式就是继承Aggregator这个类,优点是可以带类型:
package cc11001100.spark.sql.udaf import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders} /**
* 计算平均值
*
*/
object AverageAggregator extends Aggregator[User, Average, Double] { // 初始化buffer
override def zero: Average = Average(0L, 0L) // 处理一条新的记录
override def reduce(b: Average, a: User): Average = {
b.sum += a.age
b.count += 1L
b
} // 合并聚合buffer
override def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
} // 减少中间数据传输
override def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count override def bufferEncoder: Encoder[Average] = Encoders.product // 最终输出结果的类型
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble } /**
* 计算平均值过程中使用的Buffer
*
* @param sum
* @param count
*/
case class Average(var sum: Long, var count: Long) {
} case class User(id: Long, name: String, sex: String, age: Long) {
}
调用:
package cc11001100.spark.sql.udaf
import org.apache.spark.sql.SparkSession
object AverageAggregatorDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkStudy").getOrCreate()
import spark.implicits._
val user = spark.read.json("data/user").as[User]
user.select(AverageAggregator.toColumn.name("avg")).show()
}
}
运行结果:
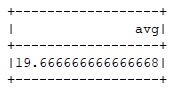
.
Spark笔记之使用UDAF(User Defined Aggregate Function)的更多相关文章
- 转:Spark User Defined Aggregate Function (UDAF) using Java
Sometimes the aggregate functions provided by Spark are not adequate, so Spark has a provision of ac ...
- Spark笔记之使用UDF(User Define Function)
一.UDF介绍 UDF(User Define Function),即用户自定义函数,Spark的官方文档中没有对UDF做过多介绍,猜想可能是认为比较简单吧. 几乎所有sql数据库的实现都为用户提供了 ...
- spark自定义函数之——UDAF使用详解及代码示例
UDAF简介 UDAF(User Defined Aggregate Function)即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组( ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十五)Spark编写UDF、UDAF、Agg函数
Spark Sql提供了丰富的内置函数让开发者来使用,但实际开发业务场景可能很复杂,内置函数不能够满足业务需求,因此spark sql提供了可扩展的内置函数. UDF:是普通函数,输入一个或多个参数, ...
- spark笔记 环境配置
spark笔记 spark简介 saprk 有六个核心组件: SparkCore.SparkSQL.SparkStreaming.StructedStreaming.MLlib,Graphx Spar ...
- Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function)
Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 【理解】column must appear in the GROUP BY clause or be used in an aggregate function
column "ms.xxx_time" must appear in the GROUP BY clause or be used in an aggregate functio ...
- invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause
Column 'dbo.tbm_vie_View.ViewID' is invalid in the select list because it is not contained in either ...
- must appear in the GROUP BY clause or be used in an aggregate function
今天在分组统计的时候pgsql报错 must appear in the GROUP BY clause or be used in an aggregate function,在mysql里面是可以 ...
随机推荐
- DVWA渗透测试系列 一 (DVWA环境配置)
DVWA介绍: DVWA是一个渗透测试靶机系统. DVWA具有十个模块:分别是 Brute Force(暴力破解).Command Injection(命令行注入).CSRF(跨站请求伪造).File ...
- “北航Clubs” Beta版本开发目标
Beta版本开发目标 总体设想:修复Alpha版本中的若干bug,并在Alpha版本成果之上进行进一步开发,实现社员管理.评论.站内信等功能. 1.对Alpha版本功能的更新与加强 后端实现从SQLi ...
- 基于Winform框架DataGridView控件的SqlServer数据库查询展示功能的实现
关键词:Winform.DataGridView.SqlServer 一个基于winform框架的C/S软件,主要实现对SqlServer数据库数据表的实时查询. 一.为DataGridView添加数 ...
- 读C#程序最小公倍数答案就是:2123581660200
阅读下面程序,请回答如下问题: 问题1:这个程序要找的是符合什么条件的数? 问题2:这样的数存在么?符合这一条件的最小的数是什么? 问题3:在电脑上运行这一程序,你估计多长时间才能输出第一个结果?时间 ...
- Jmeter put 方法总结
1.百度到很多关于jmeter put 方法的使用 ,但觉得都完全 下面我大致总结下 : >1.放入 url 中 如:www.*****.com?a=1&b=2 ; >2.放入到p ...
- [转帖]kubeadm 实现细节
kubeadm 实现细节 http://docs.kubernetes.org.cn/829.html 1 核心设计原则 2 常量和众所周知的值和路径 3 kubeadm init 工作流程内部设计 ...
- 自定义SAP用户密码规则
一般实施SAP的公司因为安全性问题都会启用一定规则的用户密码强度,普遍的做法是让Basis在RZ10里面给系统参数做赋值,然后重启服务来实现对所有用户的密码规则的定义.但这样的话对所有用户有效,没办法 ...
- Codeforces Round #528 Div. 1 自闭记
整天自闭. A:有各种讨论方式.我按横坐标排了下然后讨论了下纵坐标单调和不单调两种情况.写了15min也就算了,谁能告诉我printf和cout输出不一样是咋回事啊?又调了10min啊?upd:突然想 ...
- webapi Route 特性
转载:http://www.th7.cn/Program/net/201410/302571.shtml ASP.NET Web API路由,简单来说,就是把客户端请求映射到对应的Action上的过程 ...
- 自学Zabbix3.10.1.5-事件通知Notifications upon events-媒介类型Script
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 自学Zabbix3.10.1.5-事件通知Notifications upon events-媒介 ...