EM算法理解
一、概述
概率模型有时既含有观测变量,又含有隐变量,如果概率模型的变量都是观测变量,那么给定数据,可以直接利用极大似然估计法或者贝叶斯估计法估计模型参数。但是,当模型同时又含有隐变量时,就不能简单地使用这些方法。EM算法适用于带有隐变量的概率模型的参数估计,利用极大似然估计法逐步迭代求解。
二、jensen不等式
 是区间
是区间 上的凸函数,则对任意的
上的凸函数,则对任意的 ,有不等式:
,有不等式:


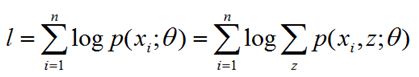
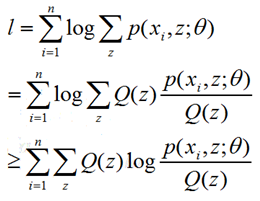
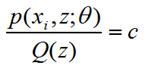
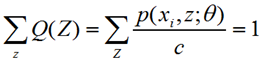



首先,初始化参数θ
(1)E-Step:根据已知参数θ计算每个样本属于z的概率,即这个身高来自广东或东北的概率,这个概率就是Q(z),这一步为什么叫求期望呢?我的理解是这样的,下界函数是 ∑∑Q(z)*log(p(x,z;θ)/Q(z)),Q(z)本身就是一个概率分布,所以这正是求期望的公式。
(2)M-Step:根据计算得到的Q(z),求出含有θ的似然函数的下界并最大化它,得到新的参数θ。这里面下界函数中,Q(z)带入初始化或者前一步已知的θ参数值,而p(xi,z;θ)中Θ参数还是未知,相当于成了以θ为变量的函数,这一步极大化求函数的极值点对应的θ点即可。
重复(1)和(2)直到收敛,可以看到,从思想上来说,和最开始没什么两样,只不过直接最大化似然函数不好做,曲线救国而已。
至于为什么这样的迭代会保证似然函数单调不减,即EM算法的收敛性证明,《统计学习方法》里面有证明。EM算法在一般情况是收敛的,但是不保证收敛到全局最优,即有可能进入局部的最优。
EM算法理解的更多相关文章
- EM算法理解的九层境界
EM算法理解的九层境界 EM 就是 E + M EM 是一种局部下限构造 K-Means是一种Hard EM算法 从EM 到 广义EM 广义EM的一个特例是VBEM 广义EM的另一个特例是WS算法 广 ...
- 超详细的EM算法理解
众所周知,极大似然估计是一种应用很广泛的参数估计方法.例如我手头有一些东北人的身高的数据,又知道身高的概率模型是高斯分布,那么利用极大化似然函数的方法可以估计出高斯分布的两个参数,均值和方差.这个方法 ...
- Machine Learning系列--EM算法理解与推导
EM算法,全称Expectation Maximization Algorithm,译作最大期望化算法或期望最大算法,是机器学习十大算法之一,吴军博士在<数学之美>书中称其为“上帝视角”算 ...
- EM算法浅析(一)-问题引出
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.基本认识 EM(Expectation Maximization Algorithm)算法即期望 ...
- EM算法-完整推导
前篇已经对EM过程,举了扔硬币和高斯分布等案例来直观认识了, 目标是参数估计, 分为 E-step 和 M-step, 不断循环, 直到收敛则求出了近似的估计参数, 不多说了, 本篇不说栗子, 直接来 ...
- 如何感性地理解EM算法?
https://www.jianshu.com/p/1121509ac1dc 如果使用基于最大似然估计的模型,模型中存在隐变量,就要用EM算法做参数估计.个人认为,理解EM算法背后的idea,远比看懂 ...
- 浅谈EM算法的两个理解角度
http://blog.csdn.net/xmu_jupiter/article/details/50936177 最近在写毕业论文,由于EM算法在我的研究方向中经常用到,所以把相关的资料又拿出来看了 ...
- EM算法之不同的推导方法和自己的理解
EM算法之不同的推导方法和自己的理解 一.前言 EM算法主要针对概率生成模型解决具有隐变量的混合模型的参数估计问题. 对于简单的模型,根据极大似然估计的方法可以直接得到解析解:可以在具有隐变量的复杂模 ...
- 对EM算法的理解
EM算法中要寻找的参数θ,与K-means聚类中的质心是对应的,在高斯混合模型中确定了θ,便可为样本进行类别的划分,属于哪个高斯分布的概率大就是哪一类,而这一点与K-means中的质心一样,质心确定了 ...
随机推荐
- 【MOOC EXP】Linux内核分析实验一报告
程涵 原创博客 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 [反汇编一个简单的C程序] 实验 ...
- 基于SSH框架的网上书店系统开发的质量属性
基于SSH框架的网上书店系统开发的质量属性 对于我的基于SSH框架的网上书店系统的开发要实现的质量属性有可用性.可修改性.性能.安全性.易用性和可测试性. 1.对于可用性方面的战术: 可用性(Avai ...
- 四则运算APP最后阶段
四则运算APP最后阶段 [开发环境]:eclipse [开发项目]:小学生四则运算APP [开发人员]:郑胜斌 http://www.cnblogs.com/zsb1/ 孔德颖 http://www. ...
- ctr中的GBDT+LR的优点
1 为什么gbdt+lr优于gbdt? 其实gbdt+lr类似于做了一个stacking.gbdt+lr模型中,把gbdt的叶子节点作为lr的输入,而gbdt的叶子节点相当于它的输出y',用这个y'作 ...
- everything 提供http和ftp的功能
1. 早上起床看知乎,发现everything 有http和ftp的功能, 简单看了一下的确很强大.. 就是有点危险.. 功能位置. 2. 最下面有FTP和HTTP 可以进行启用 这是http的 建议 ...
- CopyOnWriteArrayList、CopyOnWriteArraySet、ConcurrentHashMap的实现原理和适用场景
ConcurrentHashMap代替同步的Map(Collections.synchronized(new HashMap())),众所周知,HashMap是根据散列值分段存储的,同步Map在同步的 ...
- Java获取当前运行方法所在的类和方法名
很简单,直接看代码: public void showClassAndMethod() { System.out.println(this.getClass().getSimpleName() + & ...
- maven测试时中文乱码问题解决方法
pom.xml增加-Dfile.encoding=UTF-8配置,如下: <plugin> <!--升级到新版本解决控制台乱码问题--> <groupId>org. ...
- resultMap 表示转换字段后 resultType 表示没·有转换字段
resultMap 表示转换字段后 resultType 表示没·有转换字段
- Session in BSU CodeForces - 1027F(思维 树 基环树 离散化)
题意: 有n门考试,每门考试都有两个时间,存在几门考试时间冲突,求考完所有的考试,所用的最后时间的最小值 解析: 对于时间冲突的考试 就是一个联通块 把每个考试看作边,两个时间看作点,那么时间冲突的考 ...