python实现广度优先搜索和深度优先搜索
图的概念
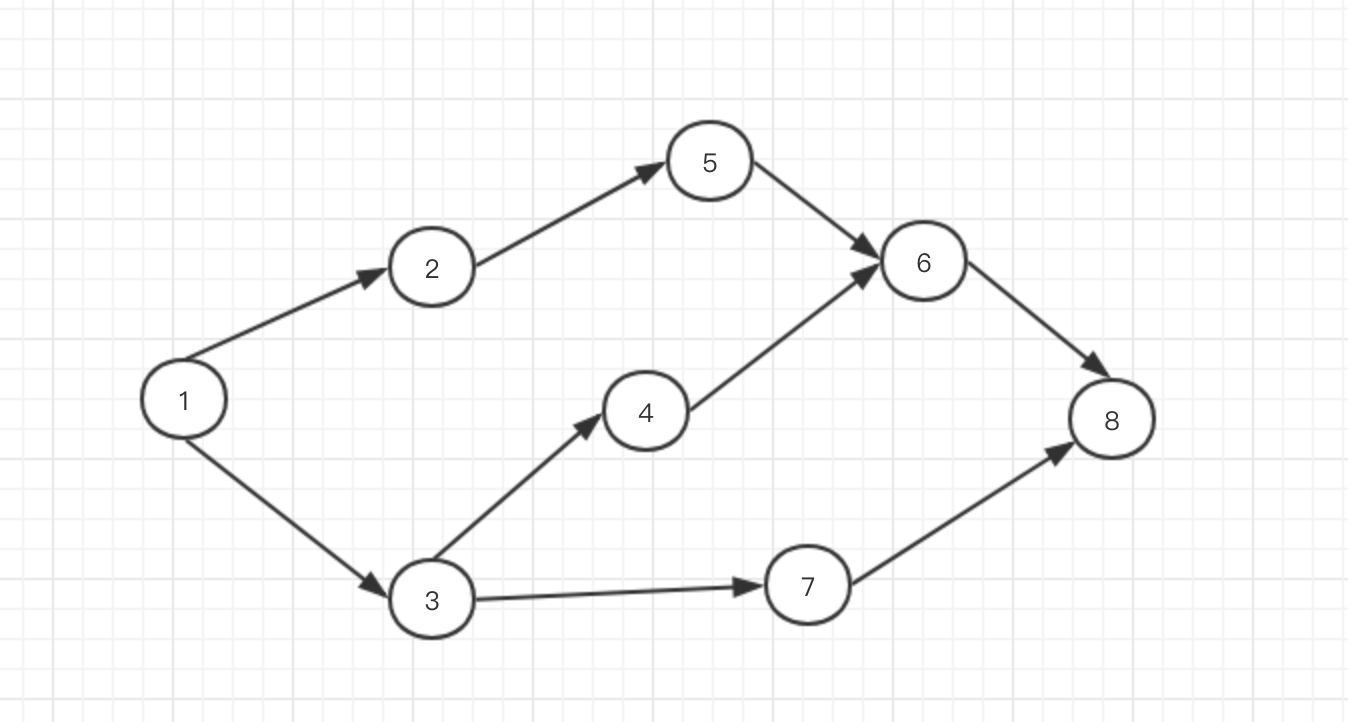
图表示的是多点之间的连接关系,由节点和边组成。类型分为有向图,无向图,加权图等,任何问题只要能抽象为图,那么就可以应用相应的图算法。
用字典来表示图
这里我们以有向图举例,有向图的邻居节点是要顺着箭头方向,逆箭头方向的节点不算作邻居节点。
在python中,我们使用字典来表示图,我们将图相邻节点之间的连接转换为字典键值之间的映射关系。比如上图中的1的相邻节点为2和3,即可表示如下:
graph={}
graph[1] = [2,3]
按照这种方式,上图可以完整表示为:
graph={}
graph[1] = [3,2] # 这里为了演示,调换一下位置
graph[2] = [5]
graph[3] = [4,7]
graph[4] = [6]
graph[5] = [6]
graph[6] = [8]
graph[7] = [8]
graph[8] = []
如此我们将所有节点和其相邻节点之间的连接关系全部描述一遍就得到了图的字典表示形式。节点8由于没有相邻节点,我们将其置为空列表。
广度优先搜索
广度优先搜索和深度优先搜索是图遍历的两种算法,广度和深度的区别在于对节点的遍历顺序不同。广度优先算法的遍历顺序是由近及远,先看到的节点先遍历。
接下来使用python实现广度优先搜索并找到最短路径:
from collections import deque
from collections import namedtuple
def bfs(start_node, end_node, graph): # 开始节点 目标节点 图字典
node = namedtuple('node', 'name, from_node') # 使用namedtuple定义节点,用于存储前置节点
search_queue = deque() # 使用双端队列,这里当作队列使用,根据先进先出获取下一个遍历的节点
name_search = deque() # 存储队列中已有的节点名称
visited = {} # 存储已经访问过的节点
search_queue.append(node(start_node, None)) # 填入初始节点,从队列后面加入
name_search.append(start_node) # 填入初始节点名称
path = [] # 用户回溯路径
path_len = 0 # 路径长度
print('开始搜索...')
while search_queue: # 只要搜索队列中有数据就一直遍历下去
print('待遍历节点: ', name_search)
current_node = search_queue.popleft() # 从队列前边获取节点,即先进先出,这是BFS的核心
name_search.popleft() # 将名称也相应弹出
if current_node.name not in visited: # 当前节点是否被访问过
print('当前节点: ', current_node.name, end=' | ')
if current_node.name == end_node: # 退出条件,找到了目标节点,接下来执行路径回溯和长度计算
pre_node = current_node # 路径回溯的关键在于每个节点中存储的前置节点
while True: # 开启循环直到找到开始节点
if pre_node.name == start_node: # 退出条件:前置节点为开始节点
path.append(start_node) # 退出前将开始节点也加入路径,保证路径的完整性
break
else:
path.append(pre_node.name) # 不断将前置节点名称加入路径
pre_node = visited[pre_node.from_node] # 取出前置节点的前置节点,依次类推
path_len = len(path) - 1 # 获得完整路径后,长度即为节点个数-1
break
else:
visited[current_node.name] = current_node # 如果没有找到目标节点,将节点设为已访问,并将相邻节点加入搜索队列,继续找下去
for node_name in graph[current_node.name]: # 遍历相邻节点,判断相邻节点是否已经在搜索队列
if node_name not in name_search: # 如果相邻节点不在搜索队列则进行添加
search_queue.append(node(node_name, current_node.name))
name_search.append(node_name)
print('搜索完毕,最短路径为:', path[::-1], "长度为:", path_len) # 打印搜索结果
if __name__ == "__main__":
graph = dict() # 使用字典表示有向图
graph[1] = [3, 2]
graph[2] = [5]
graph[3] = [4, 7]
graph[4] = [6]
graph[5] = [6]
graph[6] = [8]
graph[7] = [8]
graph[8] = []
bfs(1, 8, graph) # 执行搜索
搜索结果
开始搜索...
待遍历节点: deque([1])
当前节点: 1 | 待遍历节点: deque([3, 2])
当前节点: 3 | 待遍历节点: deque([2, 4, 7])
当前节点: 2 | 待遍历节点: deque([4, 7, 5])
当前节点: 4 | 待遍历节点: deque([7, 5, 6])
当前节点: 7 | 待遍历节点: deque([5, 6, 8])
当前节点: 5 | 待遍历节点: deque([6, 8])
当前节点: 6 | 待遍历节点: deque([8])
当前节点: 8 | 搜索完毕,最短路径为: [1, 3, 7, 8] 长度为: 3
广度优先搜索的适用场景:只适用于深度不深且权值相同的图,搜索的结果为最短路径或者最小权值和。
深度优先搜索
深度优先搜索的遍历顺序为一条路径走到底然后回溯再走下一条路径,这种遍历方法很省内存但是不能一次性给出最短路径或者最优解。
用python实现深度优先算法只需要在广度的基础上将搜索队列改为搜索栈即可:
from collections import deque
from collections import namedtuple
def bfs(start_node, end_node, graph):
node = namedtuple('node', 'name, from_node')
search_stack = deque() # 这里当作栈使用
name_search = deque()
visited = {}
search_stack.append(node(start_node, None))
name_search.append(start_node)
path = []
path_len = 0
print('开始搜索...')
while search_stack:
print('待遍历节点: ', name_search)
current_node = search_stack.pop() # 使用栈模式,即后进先出,这是DFS的核心
name_search.pop()
if current_node.name not in visited:
print('当前节点: ', current_node.name, end=' | ')
if current_node.name == end_node:
pre_node = current_node
while True:
if pre_node.name == start_node:
path.append(start_node)
break
else:
path.append(pre_node.name)
pre_node = visited[pre_node.from_node]
path_len = len(path) - 1
break
else:
visited[current_node.name] = current_node
for node_name in graph[current_node.name]:
if node_name not in name_search:
search_stack.append(node(node_name, current_node.name))
name_search.append(node_name)
print('搜索完毕,路径为:', path[::-1], "长度为:", path_len) # 这里不再是最短路径,深度优先搜索无法一次给出最短路径
if __name__ == "__main__":
graph = dict()
graph[1] = [3, 2]
graph[2] = [5]
graph[3] = [4, 7]
graph[4] = [6]
graph[5] = [6]
graph[6] = [8]
graph[7] = [8]
graph[8] = []
bfs(1, 8, graph)
搜索结果
开始搜索...
待遍历节点: deque([1])
当前节点: 1 | 待遍历节点: deque([3, 2])
当前节点: 2 | 待遍历节点: deque([3, 5])
当前节点: 5 | 待遍历节点: deque([3, 6])
当前节点: 6 | 待遍历节点: deque([3, 8])
当前节点: 8 | 搜索完毕,路径为: [1, 2, 5, 6, 8] 长度为: 4
python的deque根据pop还是popleft可以当成栈或队列使用,DFS的能够很快给出解,但不一定是最优解。
深度优先搜索的适用场景: 针对深度很深或者深度不确定的图或者权值不相同的图可以适用DFS,优势在于节省资源,但想要得到最优解需要完整遍历后比对所有路径选取最优解。
python实现广度优先搜索和深度优先搜索的更多相关文章
- 总结A*,Dijkstra,广度优先搜索,深度优先搜索的复杂度比较
广度优先搜索(BFS) 1.将头结点放入队列Q中 2.while Q!=空 u出队 遍历u的邻接表中的每个节点v 将v插入队列中 当使用无向图的邻接表时,复杂度为O(V^2) 当使用有向图的邻接表时, ...
- 广度优先(bfs)和深度优先搜索(dfs)的应用实例
广度优先搜索应用举例:计算网络跳数 图结构在解决许多网络相关的问题时直到了重要的作用. 比如,用来确定在互联网中从一个结点到另一个结点(一个网络到其他网络的网关)的最佳路径.一种建模方法是采用无向图, ...
- DFS+BFS(广度优先搜索弥补深度优先搜索遍历漏洞求合格条件总数)--09--DFS+BFS--蓝桥杯剪邮票
题目描述 如下图, 有12张连在一起的12生肖的邮票.现在你要从中剪下5张来,要求必须是连着的.(仅仅连接一个角不算相连) 比如,下面两张图中,粉红色所示部分就是合格的剪取. 请你计算,一共有多少 ...
- 《算法笔记》8.1小节——搜索专题->深度优先搜索(DFS)
http://codeup.cn/contest.php 5972 这是递归的入门题,求全排列,第一种方法用STL中的函数next_permutation,可以很容易的实现.首先建立好数组,将需要全排 ...
- matlab练习程序(广度优先搜索BFS、深度优先搜索DFS)
如此经典的算法竟一直没有单独的实现过,真是遗憾啊. 广度优先搜索在过去实现的二值图像连通区域标记和prim最小生成树算法时已经无意识的用到了,深度优先搜索倒是没用过. 这次单独的将两个算法实现出来,因 ...
- 用Python实现广度优先搜索
图是一种善于处理关系型数据的数据结构,使用它可以很轻松地表示数据之间是如何关联的 图的实现形式有很多,最简单的方法之一就是用散列表 背景 图有两种经典的遍历方式:广度优先搜索和深度优先搜索.两者是相似 ...
- "《算法导论》之‘图’":深度优先搜索、宽度优先搜索(无向图、有向图)
本文兼参考自<算法导论>及<算法>. 以前一直不能够理解深度优先搜索和广度优先搜索,总是很怕去碰它们,但经过阅读上边提到的两本书,豁然开朗,马上就能理解得更进一步. 下文将会用 ...
- 【11】python 递归,深度优先搜索与广度优先搜索算法模拟实现
一.递归原理小案例分析 (1)# 概述 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! (2)# 写递归的过程 1.写出临界条件 2.找出这一次和上一次关系 3.假设 ...
- 常用算法2 - 广度优先搜索 & 深度优先搜索 (python实现)
1. 图 定义:图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合. 简单点的说:图由节点和边组成.一 ...
随机推荐
- node之post提交上传
post文件上传 multer 中间件 在node中 express为了性能考虑采用按需加载的方式,引入各种中间件来完成需求, 平时解析post上传数据时候,是用body-parse.但这个中间件有缺 ...
- ThinkPHP从零开始(一)安装和配置
序: 对PHP一无所知的我,将从这里从零开始. 1.下载与安装 ThinkPHP的下载: ThinkPHP中文站下载页面 有 核心版和完整版两种,由于不了解.所以我选择了完整版. WampSer ...
- BCB将RichEdit光标移到最后一行
int linecount=RichEdit1->Lines->Count; RichEdit1-> SelStart=SendMessage(RichEdit1-> Hand ...
- Codeforces 494C - Helping People
题意 有一个长度为 \(n\) 的数列 \(a\),有 \(m\) 个 操作,每个操作是给 \(a[l_i,r_i]\) 中的数都加一,一个操作有 \(p_i\) 的概率执行(否则不执行).一个性质是 ...
- 【Revit API】创建相机视角
在Revit中有一个相机功能可以以相机视角产生一个视图.一开始我在Revit2016的API文档中找关键词Camera,但是没什么收获. 其实这个相机功能的真正核心是创建透视视图:View3D.Cre ...
- spring data jpa createNativeQuery 错误 Unknown entity
springdatajpa本地查询的时候,报错:org.hibernate.MappingException: Unknown entity: com.hzxc.guesssong.model.Que ...
- AGC 018E.Sightseeing Plan——网格路径问题观止
原题链接 鸣谢:AGC 018E.Sightseeing Plan(组合 DP) 本蒟蒻认为,本题堪称网格路径问题观止. 因为涵盖了不少网格路径问题的处理方法和思路. 一句话题意: 给你三个矩形. 三 ...
- 洛谷P1155 双栈排序
这题什么毒瘤......之前看一直没思路,然后心说写个暴搜看能有多少分,然后就A了??! 题意:给你一个n排列,求它们能不能通过双栈来完成排序.如果能输出最小字典序方案. [update]这里面加了一 ...
- error while loading shared libraries: libmysqlcppconn.so.7: cannot open shared object file: No such file or directory
1. 即使libmysqlcppconn.so.7和与之相关存在,也报这个错误. 解决方法:临时添加LD_LIBRARY_PATH, 假使 libmysqlcppconn.so在/usr/local/ ...
- SQL记录-Linux CentOS配置ORACLE 12c
1.准备LIINX软件包 操作系统:centos7 虚拟机:VMware 12 JDK:1.8 数据库:oracle 12c 2.配置基础环境 2.1 部署虚拟机VM(过程略) 2.2 部署操作系统C ...