Rabbitmq -Publish_Subscribe模式- python编码实现
Let's quickly go over what we covered in the previous tutorials:
- A producer is a user application that sends messages.
- A queue is a buffer that stores messages.
- A consumer is a user application that receives messages.
channel.exchange_declare(exchange='logs',type='fanout')
Listing exchanges
To list the exchanges on the server you can run the ever useful rabbitmqctl:
$ sudo rabbitmqctl list_exchanges
Listing exchanges ...
logs fanout
amq.direct direct
amq.topic topic
amq.fanout fanout
amq.headers headers
...done.
In this list there are some amq.* exchanges and the default (unnamed) exchange. These are created by default, but it is unlikely you'll need to use them at the moment.
Nameless exchange
In previous parts of the tutorial we knew nothing about exchanges, but still were able to send messages to queues. That was possible because we were using a default exchange, which we identify by the empty string ("").
#简单的翻译下: 在前面的教程中我们没有指定exchange也能够发送消息到队列里面,那很有可能我们使用了默认的exchange
Recall how we published a message before:
channel.basic_publish(exchange='',routing_key='hello',body=message)
The exchange parameter(参数) is the the name of the exchange. The empty string denotes the default or nameless exchange: messages are routed to the queue with the name specified byrouting_key, if it exists.
# 这个exchange的参数是exchange的名字,这里没写为空的话代表着使用默认的exchange或者不可能命名的exchange。消息能够被路由到队列是因为使用 routing_key这个特殊的字段。
此时我们修改下代码
Now, we can publish to our named exchange instead:
channel.basic_publish(exchange='logs',routing_key='',body=message)
Temporary queues
As you may remember previously we were using queues which had a specified name (rememberhello and task_queue?). Being able to name a queue was crucial for us -- we needed to point the workers to the same queue. Giving a queue a name is important when you want to share the queue between producers and consumers.
# 简单的翻译下:你可能还记得我们前面在使用队列的时候指定了特殊的管道名字,这样命名是为了对我们有用,我们需要把那些运行的程序去指向同一个队列,命名一个队列非常重要当我们在生产者和消费者共享队列的时候
But that's not the case for our logger. We want to hear about all log messages, not just a subset of them. We're also interested only in currently flowing messages not in the old ones. To solve that we need two things.
Firstly, whenever we connect to Rabbit we need a fresh, empty queue. To do it we could create a queue with a random name, or, even better - let the server choose a random queue name for us. We can do this by not supplying the queue parameter to queue_declare:
result=channel.queue_declare()
Secondly, once we disconnect the consumer the queue should be deleted. There's an exclusive flag for that:
result=channel.queue_declare(exclusive=True)
Bindings

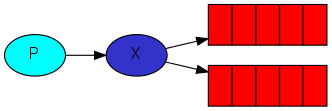
We've already created a fanout exchange and a queue. Now we need to tell the exchange to send messages to our queue. That relationship between exchange and a queue is called a binding
# translate:我们已经创建了扇出的交换器和一个队列,现在我们需要告诉这个交换器发送消息到我们队列,这时,交换器和队列他们之间两者的关系成为捆版
channel.queue_bind(exchange='logs',queue=result.method.queue)
From now on the logs exchange will append messages to our queue.
Listing bindings
You can list existing bindings using, you guessed it, rabbitmqctl list_bindings.
Putting it all together
The producer program, which emits log messages, doesn't look much different from the previous tutorial. The most important change is that we now want to publish messages to our logs exchange instead of the nameless one. We need to supply a routing_key when sending, but its value is ignored for fanout exchanges. Here goes the code for emit_log.py script:
# translate: 这个生产这程序,能够发送日志消息,看起来不不同于前面的教程,这个最重要的改变是我们现在想发送广播信息到我们的日志交换器而不是未命名的交换器,我们需要提供一个routeing_key当我们发送的时候,但是它的值是可以忽略的对于扇出交换器,这里能够得到这个代码:
github地址:https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/python/emit_log.py
#!/usr/bin/env pythonimport pika
import sys connection=pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel=connection.channel() channel.exchange_declare(exchange='logs',
type='fanout') message=' '.join(sys.argv[1:]) or"info: Hello World!"channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r"%message)
connection.close()
As you see, after establishing the connection we declared the exchange. This step is neccesary as publishing to a non-existing exchange is forbidden.
The messages will be lost if no queue is bound to the exchange yet, but that's okay for us; if no consumer is listening yet we can safely discard the message.The code for receive_logs.py:
# translate: 正如你所看到的,在建立连接后我们可以声明这个交换器,这一步的话广播到不存在的交换器是会被拒绝的,
这个信息会被丢失如果没有队列去限制这个交换器,但是这对我们来说是OK,如果没有消费者去监听的话,我们就可以安全的丢弃这个消息,这个代码如下:
The code for receive_logs.py:
#!/usr/bin/env pythonimport pika connection=pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel=connection.channel() channel.exchange_declare(exchange='logs',
type='fanout') result=channel.queue_declare(exclusive=True)
queue_name=result.method.queuechannel.queue_bind(exchange='logs',
queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') defcallback(ch, method, properties, body):
print(" [x] %r"%body) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
代码地址:https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/python/receive_logs.py
We're done. If you want to save logs to a file, just open a console and type:
$ python receive_logs.py > logs_from_rabbit.log
If you wish to see the logs on your screen, spawn a new terminal and run:
$ python receive_logs.py
And of course, to emit logs type:
$ python emit_log.py
Using rabbitmqctl list_bindings you can verify that the code actually creates bindings and queues as we want. With two receive_logs.py programs running you should see something like:
$ sudo rabbitmqctl list_bindings
Listing bindings ...
logs exchange amq.gen-JzTY20BRgKO-HjmUJj0wLg queue []
logs exchange amq.gen-vso0PVvyiRIL2WoV3i48Yg queue []
...done.
The interpretation of the result is straightforward: data from exchange logs goes to two queues with server-assigned names. And that's exactly what we intended.
To find out how to listen for a subset of messages, let's move on to tutorial 4
/YouDaoYunBiJi/qqEB3E1B35E56F6DBA5AE1D5AEEA1E4488/4d9107bcdece41e3a3150325be78ffac/exchanges.png)
Rabbitmq -Publish_Subscribe模式- python编码实现的更多相关文章
- Rabbitmq -Routeing模式- python编码实现
(using the pika 0.10.0 Python client) In the previous tutorial we built a simple logging system. We ...
- 转--python 编码规范
编程规范 1.1. 命名规范 1.1.1. [强制] 命名不能以下划线或美元符号开始和结尾 反例: name / __name / $Object / name / name$ / Object$ 1 ...
- Python编码(encode)和解码(Decode)常见的两个错误
项目地址:https://git.io/pytips 0x07 和 0x08 分别介绍了 Python 中的字符串类型(str)和字节类型(byte),以及 Python 编码中最常见也是最顽固的两个 ...
- 使用rabbitmq rpc 模式
服务器端 安装 ubuntu 16.04 server 安装 rabbitmq-server 设置 apt 源 curl -s https://packagecloud ...
- VS2013+PTVS,python编码问题
1.调试,input('中文'),乱码2.调试,print('中文'),正常3.不调试,input('中文'),正常4.不调试,print('中文'),正常 页面编码方式已经加了"# -- ...
- (转载) 浅谈python编码处理
最近业务中需要用 Python 写一些脚本.尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息. 很快,我就遇到了异常: UnicodeEncodeError: ...
- Python 编码简单说
先说说什么是编码. 编码(encoding)就是把一个字符映射到计算机底层使用的二进制码.编码方案(encoding scheme)规定了字符串是如何编码的. python编码,其实就是对python ...
- Python之路3【知识点】白话Python编码和文件操作
Python文件头部模板 先说个小知识点:如何在创建文件的时候自动添加文件的头部信息! 通过:file--settings 每次都通过file--setings打开设置页面太麻烦了!可以通过:View ...
- python编码规范
python编码规范 文件及目录规范 文件保存为 utf-8 格式. 程序首行必须为编码声明:# -*- coding:utf-8 -*- 文件名全部小写. 代码风格 空格 设置用空格符替换TAB符. ...
随机推荐
- 深入理解计算机系统(4.1)---X86的孪生兄弟,Y86指令体系结构
引言 各位猿友们好,计算机系统系列很久没更新了,实在是抱歉之极.新的一年,为了给计算机系统系列添加一些新的元素,LZ将其更改为书的原名<深入理解计算机系统>.这本书非常厚,而且难度较高,L ...
- window 运行指令(1)
添加或删除程序 appwiz.cpl 管理工具 control admintools Bluetooth文件传送向导 fsquirt 计算器 calc 证书管理控制台 certmgr.msc 字符映射 ...
- Codeforces Round #359(div 2)
A:= v = B:^ w ^ C:一天n个小时,一个小时m分(n,m十进制),一个手表有两部分,左边表示时,右边表示分,但都是7进制,而且手表上最多只能有7个数字且数字不能重复,现在要你算出能正确表 ...
- P值,“差异具有显著性”和“具有显著差异”
P值是论文中最常用的一个统计学指标,可是其误用.解释错误的现象却很常见.因此,很有必要说明p值的意义.用法及常见错误. P值指的是比较的两者的差别是由机遇所致的可能性大小.P值越小,越有理由认 ...
- ASP.NET 问题集锦
[1]解决错误:从客户端(Content="<p>测试</p>")中检测到有潜在危险的 Request.Form 值 .NetFrameWork ...
- Android闹钟开发与展示Demo
前言: 看过了不少安卓闹钟开发的例子,都是点到为止,都不完整,这次整一个看看. 一.闹钟的设置不需要数据库,但是展示闹钟列表的时候需要,所以需要数据库: public class MySQLiteOp ...
- 【jQuery EasyUI系列】创建CRUD数据网格
在上一篇中我们使用对话框组件创建了CRUD应用创建和编辑用户信息.本篇我们来创建一个CRUD数据网格DataGrid 步骤1,在HTML标签中定义数据网格(DataGrid) <table id ...
- [Google Guava]学习--缓存cache
适用性 缓存在很多情况下非常实用.例如,计算或检索一个值的代价很高,并且对同样的输入需要不止一次获取值的时候,就应当考虑使用缓存. Guava Cache与ConcurrentMap很相似,但也不完全 ...
- ASP.NET MVC 5 入门教程 (4) View和ViewBag
文章来源: Slark.NET-博客园 http://www.cnblogs.com/slark/p/mvc-5-get-started-view.html 上一节:ASP.NET MVC 5 入门教 ...
- iOS开发小技巧--判断控件是否显示在当前窗口
一.判断控件是否显示在当前窗口,需要同时满足一下条件: 控件的Hidden = NO; 控件的Alpha >= 0.01; self.window = keyWindow; 主窗口的bounds ...