R语言中聚类确定最佳K值之Calinsky criterion
Calinski-Harabasz准则有时称为方差比准则 (VRC),它可以用来确定聚类的最佳K值。Calinski Harabasz 指数定义为:
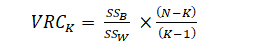
其中,K是聚类数,N是样本数,SSB是组与组之间的平方和误差,SSw是组内平方和误差。因此,如果SSw越小、SSB越大,那么聚类效果就会越好,即Calinsky criterion值越大,聚类效果越好。
1.下载permute、lattice、vegan包
install.packages(c("permute","lattice","vegan"))
2.引入permute、lattice、vegan包
library(permute)
library(lattice)
library(vegan)
3.读取数据
data <- read.csv("data/data.csv")
4.计算最佳K值
fit <- cascadeKM(data,,,iter=,criterion="calinski")
calinski.best <- as.numeric(which.max(fit$results[,]))
5.图片保存
png(file="data/calinskibest.png")
plot(fit, sortg = TRUE, grpmts.plot = TRUE)
dev.off()
6.截图

封装DetermineClustersNumHelper.R类
# ============================
# 确定最佳聚类K值 #
# ============================ # 引入包库
library(permute)
library(lattice)
library(vegan) # 获取最佳K值函数
get_best_calinski <- function(file_name){
# 获取故障数据
data <- read.csv(paste("data/km/",file_name,".csv",sep=""),header = T)
# 计算
fit <- cascadeKM(data,,,iter=,criterion="calinski")
calinski.best <- as.numeric(which.max(fit$results[,]))
# 保存图片
png(file=paste("data/km/",file_name,calinski.best,".png",sep=""))
plot(fit, sortg = TRUE, grpmts.plot = TRUE)
dev.off()
} # ========================================================================== # For example
#file_list <- array(c("failure_data_normalization","failure_normal_data_normalization"))
#for(file in file_list){
# # 调用函数
# get_best_calinski(file)
#} # ==========================================================================
R语言中聚类确定最佳K值之Calinsky criterion的更多相关文章
- R语言中的特殊值 NA NULL NaN Inf
这几个都是R语言中的特殊值,都是R的保留字, NA:Not available 表示缺失值 用 is.na() 来判断是否为缺失值 NULL:表示空值,即没有内容 用 is.null() 来判 ...
- R语言中样本平衡的几种方法
R语言中样本平衡的几种方法 在对不平衡的分类数据集进行建模时,机器学习算法可能并不稳定,其预测结果甚至可能是有偏的,而预测精度此时也变得带有误导性.在不平衡的数据中,任一算法都没法从样本量少的类中获取 ...
- R语言学习笔记1——R语言中的基本对象
R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发(也因此称为R),现在由“R开发核心 ...
- 【R语言入门】R语言中的变量与基本数据类型
说明 在前一篇中,我们介绍了 R 语言和 R Studio 的安装,并简单的介绍了一个示例,接下来让我们由浅入深的学习 R 语言的相关知识. 本篇将主要介绍 R 语言的基本操作.变量和几种基本数据类型 ...
- 机器学习:R语言中如何使用最小二乘法
详细内容见上一篇文章:http://www.cnblogs.com/lc1217/p/6514734.html 这里只是介绍下R语言中如何使用最小二乘法解决一次函数的线性回归问题. 代码如下:(数据同 ...
- R语言中的数据处理包dplyr、tidyr笔记
R语言中的数据处理包dplyr.tidyr笔记 dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了 ...
- R语言中的四类统计分布函数
R语言中提供了四类有关统计分布的函数(密度函数,累计分布函数,分位函数,随机数函数).分别在代表该分布的R函数前加上相应前缀获得(d,p,q,r).如: 1)正态分布的函数是norm,命令dnorm( ...
- R语言中的字符处理
R语言中的字符处理 (2011-07-10 22:29:48) 转载▼ 标签: r语言 字符处理 字符串 连接 分割 分类: R R的字符串处理能力还是很强大的,具体有base包的几个函数和strin ...
- R 语言中的数据结构
基本数据类型 6种 numaric 如 12, 12.4 integer 如 2L,0L complex 包含实数和虚数 如 3+2i character 要用双引号或者单引号包括起来 如 & ...
随机推荐
- 动态更新highcharts数据
<!doctype html> <html> <head> <script type="text/javascript" src=&quo ...
- location ^~ /images/
} location ^~ /images/ { root /static/; } #当匹配到/images/ 开头的uri 会把网站定位到/static/下,并且不在向下继续匹配!!! 注意: ^~ ...
- libcpmt.lib (xxx.obj) LNK2038: mismatch detected for 'RuntimeLibrary': value 'MT_StaticRelease' doesn't match value 'MD_DynamicRelease' in XXX.obj
问题描述: 这样的,我写了个NString类,然后用的VS2013的命令行编译的(NMAKE.exe),并用LNK.exe打包成了NString.lib 然后后来我在VS2013里面建了一个proje ...
- js to json字符串
var last=obj.toJSONString(); //将JSON对象转化为JSON字符 或者 var last=JSON.stringify(obj); //将JSON对象转化为JSON字符
- background-origin:规定 background-position 属性相对于什么位置来定位
background-origin:border-box;此时设置background-size:contain; 根据容器的边框定位 例如:容器的盒模型如下:设置了padding:20px;bord ...
- 分享8个常用的jQuery焦点图插件
现在web网页jquery应用越来越广泛,目前几乎每一个WEB项目都在使用jQuery,因为jQuery插件实在太丰富,尤其是一些图片滑块插件和jQuery焦点图插件,更是多如牛毛,很多初学者只需稍微 ...
- Xml解析之PULL解析 例1
<?xml version="1.0" encoding="UTF-8"?> <persons> <person id=" ...
- 利用MapReduce实现数据去重
数据去重主要是为了利用并行化的思想对数据进行有意义的筛选. 统计大数据集上的数据种类个数.从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重. 示例文件内容: 此处应有示例文件 设计思路 数据 ...
- hive中关键字作为列名的方法
hive中有很多关键字,直接作为列名,会出错的 例如 下面 user就是关键字,作为字段时报以下错误. 解决方案: 使用·· (ESC下面的那个键,点号)两个符号包裹即可.
- Storm手写WordCount
建立一个maven项目,在pom.xml中进行如下配置: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:x ...