Flume在企业大数据仓库架构中位置及功能
Flume在企业大数据仓库架构中位置及功能
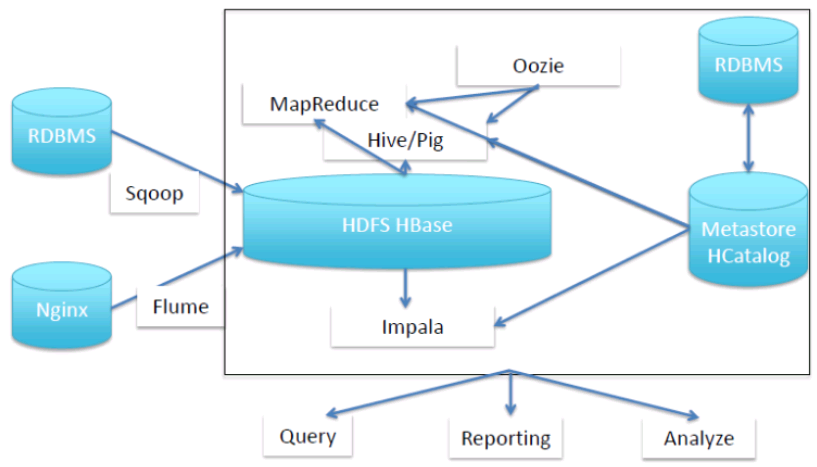
数据仓库架构
1、如下图所示,外部数据中,关系型数据库导入到HDFS用sqoop,由Nginx产生的文件实时监控用Flume获得。
在HDFS或Hbase中,如果要进行实时查询用Impala(内存),如果是分析可以用Hive,Mapreduce分析。用Oozie来调用工作流执行任务。
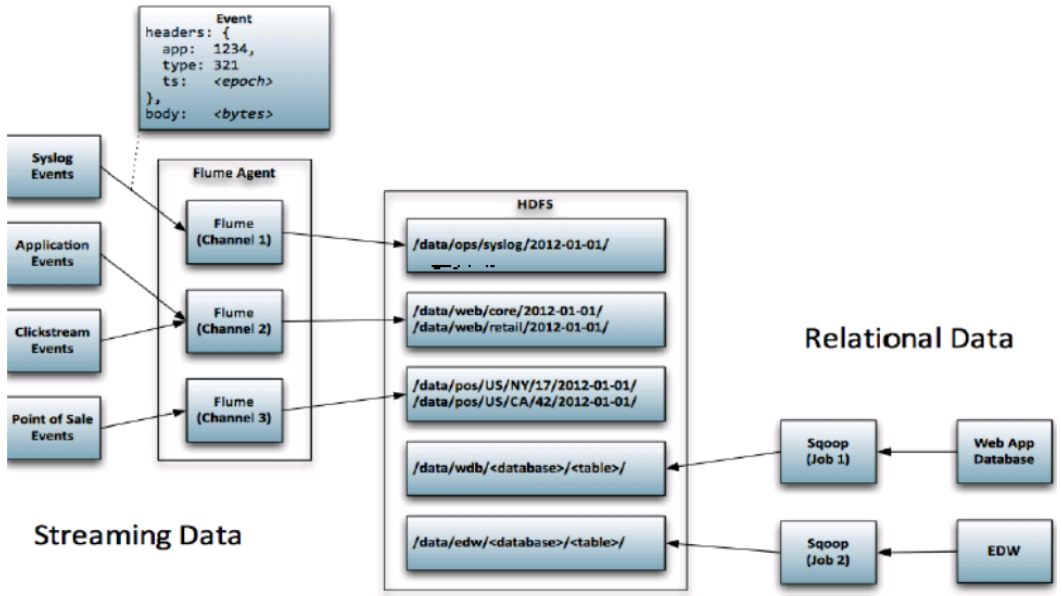
2、左边是数据的来源:系统日志文件,应用文件(应用系统收集APP产生的日志),点击流(点击产生的日志),销售点(订单信息)。通过Flume收集然后给HDFS存储。
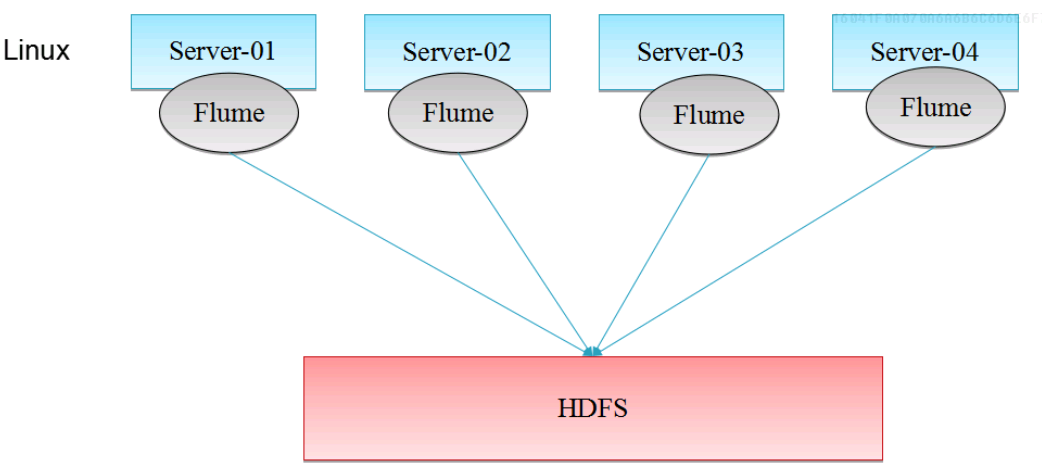
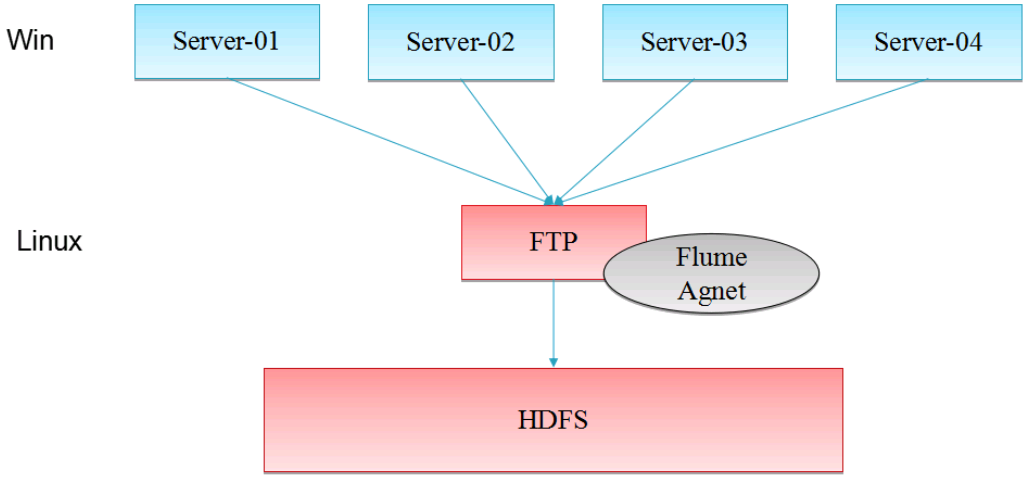
3、Flume在企业中的做法
Flume在企业大数据仓库架构中位置及功能的更多相关文章
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
- 关于C#三层架构中的“分页”功能
新手上路,请多指教! 今天将分页功能实现了,要特别感谢坐在前面的何同学的指点,不胜感谢!功能的实现采用了三层架构的方式实现该功能,简述如下: 界面: DAL层有两个方法:“当前所在页”和“总页数” 这 ...
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 企业集群架构-03-NFS
NFS 目录 NFS NFS基本概述 NFS应用场景 NFS实现原理 NFS总结 NFS服务端安装 环境准备 服务端安装NFS 服务端NFS配置 服务端开机自启 服务端验证配置 NFS客户端挂载卸载 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上
一.数据仓库架构 二.flume收集数据存储到hdfs 文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hd ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- 深入理解大数据架构之——Lambda架构
目录 传统系统的问题 Lambda架构简介 Lambda架构关键特性 数据系统的本质 Lambda的三层架构 Lambda架构组件选型 总结 原文链接:https://jiang-hao.com/ar ...
随机推荐
- PHP 支持8种基本的数据类型。
四种标量类型:boolean (布尔型):这是最简单的类型,只有两种取值,可以为 TRUE/true 或 FALSE/false ,不区分大小写.详细请查看:PHP布尔类型(boolean)integ ...
- LeetCode_Search in Rotated Sorted Array
题目: Suppose a sorted array is rotated at some pivot unknown to you beforehand. (i.e., 0 1 2 4 5 6 7 ...
- golang 中的定时器(timer),更巧妙的处理timeout
今天看到kite项目中的一段代码,发现挺有意思的. // generateToken returns a JWT token string. Please see the URL for detail ...
- ovn-kubernetes执行流程概述
Master部分 1.master初始化 以node name创建一个distributed logical router 创建两个load balancer用于处理east-west traffic ...
- Flask用Flask-SQLAlchemy连接MySQL
安装 pip3 install Flask-SQLAlchemy 测试环境目录结构 settings.py DIALECT = 'mysql' DRIVER = 'pymysql' USERNAME ...
- Linux Tomcat部署常用命令
Linux Tomcat部署常用命令 1.连接服务器 2.进入webapps目录: cd /usr/local/tomcat8080/webapps/ 3.上传文件(war包等):rz 4.删除文件 ...
- BlueZ
一.BlueZ在ubuntu PC上的基础应用 1.bluez的安装及基本功能 dong@ubuntu:~/bluez$ lsbluez-5.47.tar.xz SPP-loopback.pydo ...
- 跟我学Makefile(一)
1.首先,把源文件编译生成中间代码文件,Windows下.obj文件,unix下.o文件,即Object File.这个动作叫编译(compile) 把大量的Object File合并执行文件,叫做链 ...
- Java网络通信基础编程
一.同步阻塞方式(BIO) 方式一: 服务器端(Server): package com.ietree.basicskill.socket.mode1; import java.io.IOExcept ...
- SpringBoot简介及第一个应用
一.Spring时代变换 1. Spring1.x 时代 Spring初代都是通过xml文件配置bean,随着项目的不断扩大,繁琐的xml配置,混乱的依赖关系,难用的bean装配方式,由此衍生了spr ...