numpy生成随机数
如果你想说,我不想知道里面的逻辑和实现方法,只想要python生成随机数的代码,请移步本文末尾,最简单的demo帮你快速获取实现方法。
先开始背景故事说明:
在数据分析中,数据的获取是第一步,numpy.random 模块提供了非常全的自动产生数据API,是学习数据分析的第一步。
总体来说,numpy.random模块分为四个部分,对应四种功能:
1. 简单随机数: 产生简单的随机数据,可以是任何维度
2. 排列:将所给对象随机排列
3. 分布:产生指定分布的数据,如高斯分布等
4. 生成器:种随机数种子,根据同一种子产生的随机数是相同的
以下是详细内容以及代码实例:(以下代码默认已导入numpy:import numpy as np )
1. 生成器
电脑产生随机数需要明白以下几点:
(1)随机数是由随机种子根据一定的计算方法计算出来的数值。所以,只要计算方法一定,随机种子一定,那么产生的随机数就不会变。
(2)只要用户不设置随机种子,那么在默认情况下随机种子来自系统时钟(即定时/计数器的值)
(3)随机数产生的算法与系统有关,Windows和Linux是不同的,也就是说,即便是随机种子一样,不同系统产生的随机数也不一样。
numpy.random 设置种子的方法有:
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| RandomState | 定义种子类 | RandomState是一个种子类,提供了各种种子方法,最常用seed |
| seed([seed]) | 定义全局种子 | 参数为整数或者矩阵 |
代码示例:
np.random.seed(1234) #设置随机种子为1234- 1
2. 简单随机数
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| rand(d0, d1, …, dn) | 产生均匀分布的随机数 | dn为第n维数据的维度 |
| randn(d0, d1, …, dn) | 产生标准正态分布随机数 | dn为第n维数据的维度 |
| randint(low[, high, size, dtype]) | 产生随机整数 | low:最小值;high:最大值;size:数据个数 |
| random_sample([size]) | 在[0,1)内产生随机数 | size:随机数的shape,可以为元祖或者列表,[2,3]表示2维随机数,维度为(2,3) |
| random([size]) | 同random_sample([size]) | 同random_sample([size]) |
| ranf([size]) | 同random_sample([size]) | 同random_sample([size]) |
| sample([size])) | 同random_sample([size]) | 同random_sample([size]) |
| choice(a[, size, replace, p]) | 从a中随机选择指定数据 | a:1维数组 size:返回数据形状 |
| bytes(length) | 返回随机位 | length:位的长度 |
代码示例
(1) np.random.rand(2,3) #产生2行三列均匀分布随机数组
Out[7]:
array([[ 0.35369993, 0.0086019 , 0.52609906],
[ 0.31978928, 0.27069309, 0.21930115]])
(2)In [8]: np.random.randn(3,3) #三行三列正态分布随机数据
Out[8]:
array([[ 2.29864491, 0.52591291, -0.80812825],
[ 0.37035029, -0.07191693, -0.76625886],
[-1.264493 , 1.12006474, -0.45698648]])
(3)In [9]: np.random.randint(1,100,[5,5]) #(1,100)以内的5行5列随机整数
Out[9]:
array([[87, 69, 3, 86, 85],
[13, 49, 59, 7, 31],
[19, 96, 70, 10, 71],
[91, 10, 52, 38, 49],
[ 8, 21, 55, 96, 34]])
(4)In [10]: np.random.random(10) #(0,1)以内10个随机浮点数
Out[10]:
array([ 0.33846136, 0.06517708, 0.41138166, 0.34638839, 0.41977818,
0.37188863, 0.2508949 , 0.89923638, 0.51341298, 0.71233872])
(5)In [11]: np.random.choice(10) #[0,10)内随机选择一个数
Out[11]: 7- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3. 分布
numpy.random模块提供了产生各种分布随机数的API:
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| beta(a, b[, size]) | 贝塔分布样本,在 [0, 1]内。 | |
| binomial(n, p[, size]) | 二项分布的样本。 | |
| chisquare(df[, size]) | 卡方分布样本。 | |
| dirichlet(alpha[, size]) | 狄利克雷分布样本。 | |
| exponential([scale, size]) | 指数分布 | |
| f(dfnum, dfden[, size]) | F分布样本。 | |
| gamma(shape[, scale, size]) | 伽马分布 | |
| geometric(p[, size]) | 几何分布 | |
| gumbel([loc, scale, size]) | 耿贝尔分布。 | |
| hypergeometric(ngood, nbad, nsample[, size]) | 超几何分布样本。 | |
| laplace([loc, scale, size]) | 拉普拉斯或双指数分布样本 | |
| logistic([loc, scale, size]) | Logistic分布样本 | |
| lognormal([mean, sigma, size]) | 对数正态分布 | |
| logseries(p[, size]) | 对数级数分布。 | |
| multinomial(n, pvals[, size]) | 多项分布 | |
| multivariate_normal(mean, cov[, size]) | 多元正态分布。 | |
| negative_binomial(n, p[, size]) | 负二项分布 | |
| noncentral_chisquare(df, nonc[, size]) | 非中心卡方分布 | |
| noncentral_f(dfnum, dfden, nonc[, size]) | 非中心F分布 | |
| normal([loc, scale, size]) | 正态(高斯)分布 | |
| pareto(a[, size]) | 帕累托(Lomax)分布 | |
| poisson([lam, size]) | 泊松分布 | |
| power(a[, size]) | Draws samples in [0, 1] from a power distribution with positive exponent a - 1. | |
| rayleigh([scale, size]) | Rayleigh 分布 | |
| standard_cauchy([size]) | 标准柯西分布 | |
| standard_exponential([size]) | 标准的指数分布 | |
| standard_gamma(shape[, size]) | 标准伽马分布 | |
| standard_normal([size]) | 标准正态分布 (mean=0, stdev=1). | |
| standard_t(df[, size]) | Standard Student’s t distribution with df degrees of freedom. | |
| triangular(left, mode, right[, size]) | 三角形分布 | |
| uniform([low, high, size]) | 均匀分布 | |
| vonmises(mu, kappa[, size]) | von Mises分布 | |
| wald(mean, scale[, size]) | 瓦尔德(逆高斯)分布 | |
| weibull(a[, size]) | Weibull 分布 | |
| zipf(a[, size]) | 齐普夫分布 |
代码示例
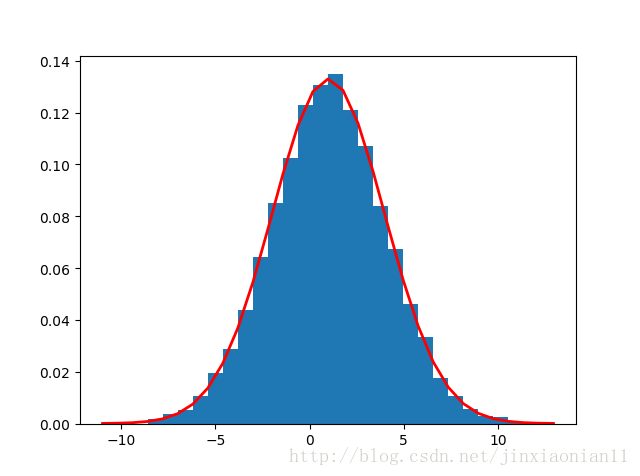
(1)正态分布
import numpy as np
import matplotlib.pyplot as plt
mu = 1 #期望为1
sigma = 3 #标准差为3
num = 10000 #个数为10000
rand_data = np.random.normal(mu, sigma, num)
count, bins, ignored = plt.hist(rand_data, 30, normed=True)
plt.plot(bins, 1/(sigma * np.sqrt(2 * np.pi)) *np.exp( - (bins - mu)**2 / (2 * sigma**2)), linewidth=2, color='r')
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
得到图像:
4. 排列
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| shuffle(x) | 打乱对象x(多维矩阵按照第一维打乱) | 矩阵或者列表 |
| permutation(x) | 打乱并返回该对象(多维矩阵按照第一维打乱) | 整数或者矩阵 |
代码示例
(1)正态分布
import numpy as np
rand_data = np.random.randint(1, 10, (3, 4))
print(rand_data)
np.random.shuffle(rand_data)
print(rand_data)
out:
[[4 4 4 8]
[5 6 8 2]
[1 7 6 6]]
[[4 4 4 8]
[1 7 6 6]
[5 6 8 2]]
(按照行打乱了,也就是交换了行)numpy生成随机数的更多相关文章
- 【转载】python 模块 - random生成随机数模块
随机数种子 要每次产生随机数相同就要设置种子,相同种子数的Random对象,相同次数生成的随机数字是完全相同的: random.seed(1) 这样random.randint(0,6, (4,5)) ...
- numpy生成随机数组
python想要生成随机数的话用使用random库很方便,不过如果想生成随机数组的话,还是用numpy更好更强大一点. 生成长度为10,在[0,1)之间平均分布的随机数组: rarray=numpy. ...
- tensorflow 生成随机数 tf.random_normal 和 tf.random_uniform 和 tf.truncated_normal 和 tf.random_shuffle
____tz_zs tf.random_normal 从正态分布中输出随机值. . <span style="font-size:16px;">random_norma ...
- tensorflow生成随机数的操作 tf.random_normal & tf.random_uniform & tf.truncated_normal & tf.random_shuffle
tf.random_normal 从正态分布输出随机值. random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name ...
- Python中生成随机数
目录 1. random模块 1.1 设置随机种子 1.2 random模块中的方法 1.3 使用:生成整形随机数 1.3 使用:生成序列随机数 1.4 使用:生成随机实值分布 2. numpy.ra ...
- 用量子计算模拟器ProjectQ生成随机数,并用pytest进行单元测试与覆盖率测试
技术背景 本文中主要包含有三个领域的知识点:随机数的应用.量子计算模拟产生随机数与基于pytest框架的单元测试与覆盖率测试,这里先简单分别介绍一下背景知识. 随机数的应用 在上一篇介绍量子态模拟采样 ...
- .Net使用system.Security.Cryptography.RNGCryptoServiceProvider类与System.Random类生成随机数
.Net中我们通常使用Random类生成随机数,在一些场景下,我却发现Random生成的随机数并不可靠,在下面的例子中我们通过循环随机生成10个随机数: ; i < ; i++) { Rando ...
- DotNet生成随机数的一些方法
在项目开发中,一般都会使用到“随机数”,但是在DotNet中的随机数并非真正的随机数,可在一些情况下生成重复的数字,现在总结一下在项目中生成随机数的方法. 1.随机布尔值: /// <summa ...
- Oracle中生成随机数的函数(转载)
在Oracle中的DBMS_RANDOM程序包中封装了一些生成随机数和随机字符串的函数,其中常用的有以下两个: DBMS_RANDOM.VALUE函数 该函数用来产生一个随机数,有两种用法: 1. 产 ...
随机推荐
- 【CentOS6.5】安装nginx报错:No package nginx available. Error: Nothing to do
今天在给centos6.5安装nginx时候,提示报错No package nginx available. Error: Nothing to do, 后来百度一下,说缺少EPEL(epel是社区强 ...
- (一)《Spring实战》——Spring核心
<Spring实战>(第4版) 第一章:Spring之旅 1. 简化Java开发 为了降低Java开发的复杂性,Spring采取了以下4种关键策略: 基于POJO的轻量级和最小侵入性编程: ...
- Linux下查看磁盘挂载的三种方法
Linux下查看磁盘挂载的三种方法 2009-06-05 23:17 好久没有更新日志了,呵呵.不是没有要写的东东.实在抽不出时间来写,要准备公司的考试呢,C++考试.已经有七个月没有写C++代码了, ...
- 温故而知新 js 的错误处理机制
// 在函数块的try中return,会直接成为函数的return值 function test() { try { alrt(123) return 'success' } catch(err) { ...
- Python 爬虫 去掉网页注释,去掉网页注释
在爬虫中,我们遇到了网页注释的问题,这些内容,第一,耗费内存资源,第二,在解析网页的时候,不易匹配出来信息.那么我们该如何去掉他们呢??? 我们可以去使用正则去过滤掉他们 方法如下 result = ...
- CentOS 6.4 yum安装chrome
CentOS 6.4安装chrome浏览器 vim /etc/yum.repos.d/CentOS-Base.repo 根据你的系统增加一个节点 32-bit [google] name=Google ...
- Linux下磁盘管理命令df与du
Linux下磁盘管理命令df与du 对磁盘进行查看和控制的两个linux命令,df和du. 一.du命令 首先看一下du的help说明: [root@misdwh opt]# du --help ...
- AESDK关于AEFX_CLR_STRUCT的用处
主要是在初始化UI值的时候遇到问题,一直报错 但确实没有用到ui_width,ui_height...,仔细检查例子工程发现,少了一个AEFX_CLR_STRUCT宏 AEFX_CLR_STRUCT其 ...
- Linux系统CPU频率调整工具使用
现在的CPU耗电很大,按需调节CPU频率对普通桌面及移动设备节能有重要的意义,目前多数Linux发行版都已经默认启用了这个功能,但在一些像数据库,集群系统等特别需要CPU高性能的服务器环境中,Linu ...
- js生成二维码的jquery组件–qrcode
js生成二维码的jquery组件–qrcode 2015/01/30 / 2508 VIEWS / JAVASCRIPT, JQUERY 有一些耗cpu的计算,完全可以在客户端上计算,比如生成二维码. ...