【mysql】- 索引简介篇
简介
- 我们都知道
mysql使用存储引擎的是InnoDB,InnoDB使用的索引的对应的数据结构是B+树
结构图:
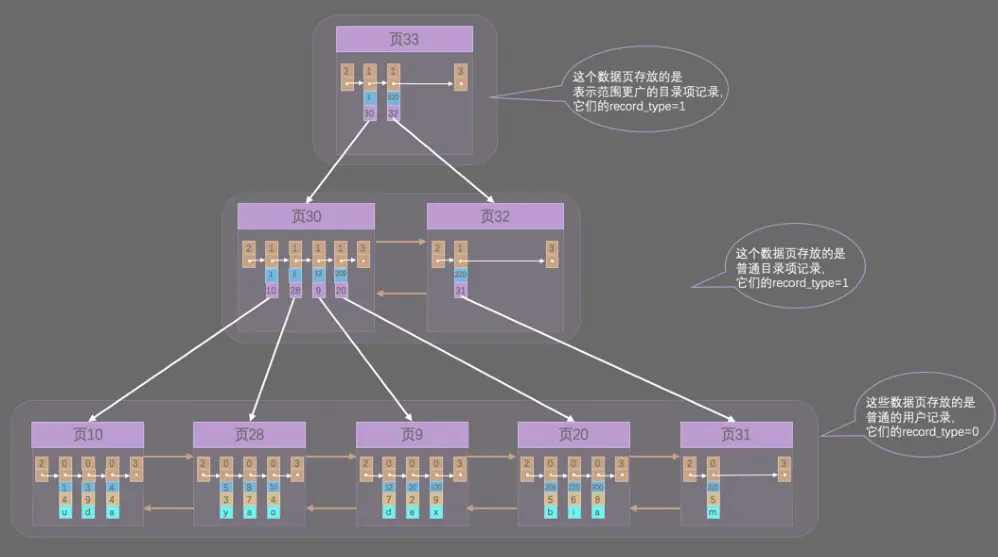
- 如上图所示,我们实际用户记录是存放在
B+树的最底层的节点上,这些节点也被称为叶子节点或者叶节点,其余用了存放目录项的节点称为非叶子节点或者内节点,最上边的节点为根节点。 InnoDB是使使用页来作为管理理存储空间的基本单位,也就是最多能保证16KB的连续存储空间,而随着表中记录数量量的增多,需要非常大的连续的存储空间才能把所有的目录项都放下,这对记录数量非常多的表是不现实的目录项两个列是主键和页号,与用户记录差不多,为了和用户记录进行区分,我们把这些用于表示目录项的记录称为目录项记录,区分方法为:- 通过记录头信息的
record_type属性:- 0:普通用户记录
- 1:目录项记录
- 2:最小记录
- 3:最大记录
- 通过记录头信息的
- 其设计者规定了最下边的那层,也就是存放记录的那层为第
0层,之后依次往上加。 - 现在以查找主键为
20的记录为例,采用二分法进行数据查询- 首先到存储
目录项记录的页,也就是页33中通过二分法快速定位到对应的目录项,因为1<20<320,所以定位到对应记录所在的页就是30; - 此时
12<20<209,所以定位到对应的记录所在的页就是页9; - 再到存储用户记录的
页9中根据二分法快速定位到主键值为20的用户记录。
- 首先到存储
扩展,为什么不用
B树,而采用B+树呢?
- 根据
B树的特点是每个节点都是存储记录的,那么就会存在一个问题,假如同样的一个深度的树,B树会比B+树的页要大很多,同样一页16k的数据,加载B+树的记录的范围会比B树的范围要大,那么磁盘IO的操作次数显然是B树要更多一些。
索引的分类
- 聚簇索引
- 使用用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
- 页内的记录是按照主键的大小顺序排成一个单向链表。
- 各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
- 存放目录项记录的页分为不不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
B+树的叶子节点存储的是完整的用户记录。
- 使用用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
大家有木有发现,上边介绍的
聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行行排序的。那如果我们想以别的列列作为搜索条件该咋办呢?难道只能从头到尾沿着链表依次遍历记录么?此时便有了二级索引。
- 二级索引(辅助索引)
- 如图
- 我们可以多建几棵
B+树,不不同的B+树中的数据采用不不同的排序规则。 - 这个
B+树与上边介绍的聚簇索引有几处不不同:- 使用记录
c2列的大小进行行记录和页的排序,这包括三个方面的含义:- 页内的记录是按照
c2列的大小顺序排成一个单向链表。 - 各个存放用户记录的页也是根据页中记录的
c2列大小顺序排成一个双向链表。 - 存放目录项记录的页分为不不同的层次,在同一层次中的页也是根据页中目录项记录的
c2列大小顺序排成一个双向链表。
- 页内的记录是按照
B+树的叶子节点存储的并不不是完整的用户记录,而只是c2列 +主键这两个列列的值。- 目录项记录中不不再是
主键+页号的搭配,而变成了了c2列+页号的搭配。
- 使用记录
- 以查找
c2列的值为4的记录为例,查找过程如下:- 确定
目录项记录页- 根据
根页面,也就是页44,可以快速定位到目录项记录所在的页为页42(因为 2 <4 < 9 )。
- 根据
- 通过
目录项记录页确定用户记录真实所在的页。- 在
页42中可以快速定位到实际存储用户记录的页,但是由于c2列列并没有唯一性约束,所以c2列列值为4的记录可能分布在多个数据页中,又因为2 < 4 ≤ 4,所以确定实际存储用户记录的页在页34和页35中。
- 在
- 在真实存储用户记录的页中定位到具体的记录。
- 到
页34和页3中定位到具体的记录。
- 到
- 但是这个
B+树的叶子节点中的记录只存储了c2和c1(也就是主键)两个列,所以我们必须再根据主键值去聚簇索引中再查找一遍完整的用户记录。
- 确定
- 我们可以多建几棵
上面的操作其实就是一个
回表,整个完成的查找需要用到2棵B+树。那为什么需要回表操作呢?直接把完整的用户记录放到叶子节点 不不就好了了么?
- 原因:
- 太占用地方,相当于每建立一棵
B+树都需要把所有的用户记录再都拷贝一遍,这就有点太浪费存储空间了了
联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列列建立索引,比方说我们想让
B+树按照c2和c3列的大小进行排序,这个包含两层含义:- 先把各个记录和页按照
c2列进行排序。 - 在记录的
c2列列相同的情况下,采用c3列进行排序。
示意图如下:
- 先把各个记录和页按照
如图所示,我们需要注意一下几点:
- 每条目录项记录都由
c2、c3、页号这三个部分组成,各条记录先按照c2列列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序。 B+树叶子节点处的用户记录由c2、c3和主键c1列组成。
- 每条目录项记录都由
千万要注意一点,以
c2和c3列的大小为排序规则建立的B+树称为联合索引,它的意思与分别为c2和c3列分别建立索引的表述是不不同的,不不同点如下:- 建立
联合索引只会建立如上图一样的1棵B+树。 - 为
c2和c3列分别建立索引会分别以c2和c3列的大小为排序规则建立2棵B+树。
- 建立
总结:
- 1.对于
InnoDB存储引擎来说,在单个页中查找某条记录分为两种情况:- 以主键为搜索条件,可以使用
Page Directory通过二分法快速定位相应的用户记录。 - 以其他列列为搜索条件,需要按照记录组成的单链表依次遍历各条记录。
- 以主键为搜索条件,可以使用
- 2.没有索引的情况下,不不论是以主键还是其他列列作为搜索条件,只能沿着页的双链表从左到右依次遍历各个页。
- 3.
InnoDB存储引擎的索引是一棵B+树,完整的用户记录都存储在B+树第0层的叶子节点,其他层次的节点都属于内节点 ,内节点里存储的是目录项记录 。 InnoDB 的索引分为两大种:- 聚簇索引
- 以主键值的大小为页和记录的排序规则,在叶子节点处存储的记录包含了表中所有的列。
- 二级索引
- 以自定义的列的大小为页和记录的排序规则,在叶子节点处存储的记录内容是
列+主键。
- 以自定义的列的大小为页和记录的排序规则,在叶子节点处存储的记录内容是
- 聚簇索引
- 4.
MyISAM存储引擎的数据和索引分开存储,这种存储引擎的索引全部都是 ⼆二级索引 ,在叶子节点处存储的是列+页号。
- 1.对于
【mysql】- 索引简介篇的更多相关文章
- 初识mysql索引 - 小白篇
:接触mysq也有两年左右的时间了,但是对该数据库的理解自认还比较初级,看过很多文章,也看过一些相关的书籍,依然小白....(这里个人总结是两点主要原因:1.对mysql的学习大部分都是源于看一些杂七 ...
- Mysql 索引 简介
Mysql索引 索引的分类 索引的创建 索引的注意事项 什么是索引 索引是存储引擎用于快速查找记录的一种数据结构. 索引由数据库中一列或者多列组成,作用是提高表的查询速度. 索引的优点,提高检索数据的 ...
- MySQL索引——总结篇
MySQL索引 MySQL索引 数据库的三范式,反模式 零碎知识 索引 索引原理 B Tree索引 B+Tree索引 B Tree 与 B+Tree的比较 聚集索引和辅助索引 聚集索引的注意事项 索引 ...
- MySQL索引简介(转)
一.为什么用索引例:先假设有一张表,表的数据有10W条数据,其中有一条数据是nickname='css',如果要拿这条数据的话需要写的sql是 SELECT * FROM award WHERE ni ...
- MySql索引简介
从"找"到B+树 索引是用来查找的. 折半查找是一种很优秀的方式.适合于 范围查找,固有缺点就是需要元素是有序的.二叉搜索树就是对折半查找的一种基础的实现. 但二叉搜索树当遇到特殊 ...
- Mysql高手系列 - 第22篇:深入理解mysql索引原理,连载中
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 欢迎大家加我微信itsoku一起交流java.算法.数据库相关技术. 这是Mysql系列第22篇. 背景 使用mys ...
- MySQL中的索引简介
MySQL中的SQL的常见优化策略 MySQL中的索引优化 MySQL中的索引简介 一. 索引的优点 为什么要创建索引?这是因为,创建索引可以大大提高系统的查询性能. 第一.通过创建唯一性索引,可以保 ...
- Mysql索引(一篇就够le)
我想很多人对mysql的认知可能就是CRUD(代表创建(Create).更新(Update).读取(Retrieve)和删除(Delete)操作),也不敢说自己会用和熟悉mysql,当然我就是其中一个 ...
- 「 MySQL高级篇 」MySQL索引原理,设计原则
大家好,我是melo,一名大二后台练习生,大年初三,我又来充当反内卷第一人了!!! 专栏引言 MySQL,一个熟悉又陌生的名词,早在学习Javaweb的时候,我们就用到了MySQL数据库,在那个阶段, ...
随机推荐
- 程序员如何高效学Python,如何高效用Python挣钱
本人在1年半之前,不熟悉Python(不过有若干年Java开发基础),由于公司要用Python,所以学习了一通.现在除了能用Python做本职工作外,还出了本Python书,<基于股票大数据分析 ...
- InnoDB 中 B+ 树索引的分裂
数据库中B+树索引的分裂并不总是从页的中间记录开始,这样可能会导致空间的浪费,例如下面的记录: 1, 2, 3, 4, 5, 6, 7, 8, 9 插入式根据自增顺序进行的,若这时插入10这条记录后需 ...
- Linux下9种优秀的代码比对工具推荐
大家好,我是良许. 在我们编写代码的时候,我们经常需要知道两个文件之间,或者同一个文件不同版本之间有什么差异性.在 Windows 下有个很强大的工具叫作 BeyondCompare ,那在 Linu ...
- NPM 配置文件修改
NPM 配置文件修改 几乎每一门语言都有配套的包管理器,比如 Ruby 有 RubyGems,Go 有 go modules,npm 作为 node 的包管理器,你有想过全局安装的 node 包都放在 ...
- python加载json文件
主要是加载进来,之后就没难度了 import json path = 'predict2.json' file = open(path, "rb") fileJson = json ...
- vue 生命周期钩子 路由钩子 动画钩子 执行顺序
进入首页的钩子们 1 路由钩子 路由跳转前beforeEach 2 路由钩子 home组件内部:守卫执行前beforeRouteEnter 3.路由钩子 路由跳转后afterEach 4 生命周期 h ...
- Flask项目实战:创建电影网站(2)
flask网站制作后台时候常见流程总结 安利一个神神器: 百度脑图PC版 创建数据库 下面是创建User数据库,需要导入db库 #coding:utf8 from flask import Flask ...
- Github中添加SSH key
1-创建密钥,在终端输入下面的命令 ssh-keygen -t rsa -b -C "你的邮箱" //双引号不能去 要求输入密码,建议回车使用空密码方便以后的每次连接,此时会生成一 ...
- JavaScript图形实例:Koch曲线
Koch曲线的构造过程是:取一条长度为L0的直线段,将其三等分,保留两端的线段,将中间的一段改换成夹角为60度的两个等长直线:再将长度为L0/3的4个直线段分别进行三等分,并将它们中间的一段均改换成夹 ...
- Jmeter(十四) - 从入门到精通 - JMeter定时器 - 下篇(详解教程)
1.简介 用户实际操作时,并非是连续点击,而是存在很多停顿的情况,例如:用户需要时间阅读文字内容.填表.或者查找正确的链接等.为了模拟用户实际情况,在性能测试中我们需要考虑思考时间.若不认真考虑思考时 ...