celery应用
celery---分布式任务队列
Celery是一个简单,灵活且可靠的分布式系统,可以处理大量消息,同时为操作提供维护该系统所需的工具。
Celery是一个基于python开发的模块,可以帮助我们对任务进行分发和处理;

1、环境搭建:
pip3 install celery==4.4
2、Broker选择:
Celery需要一种解决消息的发送和接受的方式,我们把这种用来存储消息的的中间装置叫做message broker, 也可叫做消息中间人。 作为中间人,我们有几种方案可选择:
RabbitMQ
RabbitMQ是一个功能完备,稳定的并且易于安装的broker. 它是生产环境中最优的选择。
Redis
Redis也是一款功能完备的broker可选项,但是其更可能因意外中断或者电源故障导致数据丢失的情况。 关于是有那个Redis作为Broker,可访下面网址: http://docs.celeryproject.org/en/latest/getting-started/brokers/redis.html#broker-redis
3、创建应用
- c1.py 文件
import time
from celery import Celery
app = Celery("tasks",broker="redis://49.222.54.28:6379",backend="redis://49.222.54.28:6379")
@app.task
def x1(x,y):
time.sleep(10)
return x + y
@app.task
def x2(x,y):
time.sleep(10)
return x - y
- c2.py 文件
from c1 import x1
result = x1.delay(4,4)
print(result)
print(result.id)
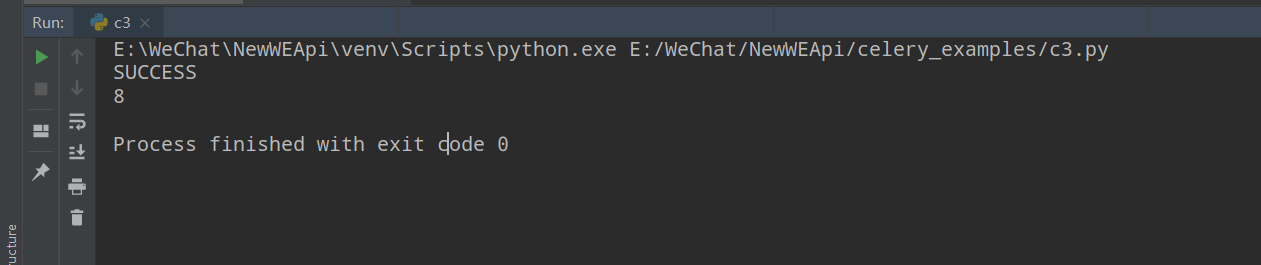
- c3.py 文件
from celery.result import AsyncResult
from c1 import app
result_object = AsyncResult(id="68cd648b-da09-4fef-9efe-d9e894a6a7ee",app=app)
data = result_object.get()
print(result_object.status)
print(data)
运行代码(windows环境):
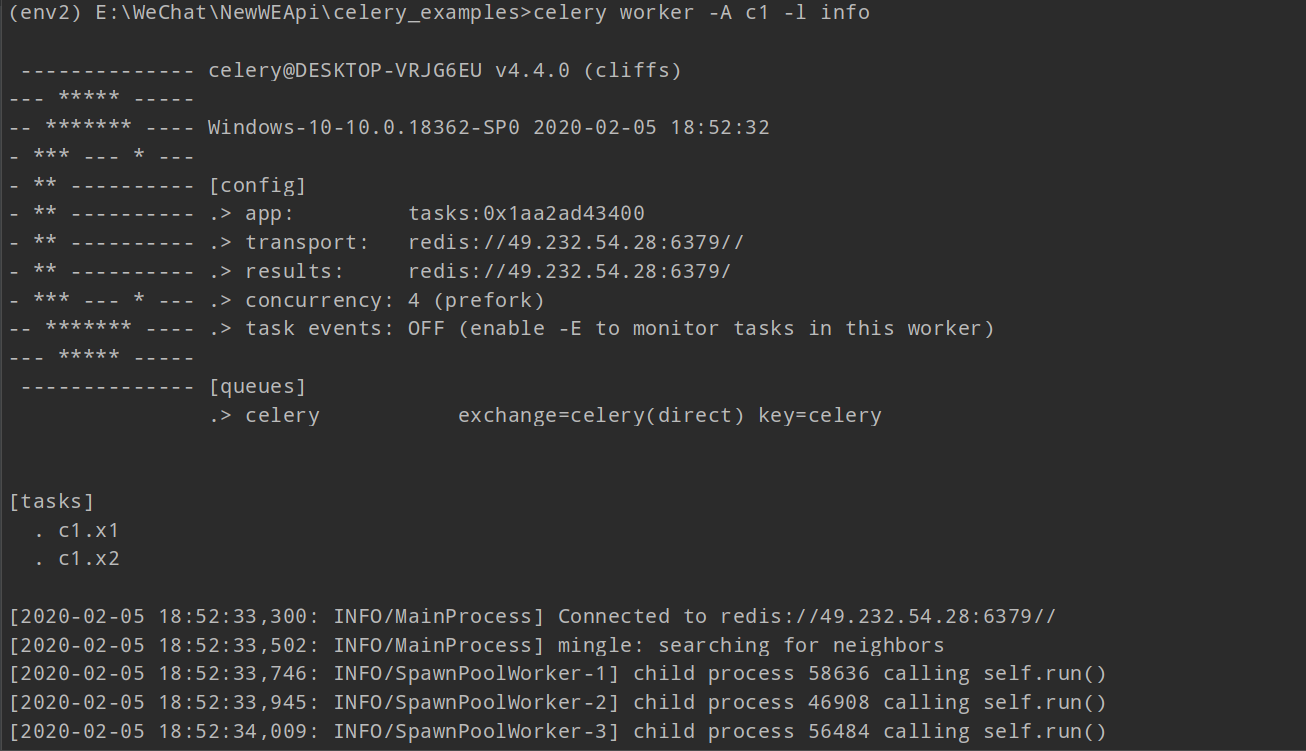
在终端下执行如下命令:
celery worker -A c1 -l info
说明:
-A 后边跟的是任务文件名
-l 是打印出日志
:
python c2.py
往任务队列中放任务,这时window环境的终端就会报一个错误信息:

这个错误只有window环境下才会出现,linux不会;这时我们需要安装一个模块:
pip install eventlet
当我们在启动worker的时候命令就应该这样写:
celery worker -A c1 -l info -P eventlet

创建完任务会有一个id值:

通过这个id值我们就能获取到执行完任务的结果:
4、在django中使用celery
第一步:【项目/项目/settings.py 】添加配置
CELERY_BROKER_URL = 'redis://192.168.16.85:6379'
CELERY_ACCEPT_CONTENT = ['json']
CELERY_RESULT_BACKEND = 'redis://192.168.16.85:6379'
CELERY_TASK_SERIALIZER = 'json'
第二步:【项目/项目/celery.py】在项目同名目录创建 celery.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'demos.settings')
app = Celery('demos')
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')
# Load task modules from all registered Django app configs.
# 去每个已注册app中读取 tasks.py 文件
app.autodiscover_tasks()
第三步,【项目/app名称/tasks.py】:写上具体的任务
from celery import shared_task
@shared_task
def add(x, y):
return x + y
@shared_task
def mul(x, y):
return x * y
第四步,【项目/项目/__init__.py】:启动Django程序加载celery.py文件
from NewWEApi.celery import app as celery_app
__all__ = ('celery_app',)
启动worker
进入项目目录
celery worker -A demos -l info -P eventlet
说明:
-A 后边加的是项目名称
-P 后边是windows环境下需要添加的模块
编写视图函数,调用celery去创建任务
url:
url(r'^create/tasks/$', task.create_task),
url(r'^get/result/$', task.get_result),
view:
from django.shortcuts import HttpResponse
from celery.result import AsyncResult
from api.tasks import add
from NewWEApi import celery_app
def create_task(request):
result = add.delay(1,4)
return HttpResponse(result.id)
def get_result(request):
nid = request.GET.get("nid")
result_object = AsyncResult(id=nid,app=celery_app)
data = result_object.get()
return HttpResponse(data)
最后启动Django程序
celery定时任务
def create_task(request):
# 获取本地时间
ctime = datetime.datetime.now()
# 将本地时间转换成utc时间
utc_time = datetime.datetime.utcfromtimestamp(ctime.timestamp())
target_time = utc_time + datetime.timedelta(seconds=10)
result = add.apply_async(args=[2,5],eta=target_time)
return HttpResponse(result.id)
移除任务队列中的任务
result_object.forget() # 移除任务队列中的任务
result_object.revoke() # 取消任务
celery应用的更多相关文章
- 异步任务队列Celery在Django中的使用
前段时间在Django Web平台开发中,碰到一些请求执行的任务时间较长(几分钟),为了加快用户的响应时间,因此决定采用异步任务的方式在后台执行这些任务.在同事的指引下接触了Celery这个异步任务队 ...
- celery使用的一些小坑和技巧(非从无到有的过程)
纯粹是记录一下自己在刚开始使用的时候遇到的一些坑,以及自己是怎样通过配合redis来解决问题的.文章分为三个部分,一是怎样跑起来,并且怎样监控相关的队列和任务:二是遇到的几个坑:三是给一些自己配合re ...
- tornado+sqlalchemy+celery,数据库连接消耗在哪里
随着公司业务的发展,网站的日活数也逐渐增多,以前只需要考虑将所需要的功能实现就行了,当日活越来越大的时候,就需要考虑对服务器的资源使用消耗情况有一个清楚的认知. 最近老是发现数据库的连接数如果 ...
- celery 框架
转自:http://www.cnblogs.com/forward-wang/p/5970806.html 生产者消费者模式 在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据 ...
- celery使用方法
1.celery4.0以上不支持windows,用pip安装celery 2.启动redis-server.exe服务 3.编辑运行celery_blog2.py !/usr/bin/python c ...
- Celery的实践指南
http://www.cnblogs.com/ToDoToTry/p/5453149.html Celery的实践指南 Celery的实践指南 celery原理: celery实际上是实现了一个典 ...
- Using Celery with Djang
This document describes the current stable version of Celery (4.0). For development docs, go here. F ...
- centos6u3 安装 celery 总结
耗时大概6小时. 执行 pip install celery 之后, 在 mac 上 celery 可以正常运行, 在 centos 6u3 上报错如下: Traceback (most recent ...
- celery 异步任务小记
这里有一篇写的不错的:http://www.jianshu.com/p/1840035cb510 自己的"格式化"后的内容备忘下: 我们总在说c10k的问题, 也做了不少优化, 然 ...
- Celery 框架学习笔记
在学习Celery之前,我先简单的去了解了一下什么是生产者消费者模式. 生产者消费者模式 在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是 ...
随机推荐
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 技术基础 | 改进版的Apache Cassandra客户端请求路由
最近我们在客户端的驱动程序中引入了一些变更,这些变更会影响传入的请求在Apache Cassandra集群内的分发方式. 新的默认负载均衡算法即将随驱动程序推出,这些算法将有助于缩短长尾延迟,并提 ...
- Github标星26k+!一个神奇的软件!1分钟即可打造了一个科幻风格的终端
Github掘金计划项目分类汇总(原创不易,若有帮助,欢迎分享/点赞): 编程基础 :精选编程基础如学习路线.编程语言相关的开源项目. 计算机基础:精选计算机基础(操作系统.计算机网络.算法.数据结构 ...
- 小白都能理解的Python多继承
本文主要做科普用,在真实编程中不建议使用多重继承,或者少用多重继承,避免使代码难以理解. 方法解析顺序(MRO) 关于多重继承,比较重要的是它的方法解析顺序(可以理解为类的搜索顺序),即MRO.这个跟 ...
- Python Cvxopt安装及LP求解
Python 2.7 Pycharm 1.直接File>Settings>Project>InterPreter ,点击右侧'+' 弹出Available packages窗口,搜索 ...
- Excel 快速跳到表格最后一行/第一行
快速跳到表格的最后一行 首先鼠标选中一个带有数据的单元格,点击shift键,把鼠标放到该单元格底部的边缘地带,出现带四个方向的箭头为止,再连续点击鼠标左键两次,直接跳到表格的最后一行 快速跳到表格的最 ...
- 1.mysql表优化和避免索引失效原则
表优化 1.单表优化 建立索引 根据sql的实际解析顺序建立复合索引 最佳左前缀,保持索引的定义和使用顺序一致 2.多表优化 连接查询 小表驱动大表:对于双层循环来说,外层循环(数据量)越小,内层循环 ...
- Java:利用BigDecimal类巧妙处理Double类型精度丢失
目录 本篇要点 经典问题:浮点数精度丢失 十进制整数如何转化为二进制整数? 十进制小数如何转化为二进制数? 如何用BigDecimal解决double精度问题? new BigDecimal(doub ...
- Mybatis 动态sql if 判读条件等于一个数字
在Mybatis中 mapper中 boolean updateRegisterCompanyFlag(@Param(value = "companyId") String com ...
- [Machine Learning] 逻辑回归 (Logistic Regression) -分类问题-逻辑回归-正则化
在之前的问题讨论中,研究的都是连续值,即y的输出是一个连续的值.但是在分类问题中,要预测的值是离散的值,就是预测的结果是否属于某一个类.例如:判断一封电子邮件是否是垃圾邮件:判断一次金融交易是否是欺诈 ...