Jdk1.7下的HashMap源码分析
本文主要讨论jdk1.7下hashMap的源码实现,其中主要是在扩容时容易出现死循环的问题,以及put元素的整个过程。
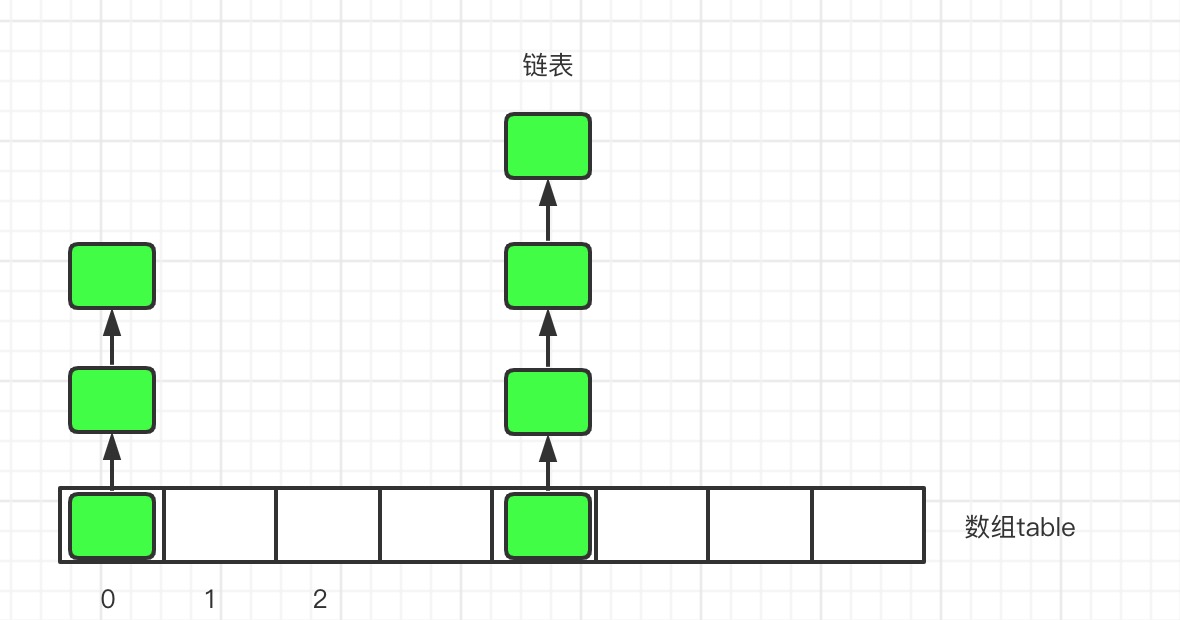
1、数组结构
数组+链表
示例图如下:
常量属性
/**
* The default initial capacity - MUST be a power of two.
* 默认初始容量大小
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* MUST be a power of two <= 1<<30.
* hashMap最大容量,可装元素个数
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
* 加载因子,如容量为16,默认阈值即为16*0.75=12,元素个数超过(包含)12且,扩容
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 空数组,默认数组为空,初始化后才才有内存地址,第一次put元素时判断,延迟初始化
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
2、存在的死循环问题
扩容导致的死循环,jdk1.7中在多线程高并发环境容易出死循环,导致cpu使用率过高问题,问题出在扩容方法resize()中,更具体内部的transfer方法:将旧数组元素转移到新数组过程中,源码如下:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//1.如果原来数组容量等于最大值了,2^30,设置扩容阈值为Integer最大值,不需要再扩容
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//2.创建新数组对象
Entry[] newTable = new Entry[newCapacity];
//3.将旧数组元素转移到新数组中,分析一
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//4.重新引用新数组对象和计算新的阈值
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
transfer方法
/**
* Transfers all entries from current table to newTable.
* 从当前数组中转移所有的节点到新数组中
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍历旧数组
for (Entry<K,V> e : table) {
//1,首先获取数组下标元素
while(null != e) {
//2.获取数组该桶位置链表中下一个元素
Entry<K,V> next = e.next;
//3.是否需要重新该元素key的hash值
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//4,重新确定在新数组中下标位置
int i = indexFor(e.hash, newCapacity);
//5.头插法:插入新链表该桶位置,若有元素,就形成链表,每次新加入的节点都插在第一位,就数组下标位置
e.next = newTable[i];
newTable[i] = e;
//6.继续获取链表下一个元素
e = next;
}
}
}
//传入容量值返回是否需要对key重新Hash
final boolean initHashSeedAsNeeded(int capacity) {
//1.hashSeed默认为0,因此currentAltHashing为false
boolean currentAltHashing = hashSeed != 0;
//2,sun.misc.VM.isBooted()在类加载启动成功后,状态会修改为true
// 因此变数在于,capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD,debug发现正常情况ALTERNATIVE_HASHING_THRESHOLD是一个很大的值,使用的是Integer的最大值
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
//3,两者异或,只有不相同时才为true,即useAltHashing =true时,dubug代码发现useAltHashing =false,
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
//正常情况下是返回false,即不需要重新对key哈希
return switching;
}
上面源码展示转移元素过程:
以下模拟2个线程并发操作hashMap 在put元素时造成的死循环过程:
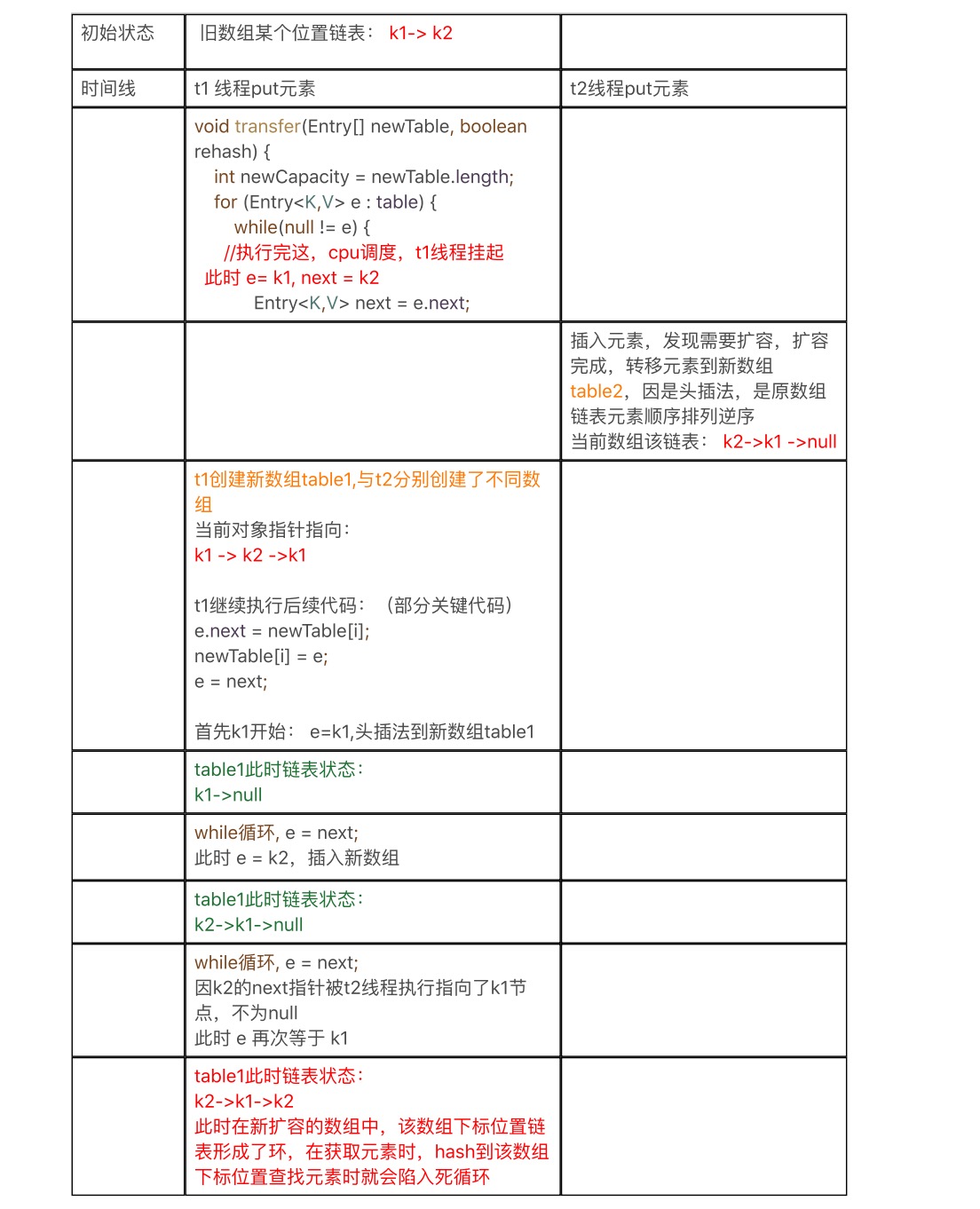
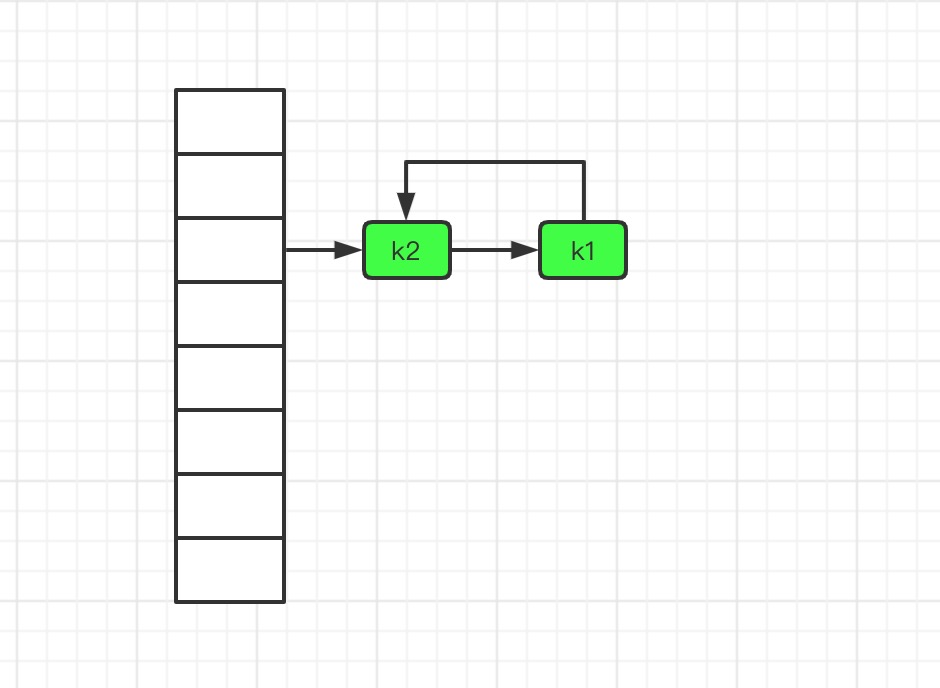
链表死循环图例:
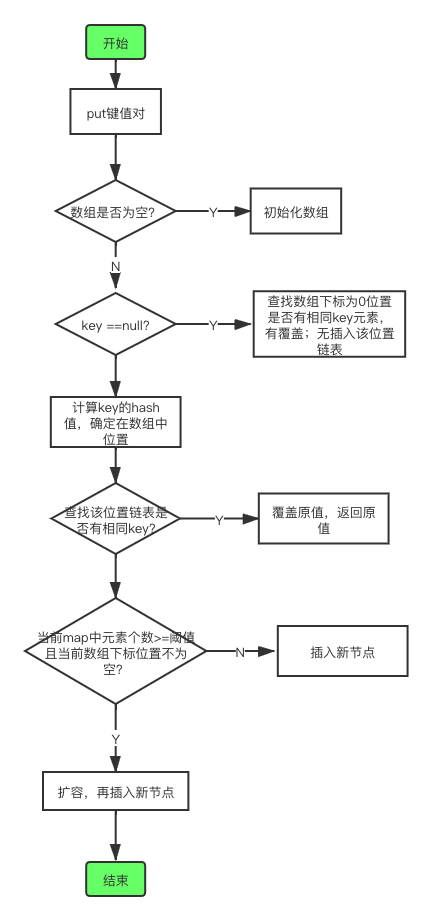
3、put方法
1.7的put方法,因没有红黑树结构,相比较1.8简单, 容易理解,流程图如下所示:
代码如下:
public V put(K key, V value) {
//1,若当前数组为空,初始化
if (table == EMPTY_TABLE) {
//分析1
inflateTable(threshold);
}
//2,若put的key为null,在放置在数组下标第一位,索引为0位置,从该源码可知
// hashMap允许 键值对 key=null,但是只能有唯一一个
if (key == null)
// 分析2
return putForNullKey(value);
//3,计算key的hash,这里与1.8有区别
//分析3
int hash = hash(key);
// 4,确定在数组下标位置,与1.8相同
int i = indexFor(hash, table.length);
// 5,遍历该数组位置,即该桶处遍历
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 找到相同的key,则覆盖原value值,返回旧值
V oldValue = e.value;
e.value = value;
//该方法为空,不用看
e.recordAccess(this);
return oldValue;
}
}
//因为hashMap线程不安全,修改操作没有同步锁,
//该字段值用于记录修改次数,用于快速失败机制 fail-fast,防止其他线程同时做了修改,抛出并发修改异常
modCount++;
// 6,原数组中没有相同的key,以头插法插入新的元素
//分析4
addEntry(hash, key, value, i);
return null;
}
分析1: HashMap如何初始化数组的,延迟初始化有什么好处?
结论: 1、1.7,1.8都是延迟初始化,在put第一个元素时创建数组,目的是为了节省内存。
初始化代码:
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
//1.该方法非常重要,目的为了得到一个比toSize最接近的2的幂次方的数,
// 且该数要>=toSize,这个2的幂次方方便后面各种位运算
// 如:new HashMap(15),指定15大小集合,内部实际 创建数组大小为2^4=16
// 分析见下
int capacity = roundUpToPowerOf2(toSize);
//2,确定扩容阈值
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//3,初始化数组对象
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
Q:如何确保获取到比toSize 最接近且大于等于它的2的幂次方的数?
深入理解roundUpToPowerOf2方法:
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
//如果number大于等于最大值 2^30,赋值为最大,主要是防止传参越界,number一定是否非负的
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
//核心在于Integer.highestOneBit((number - 1) << 1) 此处
}
先抛出2个问题:
1:这个 (number - 1) << 1 的作用是什么?
2:这个方法highestOneBit肯定是为了获取到满足条件的2的幂次方的数,背后的原理呢?
结论: Integer的方法highestOneBit(i) 这个方法是通过位运算,获取到i的二进制位最左边(最高位)的1,其余位都抹去,置为0,即获取的是小于等于i的2的幂次方的数.
如果直接传入number,那么获取到的是2的幂次方的数,但是该数一定小于等于number,但这不是我们的目的;
如highestOneBit(15)=8highestOneBit(21)=16而我们是想要获取一个刚刚大于等于number的2次方的数,(number-1)<<1 因此需要先将number 扩大二倍number <<1 , 为什么需要number-1,是考虑到临界值问题,恰好number本身就是2的幂次方,如 number=16,扩大2倍后为32, highestOneBit方法计算后结果还是32,这不符合需求。
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
2的幂次方二进值特点:只有最高位为1,其他位全为0
目的:将传入i的二进制最左边的1保留,其余低位的1全变为0
原理:某数二进制: 0001 ,不关心其低位是什么,以*代替,进行运算
- 右移1位
i |= (i >> 1);
0001****
|
00001***
----------
00011*** #保证左边2位是1
- 右移2位
i |= (i >> 2);
00011***
|
0000011*
----------
0001111* #保证左边4位是1
- 右移4位
i |= (i >> 4);
0001111*
|
00000001
----------
00011111 #把高位以下所有位变为1了,该数还是只有5位,该计算可将8位下所有的置为1
Q:为什么要再执行右移8位,16位?
因int类型 4个字节,32位,这样可以一定可以保证将低位全置为1;
- 最后一步,大功告成!
i - (i >>> 1);
#此时 i= 00011111
00011111
-
00001111 #无符号右移1位
---------
00010000 #拿到值
分析2: HashMap如何处理key 为null情况,value呢?
结论:
- 允许key为null,但最多唯一存在一个,放在数组下标为0位置
- value为null的键值对可以有多个
- 由1,2 推得,键值对都为null的Entry对象可以有,但最多一个
private V putForNullKey(V value) {
//1.直接table[0] 位置获取,先遍历链表(这里对该数组位置统称为链表,可能没有元素,或者只有一个元素,或者链表)查找是否存在相同的key,存在覆盖原值
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//此时注意添加节点时,第一个0即代表数组下标位置,后面会分析该方法
addEntry(0, null, value, 0);
return null;
}
分析3:如何实现hash算法,保证key的hash值均匀分散,减少hash冲突?
jdk1.7中为了尽可能的对key的hash后均匀分散,扰动函数实现采用了 5次异或+4次位移
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
//k的hashCode值 与hashSeed 异或
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
分析4:插入新的节点到map中,如果原数组总元素个数超过阈值,先扩容再插入节点
void addEntry(int hash, K key, V value, int bucketIndex) {
//总元素个数大于等于阈值 且 当前数组下标已存在元素了: 扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//1,扩容,上面已分析过代码
resize(2 * table.length);
//2,计算新加key的hash值,key为null的hash值为0
hash = (null != key) ? hash(key) : 0;
//3,确保计算的数组下标一定在数组有效索引内,见分析5
bucketIndex = indexFor(hash, table.length);
}
// 4,扩容后再插入新数组中
createEntry(hash, key, value, bucketIndex);
}
//分析5
static int indexFor(int h, int length) {
// 与数组长度-1与运算,一定可以确保结果值在数组有效索引内,且均匀分散
return h & (length-1);
}
// 进一步分析插入节点方法
void createEntry(int hash, K key, V value, int bucketIndex) {
//1,首先获取新数组索引位置元素
Entry<K,V> e = table[bucketIndex];
//2,头插法插入新节点, Entry构造方法第4个参数e表示指定当前新增节点的next指针指向该节点,形成链表
table[bucketIndex] = new Entry<>(hash, key, value, e);
//3,map元素个数+1
size++;
}
参考:
一、1.7解析:https://blog.csdn.net/carson_ho/article/details/79373026
二、1.8解析:https://www.jianshu.com/p/8324a34577a0
Jdk1.7下的HashMap源码分析的更多相关文章
- Jdk1.8下的HashMap源码分析
目录结构 一.面试常见问题 二.基本常量属性 三.构造方法 四.节点结构 4.1 Node类 4.2.TreeNode 五.put方法 5.1 key的has ...
- JDK1.7 中的HashMap源码分析
一.源码地址: 源码地址:http://docs.oracle.com/javase/7/docs/api/ 二.数据结构 JDK1.7中采用数组+链表的形式,HashMap是一个Entry<K ...
- 基于JDK1.8版本的hashmap源码分析(一)
今天看了下hashmap中的源码,下面列出一些自己的收获 开头,public class HashMap<K,V> extends AbstractMap<K,V> im ...
- 基于JDK1.8版本的hashmap源码笔记(二)
这一篇是接着上一篇写的, 上一篇的地址是:基于JDK1.8版本的hashmap源码分析(一) /** * 返回boolean类型的值,当集合中包含key的键值,就返回true,否则就返 ...
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- HashMap 源码分析 基于jdk1.8分析
HashMap 源码分析 基于jdk1.8分析 1:数据结构: transient Node<K,V>[] table; //这里维护了一个 Node的数组结构: 下面看看Node的数 ...
- 源码分析系列1:HashMap源码分析(基于JDK1.8)
1.HashMap的底层实现图示 如上图所示: HashMap底层是由 数组+(链表)+(红黑树) 组成,每个存储在HashMap中的键值对都存放在一个Node节点之中,其中包含了Key-Value ...
- 【JAVA集合】HashMap源码分析(转载)
原文出处:http://www.cnblogs.com/chenpi/p/5280304.html 以下内容基于jdk1.7.0_79源码: 什么是HashMap 基于哈希表的一个Map接口实现,存储 ...
- 【Java】HashMap源码分析——基本概念
在JDK1.8后,对HashMap源码进行了更改,引入了红黑树.在这之前,HashMap实际上就是就是数组+链表的结构,由于HashMap是一张哈希表,其会产生哈希冲突,为了解决哈希冲突,HashMa ...
随机推荐
- python- generator生成器
什么是生成器? 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后 ...
- PJzhang:python基础入门的7个疗程-seven
猫宁!!! 参考链接:易灵微课-21天轻松掌握零基础python入门必修课 https://www.liaoxuefeng.com/wiki/1016959663602400 第19天:开源模块 数据 ...
- xenomai内核解析之信号signal(二)---xenomai信号处理机制
xenomai信号 上篇文章讲了linux的信号在内核的发送与处理流程,现在加入了cobalt核,Cobalt内核为xenomai线程提供了信号机制.下面一一解析xenomai内核的信号处理机制. 1 ...
- 仔细想想SpringAOP也不难嘛,面试没有必要慌
文章已托管到GitHub,大家可以去GitHub查看阅读,欢迎老板们前来Star! 搜索关注微信公众号 码出Offer 领取各种学习资料! LOGO SpringAOP 一.什么是AOP AOP(As ...
- [转载]Python ImportError: No module named 'requests'解决方法
windows解决办法1.找到easy_install.exe.一般在python的安装路径下的Scripts文件夹中,如C:\Python34\Scripts\easy_install.exe2.从 ...
- 使用ImpromptuInterface反射库方便的创建自定义DfaGraphWriter
在本文中,我为创建的自定义的DfaGraphWriter实现奠定了基础.DfaGraphWriter是公开的,因此您可以如上一篇文章中所示在应用程序中使用它,但它使用的所有类均已标记为internal ...
- INSERT插入WHERE判断是否插入(MySQL)
一.INSERT INTO IF EXISTS 具体语法:INSERT INTO table(field1, field2, fieldn) SELECT 'field1', 'field2', 'f ...
- [spring] -- 事务篇
关于Transactional注解 五个表示隔离级别的常量 TransactionDefinition.ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,Mysql 默认采用的 REP ...
- 常用限流算法与Guava RateLimiter源码解析
在分布式系统中,应对高并发访问时,缓存.限流.降级是保护系统正常运行的常用方法.当请求量突发暴涨时,如果不加以限制访问,则可能导致整个系统崩溃,服务不可用.同时有一些业务场景,比如短信验证码,或者其它 ...
- 服务质量分析:腾讯会议&腾讯云Elasticsearch玩出了怎样的新操作?
导语 | 腾讯会议于2019年12月底上线,两个月内日活突破1000万,被广泛应用于疫情防控会议.远程办公.师生远程授课等场景,为疫情期间的复工复产提供了重要的远程沟通工具.上线100天内,腾讯会议快 ...