Elasticsearch 为了搜索
前言
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有。
下面将从索引、相关性、TF−IDF与BM25相关性算法、查全率跟查准率来分析Elasticsearch的搜索。
倒排索引
说到倒排索引,就不得不说正排索引。
正排索引,由key查询实体的过程,使用正排索引,比如我们常用的MySQL索引到数据行的过程。
倒排索引由词查询文档的过程,使用倒排索引。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。
两者的区别就比如一本书中,书本目录是正排索引,书本附录中的术语中关联的页数是倒排索引。
相关性(relevance)
对于MySQL中的数据,默认返回的索引数据存储的数据,那Elasticsearch返回的文档的排序顺序呢?
默认情况下,返回结果是按相关性倒序排列的。但是什么是相关性?相关性如何计算?
每个文档都有相关性评分,用一个正浮点数字段 _score 来表示。_score 的评分越高,相关性越高。
查询语句会为每个文档生成一个 _score 字段。评分的计算方式取决于查询类型 不同的查询语句用于不同的目的: fuzzy 查询会计算与关键词的拼写相似程度,terms 查询会计算找到的内容与关键词组成部分匹配的百分比,但是通常我们说的 relevance 是我们用来计算全文本字段的值相对于全文本检索词相似程度的算法。
相关性的算法有TF-IDF跟BM25,Elasticsearch5.0之后默认相关性算法是BM25。
一些术语
索引词(term)
在Elasticsearch中索引词(term)是一个能够被索引的精确值。
如果是英文,忽略大小写,保存为小写格式,忽略一些无效词(比如the);
如果是中文,忽略一些无效词(比如“的”)
文本(text)
文本是一段普通的非结构化文字。通常,文本会被分析成一个个的索引词,存储在Elasticsearch的索引库中。
比如文本“I love China”可能会被分析成索引词“I”,“love”,“China”。具体还得看分词器。
分析(analysis)
分析是将文本转换为索引词的过程,分析的结果依赖于分词器。
文档(document)
文档是存储在Elasticsearch中的一个JSON格式的字符串。它就像在关系数据库中表的一行。
TF-IDF 算法
TF(Term Frequence):代表词频。公式为 text中某一索引词w出现的次数 / text所有的term的个数
IDF(Invert Document Frequence):代表逆向文档频率。公式为 lg(总文档数 / (有索引词w的文档数+1))
TF−IDF的值为TF∗IDF。
例子:一篇文档总的词语数是100个,而词语“中华”出现了3次,词频就是3/100=0.03,如果“中华”出现在1000份文件中,而所有文件总数是10000000份,逆向文件频率就是 lg(10,000,000 / 1,000)=4,最后的TF-IDF的分数为0.03 * 4 = 0.12。
BM25 算法
BM25 源自 概率相关模型,而不是向量空间模型,BM25 同样使用词频、逆向文档频率以及字段长归一化,但是每个因子的定义都有细微区别。
公式
IDF * ((k + 1) * tf) / (k * (1.0 - b + b * (|d|/avgDl)) + tf)
IDF是根据概率信息检索获得
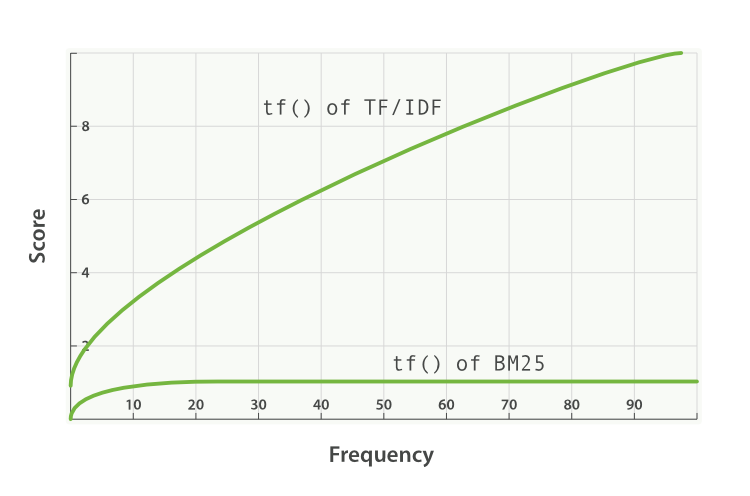
相比传统的TF*IDF相关性算法,在BM25中词频的影响降低。词频的影响一直在增加,但渐渐地逼近一个值。
BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。
搜索的效率
如何衡量搜索的效率呢?用查全率跟查准率。
查全率=(搜索出的相关文档/系统中的相关文档总量)*100%。代表所有相关文档被检索的比例。
查准率=(搜索出的相关文档/检索出的文档总量)*100%。代表搜索出来的文档中相关文档的比例。
查全率是衡量搜索系统和搜索者搜出相关文档的能力,查准率是衡量搜索系统和搜索者拒绝非相关相关文档的能力。两者合起来,即表示搜索效率。

比如上图中,期望结果是搜索出所有的实心圆,结果是搜索出了部分实心圆跟不想要的空心圆。
分词器
分词器 接受一个字符串作为输入,将这个字符串拆分成独立的词或 语汇单元(token) (可能会丢弃一些标点符号等字符),然后输出一个 语汇单元流(token stream) 。
有趣的是用于词汇 识别 的算法。 whitespace (空白字符)分词器按空白字符 —— 空格、tabs、换行符等等进行简单拆分 —— 然后假定连续的非空格字符组成了一个语汇单元。例如:
GET /_analyze?tokenizer=whitespace
You're the 1st runner home!
这个请求会返回如下词项(terms): You're 、 the 、 1st 、 runner 、 home!
icu_分词器 和 标准分词器 使用同样的 Unicode 文本分段算法, 只是为了更好的支持亚洲语,添加了泰语、老挝语、中文、日文、和韩文基于词典的词汇识别方法,并且可以使用自定义规则将缅甸语和柬埔寨语文本拆分成音节。
中文分词还可以使用“IK”分词器。
中文分词难点,需要根据上下文语义进行分词。比如“这个苹果不大好吃”,可以有两种分词,“这个苹果,不大好吃”,“这个苹果,不大,好吃”,不一样的分词,不一样的结果。
参考资料
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/controlling-relevance.html
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/relevance-intro.html
- https://lucene.apache.org/core/
Elasticsearch 为了搜索的更多相关文章
- ElasticSearch位置搜索
ElasticSearch位置搜索 学习了:https://blog.csdn.net/bingduanlbd/article/details/52253542 学习了:https://blog.cs ...
- ElasticSearch入门-搜索(java api)
ElasticSearch入门-搜索(java api) package com.qlyd.searchhelper; import java.util.Map; import net.sf.json ...
- PHP使用ElasticSearch做搜索
PHP 使用 ElasticSearch 做搜索 https://blog.csdn.net/zhanghao143lina/article/details/80280321 https://www. ...
- 十九种Elasticsearch字符串搜索方式终极介绍
前言 刚开始接触Elasticsearch的时候被Elasticsearch的搜索功能搞得晕头转向,每次想在Kibana里面查询某个字段的时候,查出来的结果经常不是自己想要的,然而又不知道问题出在了哪 ...
- Elasticsearch实现搜索推荐词
本篇介绍的是基于Elasticsearch实现搜索推荐词,其中需要用到Elasticsearch的pinyin插件以及ik分词插件,代码的实现这里提供了java跟C#的版本方便大家参考. 1.实现的结 ...
- Elasticsearch分布式搜索和数据分析引擎-ElasticStack(上)v7.14.0
Elasticsearch概述 **本人博客网站 **IT小神 www.itxiaoshen.com Elasticsearch官网地址 https://www.elastic.co/cn/elast ...
- Elasticsearch 教程--搜索
搜索 – 基本工具 到目前为止,我们已经学习了Elasticsearch的分布式NOSQL文档存储,我们可以直接把JSON文档扔到Elasticsearch中,然后直接通过ID来进行调取.但是Elas ...
- Elasticsearch 数据搜索篇·【入门级干货】
ES即简单又复杂,你可以快速的实现全文检索,又需要了解复杂的REST API.本篇就通过一些简单的搜索命令,帮助你理解ES的相关应用.虽然不能让你理解ES的原理设计,但是可以帮助你理解ES,探寻更多的 ...
- Elasticsearch分布式搜索集群配置
配置文件位于%ES_HOME%/config/elasticsearch.yml文件中,用Editplus打开它,你便可以进行配置. 所有的配置都可以使用环境变量,例如:node.rack: ${ ...
随机推荐
- Codeforces Round #570 (Div. 3) E. Subsequences (easy version) (搜索,STL)
题意:有一长度为\(n\)的字符串,要求得到\(k\)不同的它的子序列(可以是空串),每个子序列有\(|n|-|t|\)的贡献,求合法情况下的最小贡献. 题解:直接撸个爆搜找出所有子序列然后放到set ...
- hdu2126 Buy the souvenirs
Problem Description When the winter holiday comes, a lot of people will have a trip. Generally, ther ...
- 【转】Kubernetes scheduler学习笔记
简介 Kubernetes是一个强大的编排工具,可以用来很方便的管理许多台机器,为了使机器的资源利用率提高,同时也尽可能的把压力分摊到各个机器上,这个职责就是由scheduler来完成的. Kuber ...
- Linux-源码安装及FPM打包
目录 源码安装 制作RPM包(使用FPM工具) 安装rpm后要执行的脚本(优化版) 源码安装 这里举例Nginx的源码安装,需要前往Nginx官网找到稳定版本源码安装包下载. ## 源码安装nginx ...
- Kubernets二进制安装(7)之部署主控节点服务--apiserver二进制安装
kube-apiserver集群规划 主机名 角色 IP地址 mfyxw30.mfxyw.com kube-apiserver主 192.168.80.30 mfyxw40.mfyxw.com kub ...
- 1076D Edge Deletion 【最短路】
题目:戳这里 题意:求出1到所有点的最短路径后,把边减到小于等于k条,问保留哪些边可以使仍存在的最短路径最多. 解题思路:这题就是考求最短路的原理.比如dijkstra,用优先队列优化后存在队列中的前 ...
- linux repo init 遇到的问题
问题描述: 利用repo从远程服务器上取代码时候,出现错误 fatal: cannot make .repo directory:Permission denied, 加了sudo 之后,还是不行, ...
- hdu5303贪心
http://acm.hdu.edu.cn/showproblem.php?pid=5303 说一下题目大意.. 有一个长为L的环..你家在原点位置0,那么剩下L-1个点上种有一些树, 给你树的位置和 ...
- React Native for Windows + macOS
React Native for Windows + macOS React Native 0.63 https://aka.ms/ReactNative https://microsoft.gith ...
- HTML5 image rotate effect
HTML5 image rotate effect HTML5 实现旋转拨号键盘 简单的html中js实现图片中心旋转 https://download.csdn.net/download/q3168 ...