mongodb 数据操作CRUD
链接到mongo
新建超级用户
上文中我们提到mongo用户库表管理。为了方便我们先新建一个root权限的用户。
db.createUser({user:'dbadmin',pwd:'123456', roles:[{role:'userAdminAnyDatabase', db:'admin'}]})
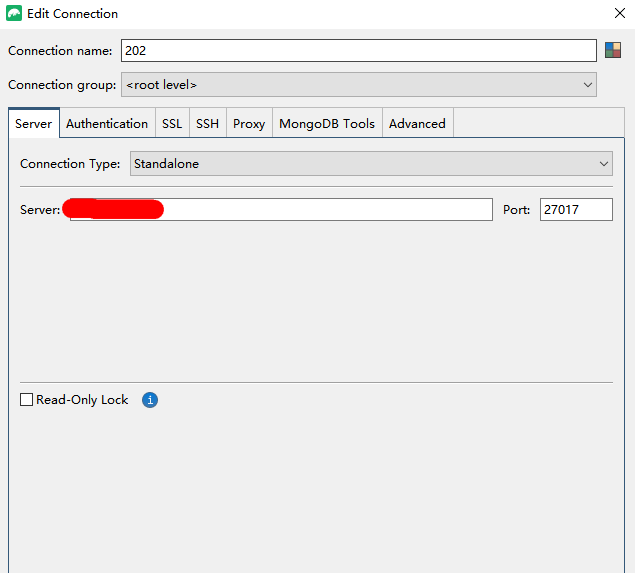
使用studio-3t链接到mongo

新建爬虫库
打开连接后,在连接上右键,然后Add Database ->输入数据库名称spider001
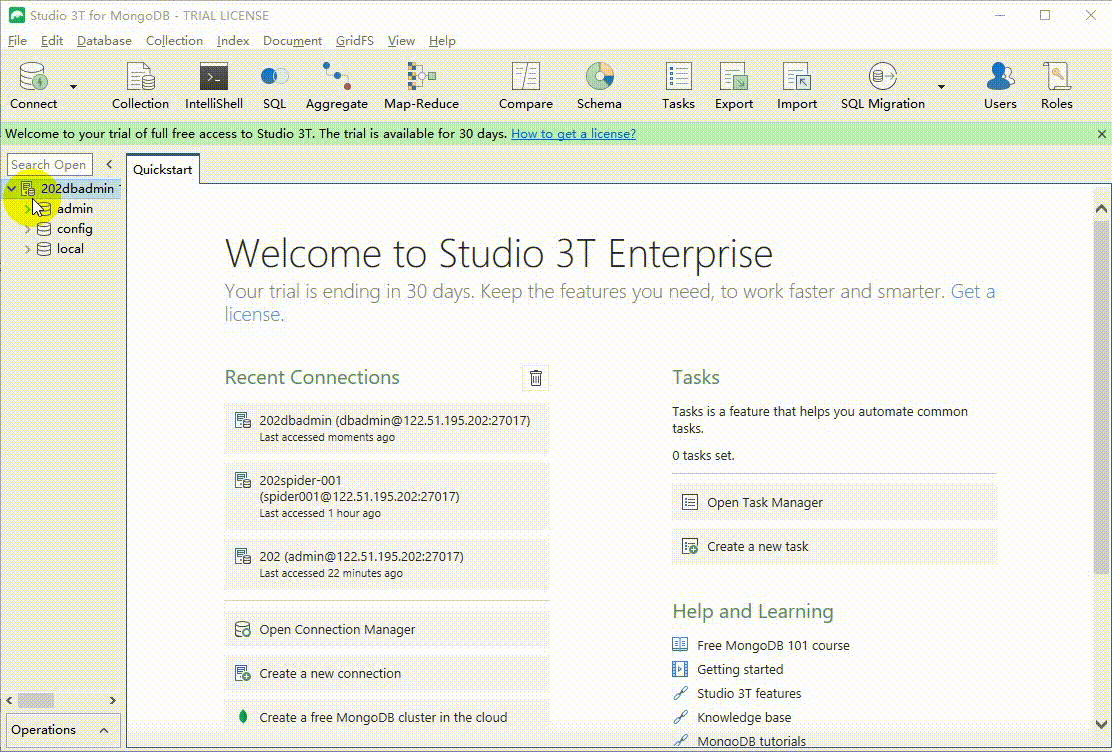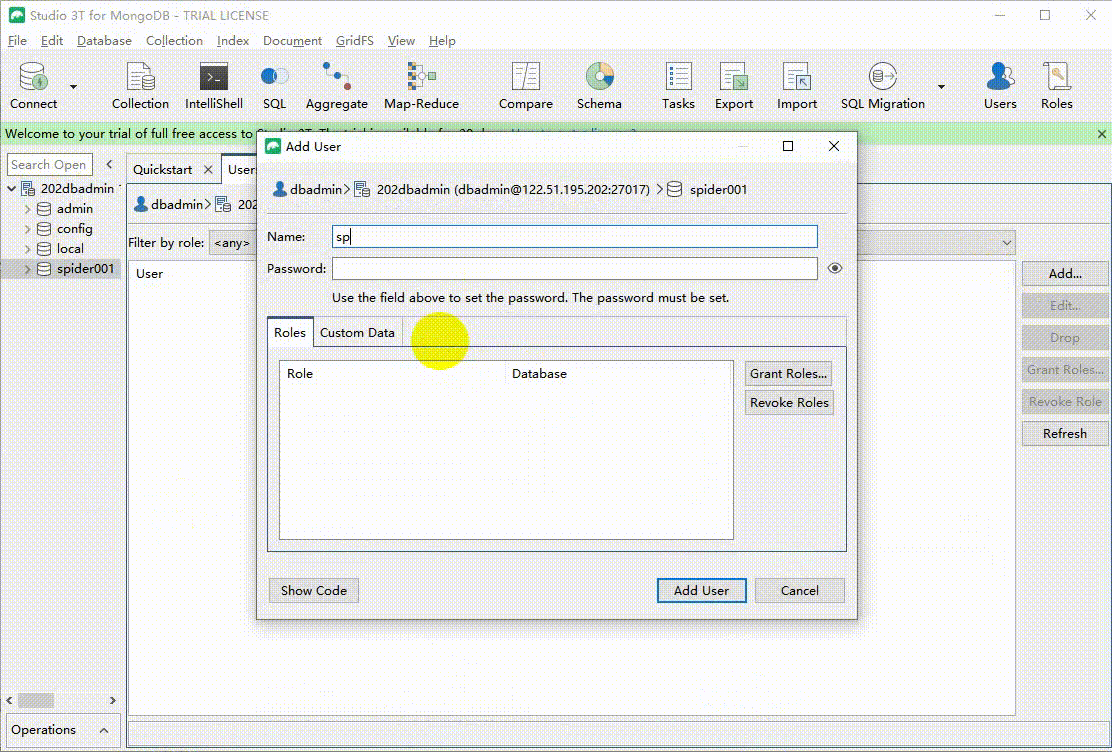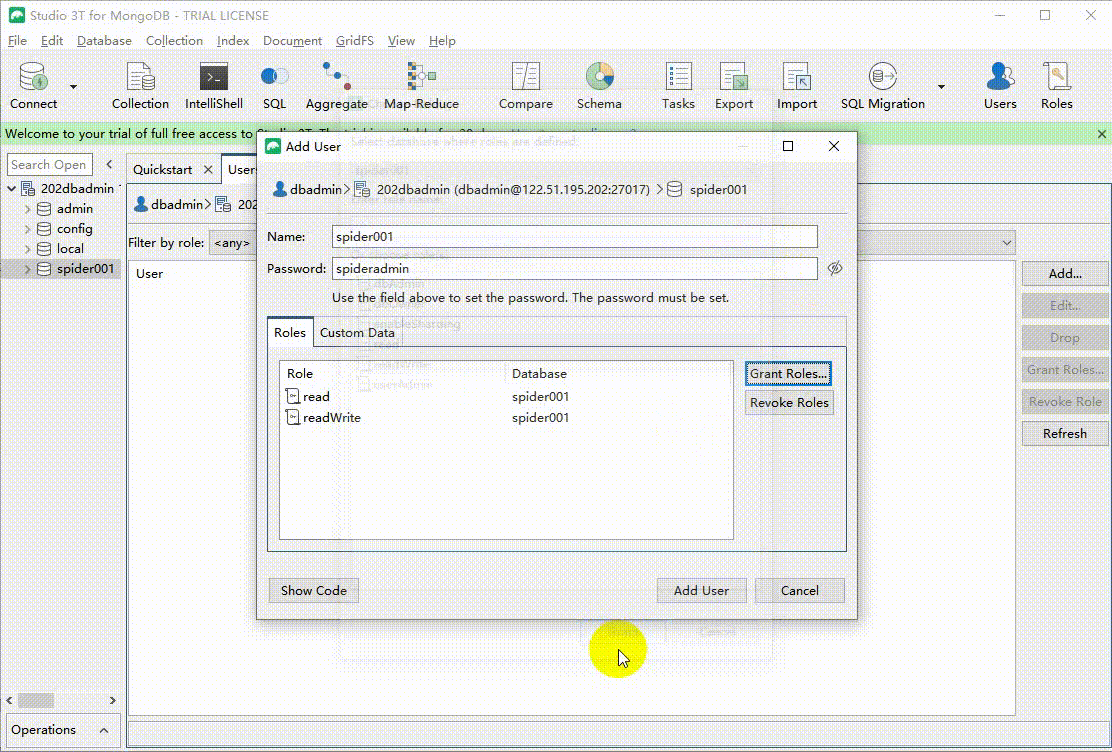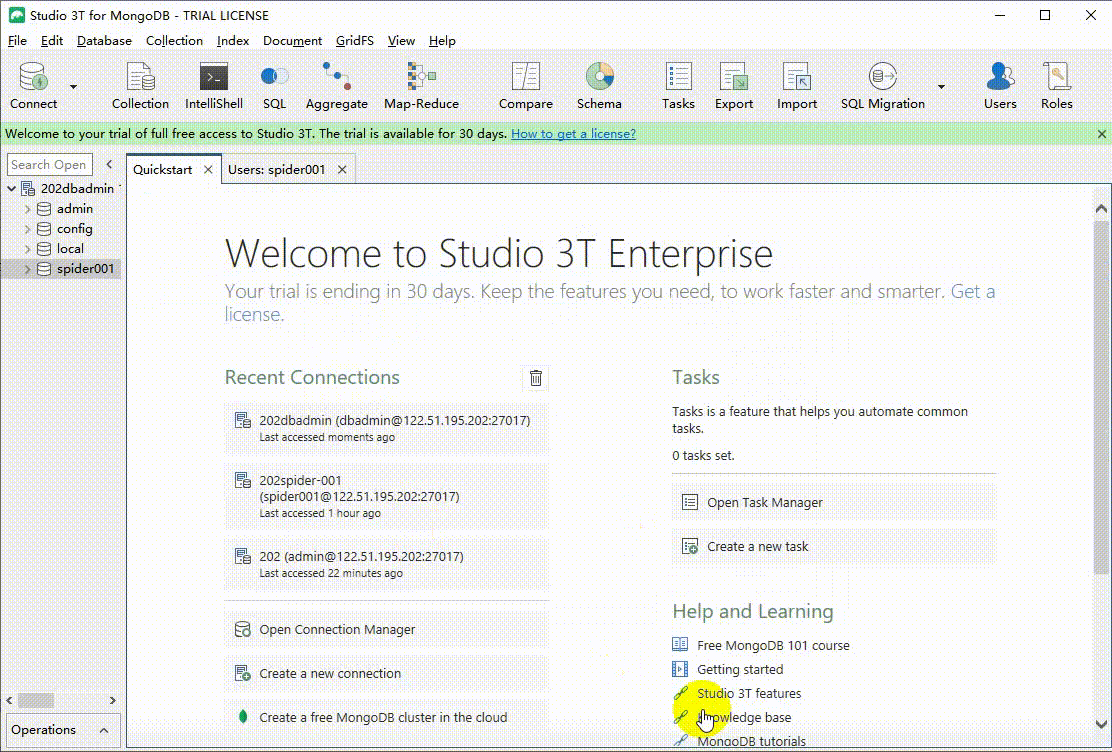
spider001在数据库上面右键Manage Users -> Add 然后输入用户密码,再授权。我们还能查看该操作对应的代码。特别注意新建数据库操作其实相当于use dbname 的操作,不会真正新建数据库,只有数据库有用户或者数据时,数据库才回真实存在
use spider001
db.runCommand({
"createUser" : "spider001",
"pwd" : "spideradmin",
"customData" : {
},
"roles" : [
{
"role" : "read",
"db" : "spider001"
},
{
"role" : "readWrite",
"db" : "spider001"
}
]
});
CRUD操作
Create or insert
选择spider001数据库,可以用studio 3t打开一个shell终端
#单条
db.user.insert({name:"refly",nikename:"haima",joy:["NBA","football","hiking"]})//不需要建表
#多条
db.user.insertMany([
{
"name":"hailong",age:20,work:{location:"成都",name:"spider"}
},
{
"name":"rob",
"birth":new Date("2020-10-23")
}
])
插入后回自动生成一个_id字段
Read operations
find方法基本应用
db.user.find({}) //查询所有
db.user.find({name:"haima"}) //字段匹配
db.user.find({"_id": ObjectId("5f9297276951ee42b7a44c24")}) //_id字段
db.user.find({age:{$gt:10}}) //筛选age字段大于10岁的
db.user.find({"work.name":"spider"}) //二级对象
db.user.find({"birth":{$gt:new Date("2010-10-23")}}) //日期处理
db.user.find({age:{$exists:false}} ) //查询age字符不存在的 数据
//正则
db.user.find(
{ "name": { $regex: /^.*g$/ } }
)
//多条件
db.user.find( {
name:"hailong",
age:20
} )
db.user.find({joy:{$size:3}}) //查询joy(数组)字段 长度为3的数据
关键词
$in数组字段中,有一个满足就满足查询$all数组字段中,包含所有给出的值 才满足查询$gtgreater than 筛选条件 中的 大于$ltless than 筛选条件 中的 小于$lte小于等于$gte大于等于$exists筛选字段是否存在
db.bios.find( { contribs: { $all: [ "ALGOL", "Lisp" ] } } ) //contribs含其 `ALGOL`且包含`Lisp`
db.bios.find( { contribs: { $in: [ "ALGOL", "Lisp" ]} } ) //contribs含其中一个就可以
限制返回值字段
db.user.find( { }, { name: 1 } ) //只返回name字段和 _id字段,_id会默认返回
db.user.find( { }, { name: 1, _id: 0} ) //只返回name字段
db.user.find( { }, { name: true } ) //true,false也可以
//二级字段,只返回work.location字段,当然也会返回work
db.user.find({ },{ _id: 0,"work.location":1 } )
db.user.find({ },{ _id: 0,joy:{$slice:1} } ) //joy字段(数组)中只返回一个元素
常用方法 sort() limit() skip()
sort()排序
db.user.find({ }).sort( { age:-1, name: -1} ) //先按年龄排序,然后再按照名字排序
limit(n) 取前面n条
db.user.find( { } ).limit(10) //取10条
skip(n) 跳过前面几条
db.user.find( { } ).skip(10) //忽略前10条
min()、max()
暂无解读
count()
db.user.find( { } ).count() //统计查询条数
itcount()
也是统计查询条数,区别是itcount()是迭代器中剩余的条数,而.count() 是查询条数
db.user.find({ }).limit(10).count() //结果为11,表中为11条数据
db.user.find({ }).limit(10).itcount() //结果为10,迭代器中剩余10条数据
size()
可以统计出skip()和limit()查询过后的元素条数,这个更像itcount()
next()
迭代器返回下一个对象
db.user.find({ }).next()
explain()
查询详情
db.user.find({"work.name":"spider"}).explain() //感觉并没什么暖用
结果为
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "spider001.user",
"indexFilterSet" : false,
"parsedQuery" : {
"work.name" : {
"$eq" : "spider"
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"work.name" : {
"$eq" : "spider"
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "VM_0_8_centos",
"port" : 27017,
"version" : "3.6.20",
"gitVersion" : "39c200878284912f19553901a6fea4b31531a899"
},
"ok" : 1
}
forEach()
遍历执行
db.user.find().forEach(function(el){print(el.name) })
map()
遍历执行,每个执行结果都会返回,组成一个数组对象
db.user.find().map( function(u) { if(u.name!=null)return u.name; } )
Update Operations
updateOne() updateMany()方法
- updateOne()
db.collection.updateOne(
<filter>, //修改条件
<update>, //修改内容
{
upsert: <boolean>, //没有的话就插入
writeConcern: <document>, //写入策略,暂时不做解读
collation: <document>, //Collation特性允许MongoDB的用户根据不同的语言定制排序规则
arrayFilters: [ <filterdocument1>, ... ]
}
)
db.user.update({_id:ObjectId("5f9297276951ee42b7a44c24")},{$set:{name:"xxx"}})
//执行结果 WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
db.user.update({_id:-1 },{$set:{name:"-1id"}},{ upsert: true })
//执行结果 WriteResult({ "nMatched" : 0, "nUpserted" : 1, "nModified" : 0, "_id" : -1 })
db.user.update({name:"rob"},{$set:{name:"hhhhh"}},{collation: {locale: "zh"}})
//collation 使用,还理解不太清楚
- arrayFilters用法
//数据为以下
db.students.insert([
{ "_id" : 1, "grades" : [ 95, 92, 90 ] },
{ "_id" : 2, "grades" : [ 98, 100, 102 ] },
{ "_id" : 3, "grades" : [ 95, 110, 100 ] }
])
db.students.updateOne(
{ _id:2 },
{ $set: { "grades.$[element]" : 100 } },
{ arrayFilters: [ { "element": { $gte: 100 } } ] } //只更新grades字段中大于100的数
)
执行后 _id为2数据的更新情况为只更新了grades 大于100的
{
"_id" : 2.0,
"grades" : [
98.0,
100.0,
100.0
]
}
- updateMany()
和updateOne()使用方式相同,只是updateMany可以更新多条数据
db.collection.updateMany(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ]
}
)
replaceOne()方法
使用方式和updateOne()一致,只是会替换整条数据
db.collection.replaceOne(
<filter>,
<replacement>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>
}
)
db.user.replaceOne({_id:-1},{_id:-1,nikename:"xxx",age:2}) //执行后,这条数据中再没有name字段了
Delete Operations
- deleteOne()、deleteMany()
db.collection.deleteOne(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
db.collection.deleteMany(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
db.user.deleteOne({name:"hailong"}) //单条
db.user.deleteMany({name:"hailong"}) //满足条件的都删除
mongodb 数据操作CRUD的更多相关文章
- mongodb数据操作(CRUD)
1.数据插入db.集合名.insert() 操作 > use hk switched to db hk > show collections > db.info.insert({&q ...
- Atitti.数据操作crud js sdk dataServiceV3设计说明
Atitti.数据操作crud js sdk dataServiceV3设计说明 1. 增加数据1 1.1. 参数哦说明1 2. 查询数据1 2.1. 参数说明2 3. 更新数据2 3.1. 参数说明 ...
- ADO.NET访问Access(文本数据库)数据操作(CRUD)
1,ADO.NET访问Access(文本数据库)数据操作(CRUD) 2,DatabaseDesign 文本数据库Northwind.mdb 3,/App_Code 3.1,/App_Code/DBC ...
- 笔记-mongodb数据操作
笔记-mongodb数据操作 1. 数据操作 1.1. 插入 db.COLLECTION_NAME.insert(document) 案例: db.inventory.insertOn ...
- EasyUI-datagrid数据展示+MongoDB数据操作
使用EasyUI-datagrid进行数据展示:进行添加,修改,删除操作逻辑代码,数据源来自MongoDB. 一.新建SiteInfo控制器,添加Index页面:http://www.cnblogs. ...
- MongoDB数据操作之删除与游标处理
删除数据(比较常用) 范例:清空infos集合中的内容.表.文档.成员. db.infos.remove({"url":/-/}); 默认情况下都删除,第二个条件设为true,只删 ...
- SQL Server温故系列(1):SQL 数据操作 CRUD 之增删改合
1.插入语句 INSERT INTO 1.1.用 INSERT 插入单行数据 1.2.用 INSERT 插入多行数据 1.3.用 INSERT 插入子查询结果行 1.4.INSERT 小结及特殊字段插 ...
- SQL Server温故系列(2):SQL 数据操作 CRUD 之简单查询
1.查询语句 SELECT 1.1.查询语句的 SELECT 子句 1.2.查询语句的 FROM 子句 1.2.1.内连接查询 INNER JOIN 1.2.2.外连接查询 OUTER JOIN 1. ...
- Mongodb数据操作基础
var mongodb = require('mongodb'); var server = new mongodb.Server('localhost', 27017, {auto_reconnec ...
随机推荐
- python实例文本进度条
简单的文本进度条代码 解析 引入time库 打印一行作为开始 最后也打印一个结束的标签 定义变量等于10,文本进度条大概的宽度是10 使用for循环来模拟进度,for i in range()能够不断 ...
- 学习使用PSTools工具中的psping
目录 初识PsTools psping 1.使用ICMP ping 2.使用TCP ping 3.延迟测试 4.带宽测试 5.同功能的tcping工具 总结 初识PsTools 在工作中我们都 ...
- vue单页面条件下添加类似浏览器的标签页切换功能
在用vue开发的时候,单页面应用程序,而又有标签页这种需求,各种方式实现不了, 从这个 到这个,然后再返回上面那个 因为每个标签页的route不一样,导致组件重新渲染的问题,怎么都不知道如何实现... ...
- Java Web学习(八)RESTful设计
一.RESTful设计风格 REST :指的是一组架构约束条件和原则. RESTful :满足这些约束条件和原则的应用程序或设计就是 . REST 原则 客户端和服务器之间的交互在请求之间是无状态的. ...
- 详细分析 Java 中实现多线程的方法有几种?(从本质上出发)
详细分析 Java 中实现多线程的方法有几种?(从本质上出发) 正确的说法(从本质上出发) 实现多线程的官方正确方法: 2 种. Oracle 官网的文档说明 方法小结 方法一: 实现 Runnabl ...
- 【记】《.net之美》之读书笔记(一) C#语言基础
前言 工作之中,我们习惯了碰到任务就直接去实现其业务逻辑,但是C#真正的一些基础知识,在我们久而久之不去了解巩固的情况下,就会忽视掉.我深知自己正一步步走向只知用法却不知原理的深渊,所以工作之余,一直 ...
- logging模块培训小结
Python自动化课程又上了一节课,每一个自动化框架都涉及到日志的使用,logging模块是Python的一个标准库模块,由标准库模块提供日志记录API的关键好处是所有Python模块都可以使用这个日 ...
- 《C++primerplus》第9章练习题
1.(未使用原书例题)练习多文件组织.在一个头文件中定义一种学生的结构体,存储姓名和年龄,声明三个函数分别用于询问有多少个学生,输入学生的信息和展示学生的信息.在另一个源文件中给出所有函数的定义.在主 ...
- Geography's sum up
1.世界气候: 热带草原气候,热带雨林气候,热带沙漠气候,热带草原气候 温带季风气候,温带大陆性气候,亚热带季风和湿润性气候,温带海洋性气候 寒带气候,高原山地气候. 2.亚洲气候: 1.大陆性气候分 ...
- .NET Standard SDK 样式项目中的目标框架
系列目录 [已更新最新开发文章,点击查看详细] 包表示形式 .NET Standard 引用程序集的主要分发载体是 NuGet 包. 实现会以适用于每个 .NET 实现的各种方式提供. NuG ...