scrapy-redis非多网址采集的使用
问题描述
默认RedisSpider在启动时,首先会读取redis中的spidername:start_urls,如果有值则根据url构建request对象。
现在的要求是,根据特定关键词采集。
例如:目标站点有一个接口,根据post请求参数来返回结果。
那么,在这种情况下,构建request主要的变换就是请求体(body),API接口是不变的。
对于原来通过url构建request的策略就不再适用了。
所以,此时我们需要对相应的方法进行重写。
重写方法
爬虫类需要继承至scrapy_redis.spiders.RedisSpider
start_requests
我需要从数据库拿到关键词数据,然后用关键词构建请求。
此时,我们将关键词看作start_url,将关键词push到redis中
首先,写一个将单个关键词push到redis的方法
push_data_to_redis
def push_data_to_redis(self, data):
"""将数据push到redis"""
# 序列化,data可能是字典
data = pickle.dumps(data)
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
self.server.spush(self.redis_key, data) if use_set else self.server.lpush(self.redis_key, data)
self.redis_key如果没有做任何声明,则默认为 spidername:start_urls
接着重写start_request
def start_requests(self):
if self.isproducer():
# get_keywords 从数据库读关键词的方法
items = self.get_keywords()
for item in items:
self.push_data_to_redis(item)
return super(DoubanBookMetaSpider, self).start_requests()
上述代码中有一个self.isproducer,此方法用于检测当前程序是不是生产者,即向redis提供关键词
isproducer
# (...)
def __init__(self, *args, **kwargs):
self.is_producer = kwargs.pop('producer', None)
super(DoubanBookMetaSpider, self).__init__()
def isproducer(self):
return self.is_producer is not None
# (...)
此方法需要配合scrapy命令行使用,例如:
// 启动一个生产者,producer的参数任意,只要填写了就是True
scrapy crawl myspider -a producer=1
// 启动一个消费者
scrapy crawl myspider
关于scrapy命令行的更多参数,参考文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/shell.html
make_request_from_data
查看RedisMixin中的make_request_from_data
方法注释信息:
Returns a Request instance from data coming from Redis.
根据来源于redis的数据返回一个Request对象
By default,
datais an encoded URL. You can override this method to
provide your own message decoding.默认情况下,
data是已编码的URL链接。您可以将此方法重写为提供您自己的消息解码。
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
将data转为字符串(网站链接字符串),接着调用了 make_requests_from_url,通过url构建request对象
data从哪里来?
查看RedisMixin的next_request方法
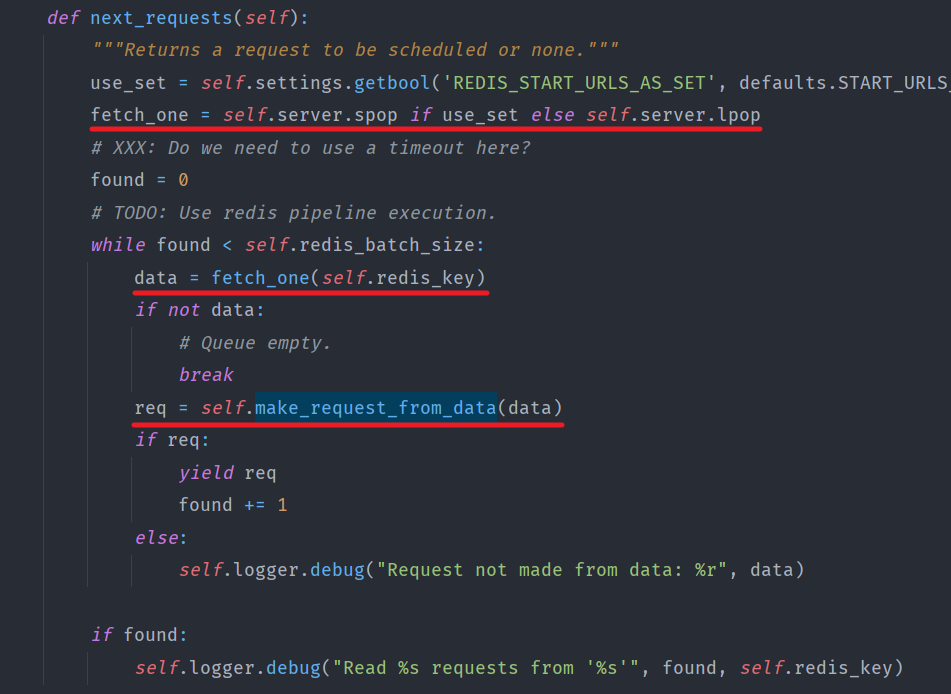
由此得知,data是从redis中pop出来的,在之前我们将data序列化后push进去,现在pop出来,我们将其反序列化并依靠它构建request对象
重写make_request_from_data
def make_request_from_data(self, data):
data = pickle.loads(data, encoding=self.redis_encoding)
return self.make_request_from_book_info(data)
在本例中构建
request对象的方法是self.make_request_from_book_info,在实际开发中,根据目标站请求规则编写构建request的方法即可。
最终效果
启动一个生成者
scrapy crawl myspider -a producer=1
生成者将所有的关键词push完之后,会转为消费者开始消费
在多个节点上启动消费者
scrapy crawl myspider
一个爬虫的开始,总是根据现有数据采集新的数据,例如,根据列表页中的详情页链接采集详情页数据,根据关键词采集搜索结果等等。根据现有数据的不同,开始的方法也不同,大体仍是大同小异的。
scrapy-redis非多网址采集的使用的更多相关文章
- Redis 非关系性数据库集群的搭建与常用方法
redis 非关系型数据库,内存型数据库,现在大家都不陌生了,无论大中小型企业,都会将redis应用到自己的项目中,以此来减轻数据库的压力 安装步骤: 1.安装gcc 安装c语言的编译环境 yum i ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Redis非关系型数据库
1.简介 Redis是一个基于内存的Key-Value非关系型数据库,由C语言进行编写. Redis一般作为分布式缓存框架.分布式下的SESSION分离.分布式锁的实现等等. Redis速度快的原因: ...
- redis非关系型数据库的基本语法
导入并连接数据库: import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 import time # host是redis ...
- 37.scrapy解决翻页及采集杭州造价网站材料数据
1.目标采集地址: http://183.129.219.195:8081/bs/hzzjb/web/list 2.这里的翻页还是较为简单的,只要模拟post请求发送data包含关键参数就能获取下一页 ...
- Redis——非阻塞IO和队列
Redis是个高并发的中间件,但是确实是单线程.而且,Nginx.Node.js等也是单线程的.Redis通过非阻塞IO(IO多路复用)处理那么多的并发客户端连接,并且,由于Redis所有的数据都在内 ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- Redis非关系型缓存数据库集群部署、参数、命令工具
<关系型数据库与非关系型数据库> 关系数据库:mysql.oracle.DB2.SQL Server非关系数据库:Redis(缓存数据库).MongodDB(处理海量数据).Memcach ...
- redis非特定类型命令
1. key查询 keys my* #获取当前数据库中符合模式的所有key exists mykey #查看key是否还存在 2. 数据库操作 redis默认一个实例的数据库是16个[db0-db15 ...
随机推荐
- 初接触matplotlib
1,绘制简单的折线图. 1 import matplotlib.pyplot as plt 2 3 square = [1,4,9,16,25] 4 5 plt.plot(square) 6 plt. ...
- [实用指南]如何使您的旧代码库(遗留代码)符合MISRA C 2012编码规范?
重用旧代码是现实,但是在安全关键型软件项目中重用旧代码并实现MISRA C 2012的完全合规性是艰巨的任务. 最初的MISRA原则是为了在开发代码时应用而创建的,即使文档本身也有警告: " ...
- ASP.NET Core WebAPI实现本地化多语言(单资源文件)
在Startup ConfigureServices 注册本地化所需要的服务AddLocalization和 Configure<RequestLocalizationOptions> p ...
- Java学习_注解
使用注解 注解是放在Java源码的类.方法.字段.参数前的一种特殊"注释". 1 // this is a component: 2 @Resource("hello&q ...
- springmvc 统一处理异常
1.自定义统一异常处理器 自定义Exception实现 HandlerExceptionResolver接口或继承AbstractHandlerExceptionResolver类 1.实现接口Han ...
- JDBC(六)—— 数据库事务
数据库事务 事务 一组逻辑操作单元,使数据从一种状态变换到另一种状态 事务处理 保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式. 当在一个事务中执行多个操作时,要么所有事 ...
- 使用sqoop将mysql数据导入到hive中
首先准备工具环境:hadoop2.7+mysql5.7+sqoop1.4+hive3.1 准备一张数据库表: 接下来就可以操作了... 一.将MySQL数据导入到hdfs 首先我测试将zhaopin表 ...
- TurtleBot3 Waffle (tx2版华夫)(1)笔记本上安装虚拟机、 Ubuntu 系统
1.1虚拟机的安装 1.1.1.windows7系统建议安装14.1版本 VMware workstation 百度云链接: 链接:https://pan.baidu.com/s/1q6Lh9fMuX ...
- JavaScript同步模式,异步模式及宏任务,微任务队列
首先JavaScript是单线程的语言,也就是说JS执行环境中,负责执行代码的线程只有一个.一次只能执行一个任务,如果有多个任务的话, 就要排队,然后依次执行,优点就是更安全,更简单.缺点就是遇到耗时 ...
- 新建虚拟机ping不通windows主机,windows主机ping不通虚拟机解决办法(图文)
说明: 新建虚拟机和主机互ping不通,因此使用xhell等远程连接工具连接不上 解决办法:配置的时候注意网段 2.修改 /etc/sysconfig/network-scripts/ifcfg- ...