Elasticsearch从入门到放弃:浅谈算分
今天来聊一个 Elasticsearch 的另一个关键概念——相关性算分。在查询 API 的结果中,我们经常会看到 _score 这个字段,它就是用来表示相关性算分的字段,而相关性就是描述一个文档和查询语句的匹配程度。
打分的本质其实就是排序,Elasticsearch 会把最符合用户需求的文档排在最前面。
在 Elasticsearch 5.0 之前,相关性算分算法采用的是 TF-IDF 算法,而在5.0之后采用的是 BM 25 算法。听到这也许你会比较疑惑,想知道这两个算法到底是怎么样的。别急,下面我们来具体了解一下。
TF-IDF
首先来看字面意思,TF 是 Term Frequency 的缩写,也就是词频。IDF 是 Inverse Document Frequency 的缩写,也就是逆文档频率。
词频
词频比较好理解,就是要搜索的目标单词在文档中出现的频率。算式为检索词出现的次数除以文档的总字数。最简单的相关性算法就是将检索词进行分词后对他们的词频进行相加。例如,我要搜索“我的算法”,其相关性就可以表示为:
TF(我) + TF(的) + TF(算法)
但这里也有些问题,像“的”这样的词,虽然出现的次数很多,但是对贡献的相关度几乎没有用处。所以在考虑相关度时不应该考虑他们,对于这类词,我们统称为 Stop Word。
逆文档频率
聊完了 TF,我们再来看看 IDF,在了解逆文档频率之前,首先需要知道什么是文档频率,也就是 DF。
DF 其实是检索词在所有文档中出现的频率。例如,“我”在较多的文档中出现,“的”在非常多的文档中都会出现,而“算法”只会在较少的文档中出现。这就是文档频率,那逆文档频率,简单理解就是:
log(全部文档数 / 检索词出现过的文档总数)
针对上面的例子,我们将它更具体的呈现一下。假设我们文档总数为1亿,出现“我”字的文档有5000万,那么它的 IDF 就是 log(2) = 1 。“的”在1亿文档中都有出现,IDF 就是 log(1) = 0,而算法只在20万个文档中出现,那么它的 IDF 就是 log(500) ,大约是8.96。
由此可见,IDF 越大的单词越重要。
好了,现在各位 TF 和 IDF 应该都有一定的了解了,那么 TF-IDF 本质上就是对 TF 进行一个加权求和。
TF(我) * IDF(我) + TF(的) * IDF(的) + TF(算法) * IDF(算法)
BM 25
BM25可以看作是对 TF-IDF 的一个优化,其优化的效果是,当 TF 无限增加时, TF-IDF 的结果会随之增加,而 BM 25 的结果会趋近于一个数值。这就限制了一个 term 对于检索词整体相关性的影响。
BM25算法的公式如下:
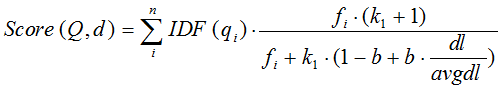
想要详细了解BM25算法的同学可以参考这篇文章BM25 The Next Generation of Lucene Relevance。
Explain API
如果想要了解一个查询是如何进行打分的,我们可以使用 Elasticsearch 提供的 Explain API,其用法非常简单,只需要在参数中增加
"explain": true
也可以在 path 中增加 _explain,例如:
curl -X GET "localhost:9200/my-index-000001/_explain/0?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"match" : { "message" : "elasticsearch" }
}
}
'
这时,返回结果中就会有一个 explanation 字段,用来描述具体的算分过程。
小结
关于 Elasticsearch 的算分,相信各位也有一个初步的认识了,如果感兴趣的话也可以自己进行更加深入的研究,也欢迎各位和我一起交流。
Elasticsearch从入门到放弃:浅谈算分的更多相关文章
- Elasticsearch从入门到放弃:分词器初印象
Elasticsearch 系列回来了,先给因为这个系列关注我的同学说声抱歉,拖了这么久才回来,这个系列虽然叫「Elasticsearch 从入门到放弃」,但只有三篇就放弃还是有点过分的,所以还是回来 ...
- hive从入门到放弃(四)——分区与分桶
今天讲讲分区表和分桶表,前面的文章还没看的可以点击链接: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--DDL数据定义 hive从入门到放弃(三)--DML数据操作 分区 ...
- Elasticsearch从入门到放弃:文档CRUD要牢记
在Elasticsearch中,文档(document)是所有可搜索数据的最小单位.它被序列化成JSON存储在Elasticsearch中.每个文档都会有一个唯一ID,这个ID你可以自己指定或者交给E ...
- Elasticsearch从入门到放弃:索引基本使用方法
前文我们提到,Elasticsearch的数据都存储在索引中,也就是说,索引相当于是MySQL中的数据库.是最基础的概念.今天分享的也是关于索引的一些常用的操作. 创建索引 curl -X PUT & ...
- Elasticsearch从入门到放弃:再聊搜索
在前文中我们曾经聊过搜索文档的方法,Elasticsearch 一般适用于读多写少的场景,因此我们需要更多的关注读操作. Elasticsearch 提供的 Search API 可以分为 URI S ...
- Elasticsearch从入门到放弃:瞎说Mapping
前面我们聊了 Elasticsearch 的索引.搜索和分词器,今天再来聊另一个基础内容-- Mapping. Mapping 在 Elasticsearch 中的地位相当于关系型数据库中的 sche ...
- springcloud 入门 1 (浅谈版本关系)
SpringCloud: 参考官网:https://projects.spring.io/spring-cloud/ 中文版 https://springclou ...
- 浅谈MySQL分表
关于分表:顾名思义就是一张数据量很大的表拆分成几个表分别进行存储. 我们先来大概了解以下一个数据库执行SQL的过程: 接收到SQL --> 放入SQL执行队列 --> 使用分析器分解SQL ...
- STL函数库的应用第四弹——全排列(+浅谈骗分策略)
因为基础算法快学完了,图论又太难(我太蒻了),想慢慢学. 所以暂时不写关于算法的博客了,但又因为更新博客的需要,会多写写关于STL的博客. (毕竟STL函数库还是很香的(手动滑稽)) 请出今天主角:S ...
随机推荐
- python绘制美丽花朵
from mpl_toolkits.mplot3d import Axes3D from matplotlib import cm from matplotlib.ticker import Line ...
- Python自动化办公第三方库xlwt
Python向excel表格写入内容,首先安装第三方库: pip3 install xlwt 代码实例(结合xlrd): #!usr/bin/env python3 #!-*-coding=utf-8 ...
- DateUtils 时间工具类
首先,定义`时间枚举值` public enum TimeEnum { /** * 时间格式 */ YYYY_MM_DD("yyyy-MM-dd"), YYYY_MM_DD_HH_ ...
- Centos8 Docker+Nginx部署Asp.Net Core Nginx正向代理与反向代理 负载均衡实现无状态更新
首先了解Nginx 相关介绍(正向代理和反向代理区别) 所谓代理就是一个代表.一个渠道: 此时就涉及到两个角色,一个是被代理角色,一个是目标角色,被代理角色通过这个代理访问目标角色完成一些任务的过程称 ...
- linux不同环境变量文件的比较,如/etc/profile和/etc/environment
/etc/profile 为系统的每个用户设置环境信息和启动程序,当用户第一次登录时,该文件被执行,其配置对所有登录的用户都有效. 当被修改时,必须重启才会生效.英文描述:"System w ...
- 操作系统微内核和Dubbo微内核,有何不同?
你好,我是 yes. 在之前的文章已经提到了 RPC 的核心,想必一个 RPC 通信大致的流程和基本原理已经清晰了. 这篇文章借着 Dubbo 来说说微内核这种设计思想,不会扯到 Dubbo 某个具体 ...
- JS 获取(期号、当前日期、本周第一天、最后一天及当前月第一、最后天函数)
JS 获取(期号.当前日期.本周第一天.最后一天及当前月第一.最后天函数 /** 2 * 获取当前月期号 3 * 返回格式: YYYY-mm 4 * / 5 function getCurrentMo ...
- Java学习日报7.16
void StudentManage::Sort() //排序功能{ StudentInfo *h,*curr,*temp,*last; h=head; for(int j=0;j<n;j++) ...
- 【Azure Application Insights】在Azure Function中启用Application Insights后,如何配置不输出某些日志到AI 的Trace中
问题描述 基于.NET Core的Function App如果配置了Application Insights之后,每有一个函数被执行,则在Application Insights中的Logs中的tra ...
- 云计算之4---Cockpit
cockpit是一个简单可用的监控工具,你可以添加多个主机进行监控,上限是20台 .也可以使用cockpit来管理虚拟机/容器,也可以安装其他组件开启更多功能. 注意:cockpit没有告警功能,不适 ...