Elasticsearch从入门到放弃:浅谈算分
今天来聊一个 Elasticsearch 的另一个关键概念——相关性算分。在查询 API 的结果中,我们经常会看到 _score 这个字段,它就是用来表示相关性算分的字段,而相关性就是描述一个文档和查询语句的匹配程度。
打分的本质其实就是排序,Elasticsearch 会把最符合用户需求的文档排在最前面。
在 Elasticsearch 5.0 之前,相关性算分算法采用的是 TF-IDF 算法,而在5.0之后采用的是 BM 25 算法。听到这也许你会比较疑惑,想知道这两个算法到底是怎么样的。别急,下面我们来具体了解一下。
TF-IDF
首先来看字面意思,TF 是 Term Frequency 的缩写,也就是词频。IDF 是 Inverse Document Frequency 的缩写,也就是逆文档频率。
词频
词频比较好理解,就是要搜索的目标单词在文档中出现的频率。算式为检索词出现的次数除以文档的总字数。最简单的相关性算法就是将检索词进行分词后对他们的词频进行相加。例如,我要搜索“我的算法”,其相关性就可以表示为:
TF(我) + TF(的) + TF(算法)
但这里也有些问题,像“的”这样的词,虽然出现的次数很多,但是对贡献的相关度几乎没有用处。所以在考虑相关度时不应该考虑他们,对于这类词,我们统称为 Stop Word。
逆文档频率
聊完了 TF,我们再来看看 IDF,在了解逆文档频率之前,首先需要知道什么是文档频率,也就是 DF。
DF 其实是检索词在所有文档中出现的频率。例如,“我”在较多的文档中出现,“的”在非常多的文档中都会出现,而“算法”只会在较少的文档中出现。这就是文档频率,那逆文档频率,简单理解就是:
log(全部文档数 / 检索词出现过的文档总数)
针对上面的例子,我们将它更具体的呈现一下。假设我们文档总数为1亿,出现“我”字的文档有5000万,那么它的 IDF 就是 log(2) = 1 。“的”在1亿文档中都有出现,IDF 就是 log(1) = 0,而算法只在20万个文档中出现,那么它的 IDF 就是 log(500) ,大约是8.96。
由此可见,IDF 越大的单词越重要。
好了,现在各位 TF 和 IDF 应该都有一定的了解了,那么 TF-IDF 本质上就是对 TF 进行一个加权求和。
TF(我) * IDF(我) + TF(的) * IDF(的) + TF(算法) * IDF(算法)
BM 25
BM25可以看作是对 TF-IDF 的一个优化,其优化的效果是,当 TF 无限增加时, TF-IDF 的结果会随之增加,而 BM 25 的结果会趋近于一个数值。这就限制了一个 term 对于检索词整体相关性的影响。
BM25算法的公式如下:
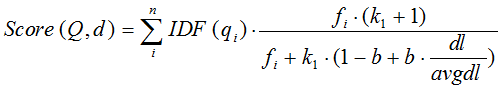
想要详细了解BM25算法的同学可以参考这篇文章BM25 The Next Generation of Lucene Relevance。
Explain API
如果想要了解一个查询是如何进行打分的,我们可以使用 Elasticsearch 提供的 Explain API,其用法非常简单,只需要在参数中增加
"explain": true
也可以在 path 中增加 _explain,例如:
curl -X GET "localhost:9200/my-index-000001/_explain/0?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"match" : { "message" : "elasticsearch" }
}
}
'
这时,返回结果中就会有一个 explanation 字段,用来描述具体的算分过程。
小结
关于 Elasticsearch 的算分,相信各位也有一个初步的认识了,如果感兴趣的话也可以自己进行更加深入的研究,也欢迎各位和我一起交流。
Elasticsearch从入门到放弃:浅谈算分的更多相关文章
- Elasticsearch从入门到放弃:分词器初印象
Elasticsearch 系列回来了,先给因为这个系列关注我的同学说声抱歉,拖了这么久才回来,这个系列虽然叫「Elasticsearch 从入门到放弃」,但只有三篇就放弃还是有点过分的,所以还是回来 ...
- hive从入门到放弃(四)——分区与分桶
今天讲讲分区表和分桶表,前面的文章还没看的可以点击链接: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--DDL数据定义 hive从入门到放弃(三)--DML数据操作 分区 ...
- Elasticsearch从入门到放弃:文档CRUD要牢记
在Elasticsearch中,文档(document)是所有可搜索数据的最小单位.它被序列化成JSON存储在Elasticsearch中.每个文档都会有一个唯一ID,这个ID你可以自己指定或者交给E ...
- Elasticsearch从入门到放弃:索引基本使用方法
前文我们提到,Elasticsearch的数据都存储在索引中,也就是说,索引相当于是MySQL中的数据库.是最基础的概念.今天分享的也是关于索引的一些常用的操作. 创建索引 curl -X PUT & ...
- Elasticsearch从入门到放弃:再聊搜索
在前文中我们曾经聊过搜索文档的方法,Elasticsearch 一般适用于读多写少的场景,因此我们需要更多的关注读操作. Elasticsearch 提供的 Search API 可以分为 URI S ...
- Elasticsearch从入门到放弃:瞎说Mapping
前面我们聊了 Elasticsearch 的索引.搜索和分词器,今天再来聊另一个基础内容-- Mapping. Mapping 在 Elasticsearch 中的地位相当于关系型数据库中的 sche ...
- springcloud 入门 1 (浅谈版本关系)
SpringCloud: 参考官网:https://projects.spring.io/spring-cloud/ 中文版 https://springclou ...
- 浅谈MySQL分表
关于分表:顾名思义就是一张数据量很大的表拆分成几个表分别进行存储. 我们先来大概了解以下一个数据库执行SQL的过程: 接收到SQL --> 放入SQL执行队列 --> 使用分析器分解SQL ...
- STL函数库的应用第四弹——全排列(+浅谈骗分策略)
因为基础算法快学完了,图论又太难(我太蒻了),想慢慢学. 所以暂时不写关于算法的博客了,但又因为更新博客的需要,会多写写关于STL的博客. (毕竟STL函数库还是很香的(手动滑稽)) 请出今天主角:S ...
随机推荐
- Maven之继承
这里我还是将通过一个例子来了解一下Maven继承的初步使用配置.还是使用三个工程项目Project-Parent.Project-C和Project-D来进行说明,三个项目关系如下: <?xml ...
- C# 多态virtual标记重写 以及EF6 查询性能AsNoTracking
首先你如果不用baivirtual重写的话,系统默认会为du你加new关键字,他zhi的作用是覆盖,而virtual的关键作用在dao于实现多态 virtual 代表在继承了这个类的子类里面可以使用o ...
- Error:(18) error: '#FFFF782' is incompatible with attribute android:endColor (attr) color. --Android
android studio 编译是报如下错误: Error:(18) error: '#FFFF782' is incompatible with attribute android:endCol ...
- CVE-2017-10271漏洞复现
漏洞描述 Weblogic的WLS Security组件对外提供webservice服务,其中使用了XMLDecoder来解析用户传入的XML数据,在解析的过程中出现反序列化漏洞,导致可执行任意命令. ...
- [leetcode]39combinationsum回溯法找几个数的和为目标值
import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * Given a set of can ...
- [leetcode]103. Binary Tree Zigzag Level Order Traversal二叉树Z字形层序遍历
相对于102题,稍微改变下方法就行 迭代方法: 在102题的基础上,加上一个变量来判断是不是需要反转 反转的话,当前list在for循环结束后用collection的反转方法就可以实现反转 递归方法: ...
- Java学习日报8.6
<构建之法:现代软件工程>读后感 比起一般的教学类书籍,这本书更像是一本传记小说,作者邹欣以自己或者说一些典型的软件工程师为例子,详细介绍了一个软件工程师的工作内容,全书给我的感觉就是以一 ...
- 对于home主页的切换处理
经过测试,发现,在home首页的时候,滑动到某一个位置的时候,如果再点击tabbar中的"购物车"."分类"或者"我的"的时候,再点击到首页 ...
- 废弃fastjson!大型项目迁移Gson保姆级攻略
前言 大家好,又双叒叕见面了,我是天天放大家鸽子的蛮三刀. 在被大家取关之前,我立下一个"远大的理想",一定要在这周更新文章.现在看来,flag有用了... 本篇文章是我这一个多月 ...
- oracle数据库psu升级(本实验是将10.2.0.3.12升级到10.2.0.3.15)
psu升级(本实验是将10.2.0.3.12升级到10.2.0.3.15) 一.解压安装包自定义存放路径为/home/oracle/yjb/psu/10.2.0.3.15cd /home/oracle ...