Hive数据导出的几种方式
在hive的日常使用中,经常需要将hive表中的数据导出来,虽然hive提供了多种导出方式,但是面对不同的数据量、不同的需求,如果随意就使用某种导出方式,可能会导致导出时间过长,导出的结果不满足需求,甚至造成集群资源不必要的浪费。因此本文主要对hive支持的几种导出方式的使用进行整理,并给出每种导出方式的使用场景,便于指导操作者能够选取最佳的导出方式。
- 利用insert overwrite的方式,将查询结果导出到本地或HDFS
(1)导出到本地文件系统
示例如下:
|
insert overwrite local directory '/home/data/' select * from hive_table; |
(2)导出到HDFS
导入到HDFS和导入本地文件类似,去掉HQL语句的LOCAL就可以了。
示例如下:
|
insert overwrite directory '/home/data/' select * from hive_table; |
利用insert overwrite将查询结果导出本地或hdfs的方式可以指定导出的数据格式和字段的分割符,示例如下:
|
insert overwrite local directory '/home/data/' select * from hive_table row format delimited fields terminated by ‘\t’ #字段间用\t分割 stored as textfile; #导出文件的存储格式为textfile |
使用场景:
1) 由于这种方式导出数据时会启动MApReduce任务来完成导出,所以这种方式不适合导出数据量极少的情况,因为数据量很少时也会启MapReduce任务消耗集群资源,且导出速度比不启MapReduce导出方式的速度要慢;
2) 适用于对导出数据格式有要求的场景,如:指定数据文件类型、字段分割符;
3) 这种方式导出的路径只能指定到文件夹,不支持导出到指定的文件中,且在文件夹下可能产生多个文件,并非仅一个文件,所以此方式适用于将数据导出到本地或HDFS目录下,且对存储数据的文件名和文件数量无要求。
- 利用beeline或hive -e执行查询,通过重定向方式将查询结果写到指定的文件中。
使用beeline执行示例:
|
beeline -u jdbc:hive2://hadoop1:10000/default "select * from hive_table" > /home/data/data.txt |
使用hive -e执行示例:
|
hive -e "select * from hive_table" > /home/data/data.txt; |
注:如果追加,使用“>>”重定向到文件中;如果覆盖,使用“>”重定向到文件中。
适用场景:
1)这种方式导出数据时不会启动MapReduce任务,适用于数据量较少的情况;
2)此方式支持指定导出的文件名,导出的结果只能存放到本地,且只生成一个文件,所以适用于将hive数据导出到本地的某个文件中的场景。
3)不支持指定导出文件的分割符。
- 导出到hive到另一个表中
示例如下:
|
insert into table new_table select * from hive_table; |
适用场景:适用于将导出的结果存放到另一张hive表中,便于通过sql做二次分析。
- 使用export导出
示例如下:
|
export table hive_table to '/home/data/'; |
适用场景:这种方式只能导出数据到HDFS上,但是导出的速度比较快,因此适用于hive数据的批量迁移。
- 拷贝文件
将hive数据拷贝到HDFS示例:
|
hdfs dfs -cp /user/hive/warehouse/hive_table /home/data/; |
将hive数据保存到本地:
|
hdfs dfs -get /user/hive/warehouse/hive_table /home/data/; |
使用场景:适用于数据文件恰好是用户需要的格式,只需要拷贝文件或文件夹就可以。
- 通过sqoop将hive表导出到关系型数据库
Sqoop是连接关系型数据库和hadoop的桥梁,主要有两个方面:一是将关系型数据库的数据导入到hadoop及其相关的系统中,如Hive和Hbase;二是将数据从Hadoop系统里抽取并导出到关系型数据库中。这里以将hive数据导入到mysql库为例。
示例如下:
|
./sqoop export \ --connect jdbc:mysql://192.168.0.70:3306/sqooptest \ #数据库连接url --username root \ #数据库用户名 --password 123456 \ #数据库密码 --table person_hive \ #要导入到的关系数据库表 --num-mappers 1 \ #启动N个map来并行导出数据 --export-dir /user/hive/warehouse/sqooptest.db/person #导出hive表数据存储路径 --input-fields-terminated-by "\t" #字段间的分隔符 |
适用场景:这种方式适用于将hive表数据导入到关系数据库中。
以上共整理了6种hive数据导出的方式,每种导出方式都有各自的应用场景,在选择导出方式时,首先应该考虑导出数据的存储位置,主要包括:本地、HDFS、Hive表、关系型数据库;其次是导出数据的存储格式,如果对导出格式有要求,一定要从可以指定数据格式的方式中选;最后是导出的数据量,如果数据量小,避免选择会启MapReduce任务的导出方式,可以减少导出时间。
导出的hive数据时的注意事项:
hive导出时需要需要修改yarn的队列和对输出结果进行压缩。
(1)调整yarn的队列
步骤一:调整主备节点上的默认队列的优先级,调整为10。如图:
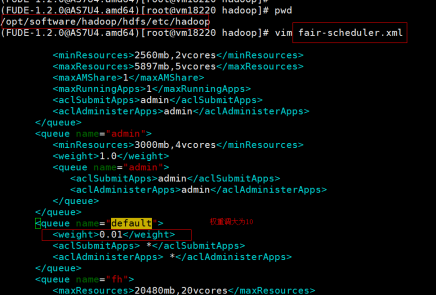
步骤二:在主备节点上执行以下命令:
|
yarn rmadmin -refreshQueues |
(2)在执行语句中加入对结果压缩的配置,配置内容如下:
|
set hive.exec.compress.output=false;set mapred.output.compress=false; |
使用示例如下:
|
hive -e "set hive.exec.compress.output=false;set mapred.output.compress=false;insert overwrite local directory '$dpath' row format delimited fields terminated by '\t' NULL DEFINED AS '' select * from $ttb;" |
Hive数据导出的几种方式的更多相关文章
- Hive创建表|数据的导入|数据导出的几种方式
* Hive创建表的三种方式 1.使用create命令创建一个新表 例如:create table if not exists db_web_data.track_log(字段) partitione ...
- js 实现纯前端将数据导出excel两种方式,亲测有效
由于项目需要,需要在不调用后台接口的情况下,将json数据导出到excel表格,兼容chrome没问题,其他还没有测试过 通过将json遍历进行字符串拼接,将字符串输出到csv文件,输出的文件不会再是 ...
- Hive数据导入导出的几种方式
一,Hive数据导入的几种方式 首先列出讲述下面几种导入方式的数据和hive表. 导入: 本地文件导入到Hive表: Hive表导入到Hive表; HDFS文件导入到Hive表; 创建表的过程中从其他 ...
- Hive数据导入导出的n种方式
Tutorial-LoadingData Hive加载数据的6种方式 #格式 load data [local] inpath '/op/datas/xxx.txt' [overwrite] into ...
- 基于MVC4+EasyUI的Web开发框架经验总结(12)--利用Jquery处理数据交互的几种方式
在基于MVC4+EasyUI的Web开发框架里面,大量采用了Jquery的方法,对数据进行请求或者提交,方便页面和服务器后端进行数据的交互处理.本文主要介绍利用Jquery处理数据交互的几种方式,包括 ...
- 实现web数据同步的四种方式
http://www.admin10000.com/document/6067.html 实现web数据同步的四种方式 1.nfs实现web数据共享 2.rsync +inotify实现web数据同步 ...
- QF——iOS中数据持久化的几种方式
数据持久化的几种方式: 一.属性列表文件: .plist文件是种XML文件.数组,字典都可以和它互相转换.数组和字典可以写入本地变成plist文件.也可以读取本地plist文件,生成数组或字典. 读取 ...
- 数据存储的两种方式:Cookie 和Web Storage
数据存储的两种方式:Cookie 和Web Storage 1.Cookie Cookie的作用就像你去超市购物时,第一次给你办张购物卡,这个购物卡里存放了一些你的个人信息,下次你再来这个连锁超市时, ...
- RecyclerView 数据刷新的几种方式 局部刷新 notify MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
随机推荐
- KEIL5 使用STM32 官方例程
1. 安装keil5,破解 网上很多安装包/教程,跳过 2.下载官方固件库 https://www.st.com/content/st_com/en.html 在这里找微处理器,STM32 stand ...
- Web 页面生命周期 All In One
Web 页面生命周期 All In One Web Page LifeCycle All In One refs xgqfrms 2012-2020 www.cnblogs.com 发布文章使用:只允 ...
- React Testing All in One
React Testing All in One React 测试 https://reactjs.org/docs/testing.html jest 26.4 https://jestjs.io/ ...
- shit 牛客网
shit 牛客网 为什么,只可以 log 一次,什么垃圾逻辑呀! https://www.nowcoder.com/test/question/e46437833ddc4c5bb79f7af7a1b7 ...
- scrimba & interactive free online tutorials
scrimba & interactive free online tutorials https://github.com/scrimba/community/blob/master/FAQ ...
- input support upload excel only
input support upload excel only demo https://codepen.io/xgqfrms/pen/vYONpLB <!-- <input placeh ...
- Masterboxan INC是你靠近财富的最佳选择
Masterboxan INC万事达资产管理有限公司(公司编号:20151264097)是一家国际性资产管理公司,主要提供外汇.证券.投资管理和财富管理等金融服务,其在投资方面一直倡导组合型投资构建稳 ...
- HTML页面顶部出现空白部分(#65279字符?)解决办法
1.在火狐下面用Firebug,选择body,点编辑html的时候,看到是多出了一个这个代表的意思,还真不知道,搜索后了解到是一种中文的编码规则, UTF-8不需要BOM来表明字节顺序. 制作 ...
- Python数据结构与算法_搜索插入位置(07)
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引.如果目标值不存在于数组中,返回它将会被按顺序插入的位置. 你可以假设数组中无重复元素. 示例 1: 输入: [1,3,5,6], 5输出 ...
- Linux/UNIX编程如何保证文件落盘
本文转载自Linux/UNIX编程如何保证文件落盘 导语 我们编写程序write数据到文件中时,其实数据不会立马写入磁盘,而是会经过层层缓存.每层缓存都有自己的刷新时机,每层缓存都刷新后才会写入磁盘. ...