Prometheus集群介绍-1
Prometheus监控介绍
公司做教育的,要迁移上云,所以需要我这边从零开始调研加后期维护Prometheus;近期看过二本方面的prometheus书籍,一本是深入浅出一般是实战方向的;官方文档主要内容大概也都浏览了一遍;在此做个总结;会分几篇内容来写;
本篇从Prometheus的单集群监控开始,介绍包括Prometheus的基本概念,基本原理,基于联邦架构的多集群监控,基于Thanos的多集群监控;
1.Prometheus基本原理
简介
Prometheus是当前最流行的开源多维监控解决方案,集采集,存储,查询,告警于一身。主要用于K8S集群的监控,其拥有强大的PromSQL语句,可进行非常复杂的监控数据聚合计算,且支持关系型聚合。其基本架构如下图所示。
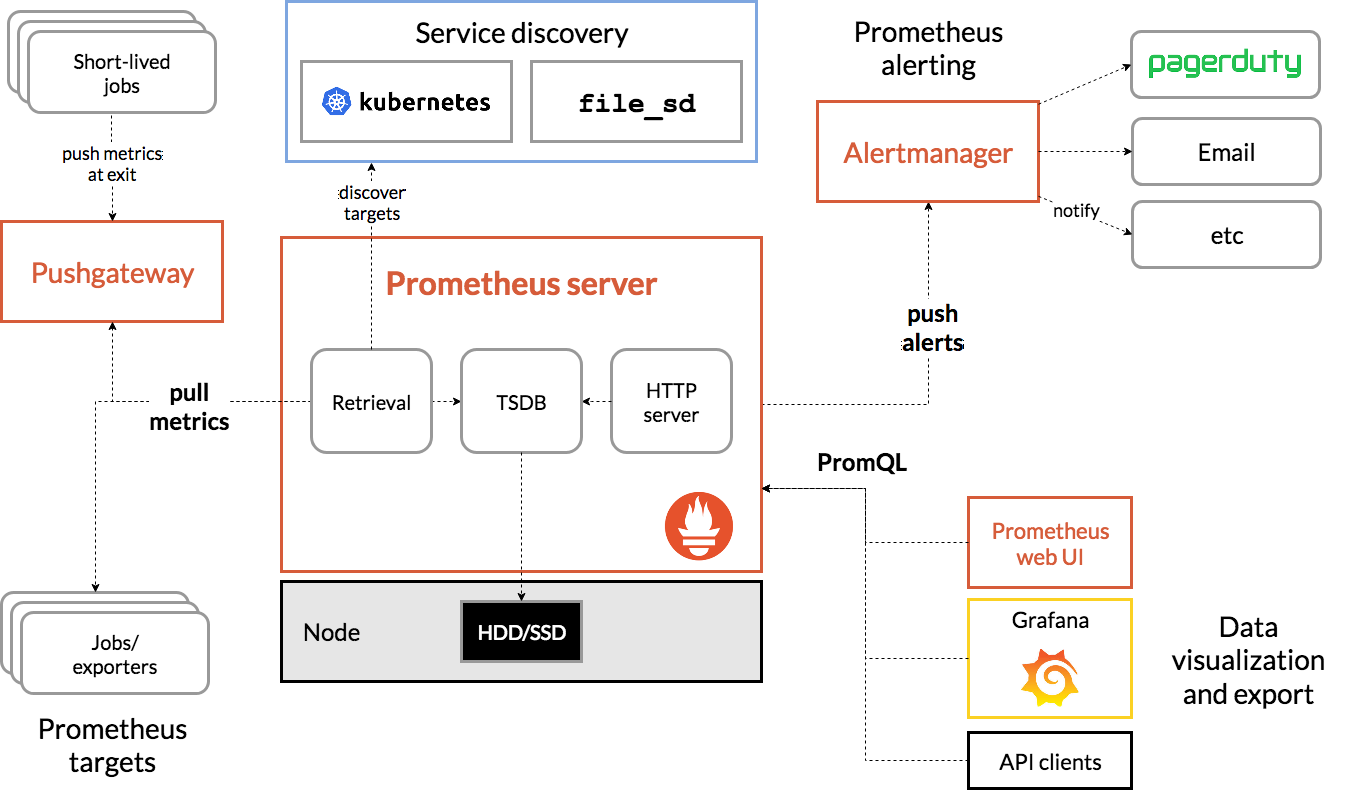
乍一看图可能比较乱,简单说明如下:
- 从配置文件加载采集配置
- 通过服务发现探测有哪些需要抓取的对象,也可以配置静态的
- 周期性得往抓取对象发起抓取请求,得到数据,也就是metrics
- 将数据写入本地盘或者写往远端存储
- push需要发送警报的内容到Alertmanager组件
- 可通过grafana或者自带的webUI展示数据
基本概念
job: Prometheus的采集任务由配置文件中一个个的Job组成,一个Job里包含该Job下的所有监控目标的公共配置,比如使用哪种服务发现去获取监控目标,比如抓取时使用的证书配置,请求参数配置等等。
target: 一个监控目标就是一个target,一个job通过服务发现会得到多个需要监控的target,其包含一些label用于描述target的一些属性。
relabel_configs: 每个job都可以配置一个或多个relabel_config,relabel_config会对target的label集合进行处理,可以根据label过滤一些target或者修改,增加,删除一些label。relabel_config过程发生在target开始进行采集之前,针对的是通过服务发现得到的label集合。
metrics_relabel_configs:每个job还可以配置一个或者多个metrics_relabel_config,其配置方式和relabel_configs一模一样,但是其用于处理的是从target采集到的数据中的label。也就是发送在采集之后;
series(序列):一个series就是指标名+label集合。
head series:Prometheus会将近2小时的series缓存在内测中,称为head series;
基本原理
服务发现:Prometheus周期性得以pull的形式对target进行指标采集,而监控目标集合是通过配置文件中所定义的服务发现机制来动态生成的。也可以静态配置;
relabel:当服务发现得到所有target后,Prometheus会根据job中的relabel_configs配置对target进行relabel操作,得到target最终的label集合。
采集:进行完上述操作后,Prometheus为这些target创建采集循环,按配置文件里配置的采集间隔进行周期性拉取,采集到的数据根据Job中的metrics_relabel_configs进行relabel,然后再加入上边得到的target最终label集合,综合后得到最终的数据。
存储:Prometheus不会将采集到的数据直接落盘,而是会将近2小时的series缓存在内测中,2小时后,Prometheus会进行一次数据压缩,将内存中的数据落盘。
流程:服务发现 ==> targets ==> relabel ==> 抓取 ==> metrics_relabel ==> 缓存 ==> 2小时落盘
2.单集群监控方案
我现在用的就是单机群监控方案,后面多机房后,会用多集群监控方案;
对于单个集群,有几个主流的指标来源方式,于以下几个组件,Prometheus将从他们获取数据。
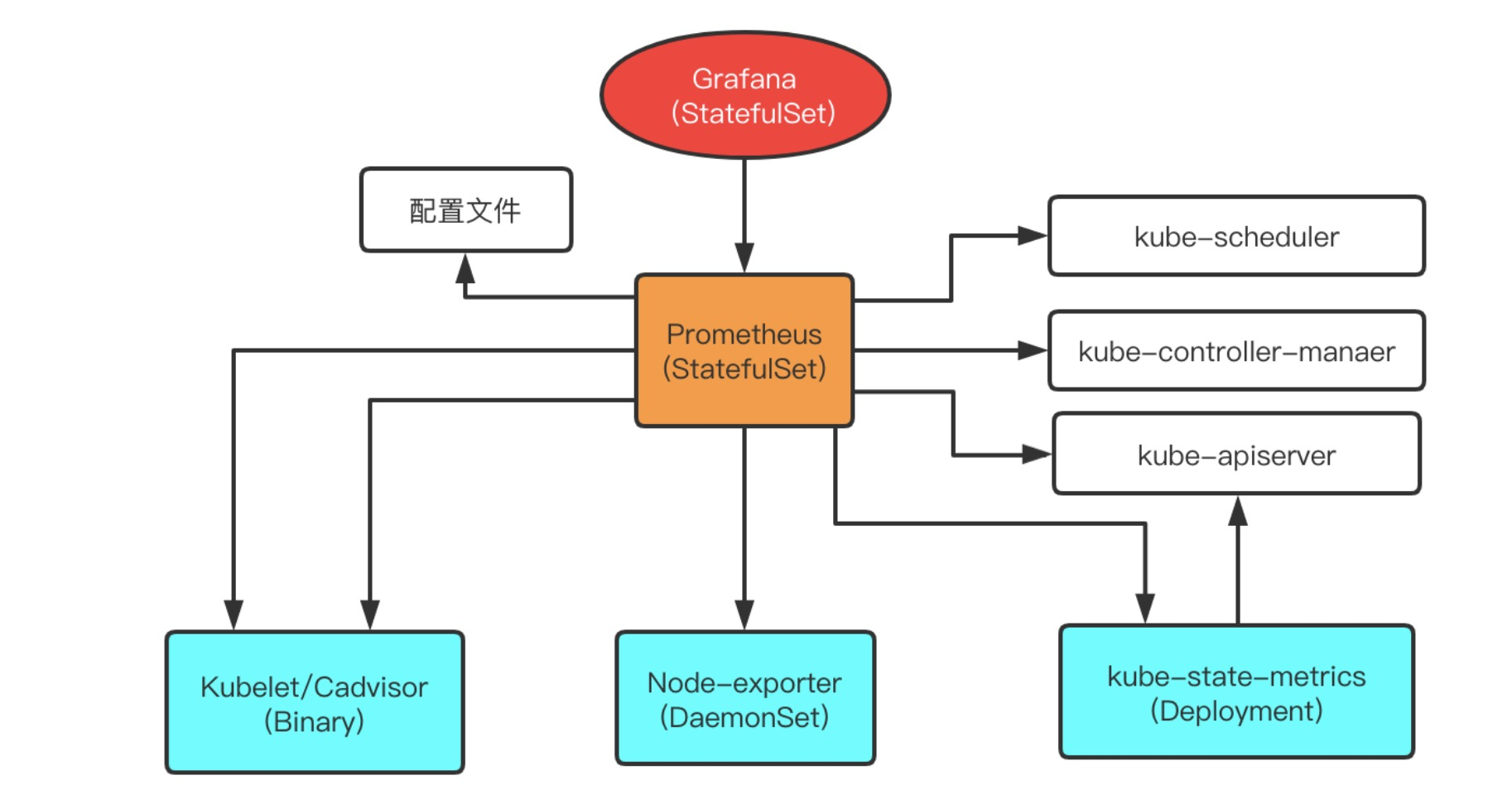
Kube-state-metrics: 通过watch API Server生成资源对象的状态指标,比如Deployment、Pod、Service等,然后Prometheus进行采集;
metrics-server:metrics-server 一个集群范围内的资源数据聚合工具,是 Heapster 的替代品,比如kube-controller-manager状态信息;
Node-exporter: 用于监控K8s节点的基本状态,这个组件以DeamonSet的方式部署,每个节点一个,用于提供节点相关的指标,比如节点的cpu使用率,内存使用率等等;
Cadvisor: 这个组件目前已经整合到kubelet中了,它提供的是每个容器的运行时指标,比如一个容器的cpu使用率,内存使用率等等;
kube-state-metrics 主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等
metrics-server 主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标。
单机群部署架构
单集群架构非常简单,如图所示。使用这种方式,就可以将集群的节点,组件,资源状态,容器运行时状态都给监控起来;
3. 多集群场景的特点
如果我们现在有多个集群,并希望他们的监控数据存储到一起,可以进行聚合查询,用上述部署方案显然是不够的,因为上述方案中的Prometheus只能识别出本集群内的被监控目标,即服务发现无法跨集群。另外就是网络限制,多个集群之间的网络有可能是不通的,这就使得即使在某个集群中知道另一个集群的target地址,也没法去抓取数据。总结多集群的特点主要有:
- 服务发现隔离
- 网络隔离
那只用Prometheus能解决吗?
答案其实是能,用联邦。
Prometheus支持拉取其他Prometheus的数据到本地,称为联邦机制。这样我们就可以在每个集群内部署一个Prometheus,再在他们之上部署一个Top Prometheus,用于拉取各个集群内部的Prometheus数据进行汇总。
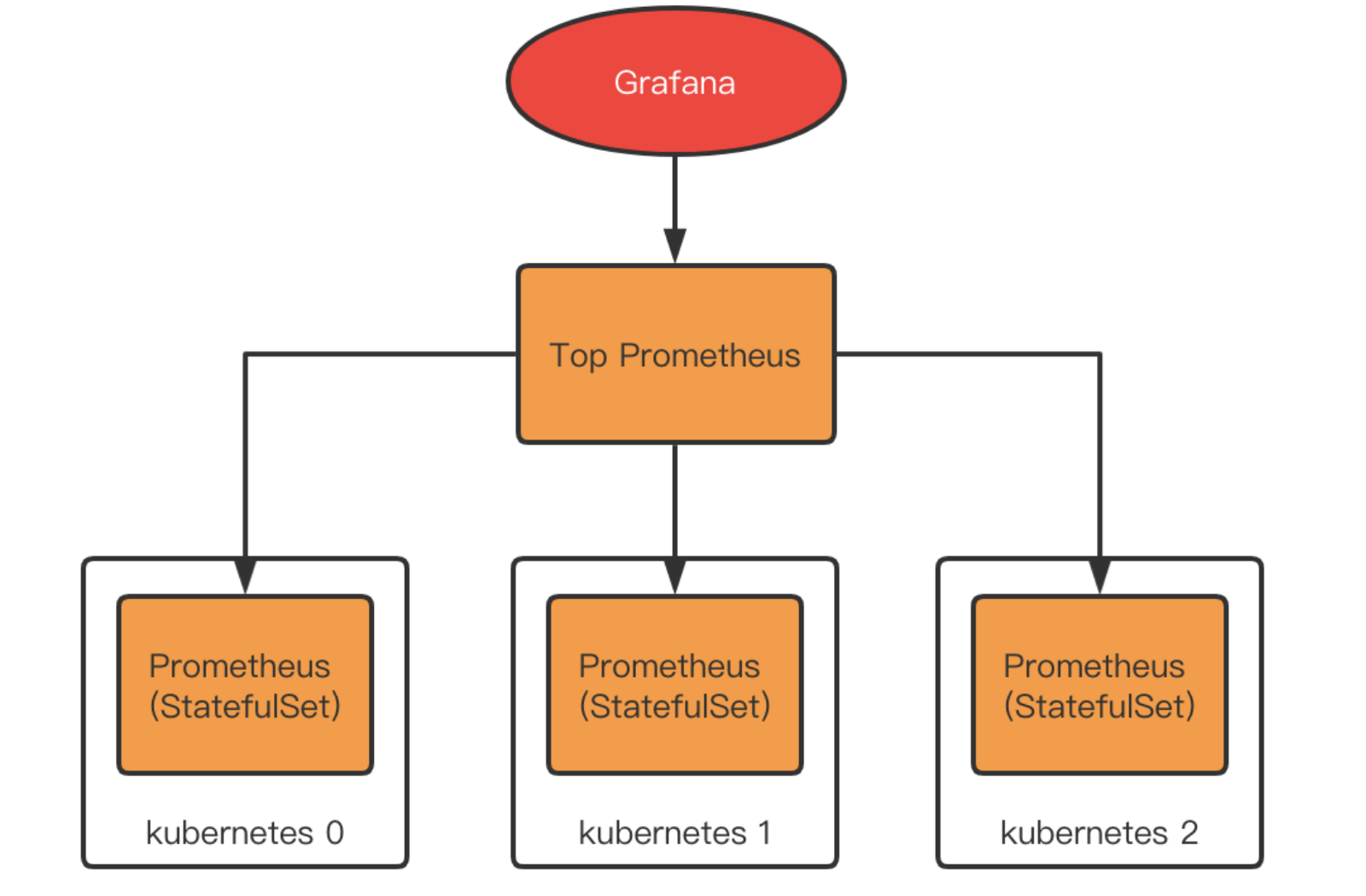
联邦的问题在哪?
联邦的方案其实也是社区所认可的,在集群规模普遍较小,整体数据量不大的情况下,联邦的方案部署简单,理解成本低,没有其他组件的引入,是一个很不错的选择。
但是联邦也有其问题。由于所有数据最终都由Top Prometheus进行存储,当总数据量较大的时候,Top Prometheus的压力将增大,甚至难抗重负,另外,每个集群中的Prometheus实际上也会保存数据(Prometheus2.x 不支持关闭本地存储),所以实际上出现了数据无意义冗余。总结而言,联邦的问题主要是。
- Top Prometheus压力大
- 数据有无意义冗余
4.用Thanos实现多集群监控
Thanos简介
Thanos 是一款开源的Prometheus 高可用解决方案,其支持从多个Prometheus中查询数据并进行汇总和去重,并支持将Prometheus本地数据传送到云上对象存储进行长期存储。官方架构图如下:
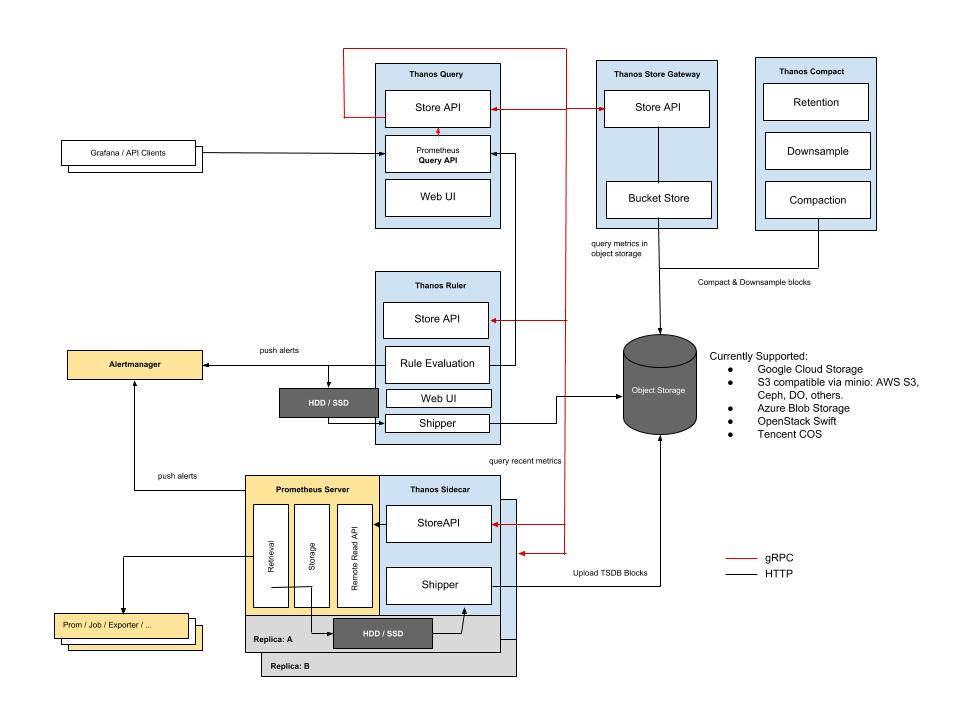
- Query: query代理Prometheus作为查询入口,他会去所有Prometheus,Store, 以及 Ruler查询数据,汇总并去重。
- Sidecar:将数据上传到对象存储,也负责接收Thanos query的查询请求。
- Ruler:进行数据的预聚合及告警。
- Store:负责从对象存储中查询数据。
简化版本图:

部署方案
使用Thanos来替代联邦方案,我们只需要将上图中的Prometheus和Thanos sidecar部署到Kubernetes集群中,将Thano query等组件部署在原来Top Prometheus的位置即可。

相比联邦的优势
使用Thanos相比于之前使用联邦,拥有一些较为明显的优势
- 由于数据不再存储在单个Prometheus中,所以整体能承载的数据规模比联邦大。
- 数据不再有不必要的冗余。
- 由于Thanos有去重能力,实际上可以每个集群中部署两个Prometheus来做数据多副本。
- 可以将数据存储到对象存储中,相比存储在本地,能支持更长久的存储。
5.总结
我们首先介绍了Prometheus的基本原理,并介绍了最为常用的使用Prometheus监控单一小集群的方案。
随后,针对多集群场景,我们还谈了联邦方式与Thanos方式各有什么优缺点。
后续我应该还会分享下三篇内容
- 1.Prometheus具体的配置说明;
- 2.Prometheus-operator部署prometheus集群;
- 3.Grafana面板展示以及PromQL语法查询;
Prometheus集群介绍-1的更多相关文章
- 集群介绍 keepalived介绍 用keepalived配置高可用集群
集群介绍 • 根据功能划分为两大类:高可用和负载均衡 • 高可用集群通常为两台服务器,一台工作,另外一台作为冗余,当提供服务的机器宕机,冗余将接替继续提供服务 • 实现高可用的开源软件有:heartb ...
- nginx 集群介绍
nginx 集群介绍 完成一次请求的步骤 1)用户发起请求 2)服务器接受请求 3)服务器处理请求(压力最大) 4)服务器响应请求 缺点:单点故障 单台服务器资源有限 单台服务器处理耗时长 ·1)部署 ...
- Linux集群介绍、keepalived介绍及配置高可用集群
7月3日任务 18.1 集群介绍18.2 keepalived介绍18.3/18.4/18.5 用keepalived配置高可用集群扩展heartbeat和keepalived比较http://blo ...
- 负载均衡集群介绍、LVS介绍、LVS调度算法、LVS NAT模式搭建
7月4日任务 18.6 负载均衡集群介绍18.7 LVS介绍18.8 LVS调度算法18.9/18.10 LVS NAT模式搭建 扩展lvs 三种模式详解 http://www.it165.net/a ...
- Linux centosVMware 负载均衡集群介绍、LVS介绍、LVS调度算法、LVS NAT模式搭建
一.负载均衡集群介绍 主流开源软件LVS.keepalived.haproxy.nginx等 其中LVS属于4层(网络OSI 7层模型),nginx属于7层,haproxy既可以认为是4层,也可以当做 ...
- Linux centosVMware 集群介绍、keepalived介绍、用keepalived配置高可用集群
一.集群介绍 根据功能划分为两大类:高可用和负载均衡 高可用集群通常为两台服务器,一台工作,另外一台作为冗余,当提供服务的机器宕机,冗余将接替继续提供服务 实现高可用的开源软件有:heartbeat. ...
- Keepalived高可用集群介绍
1.Keepalived服务介绍 Keepalived起初是专为LVS设计的,专门用来监控LVS集群系统中各个服务节点的状态,后来又加入了VRRP的功能,因此除了配合LVS服务外,也可以为其他服务(n ...
- Moebius实现Sqlserver集群~介绍篇
今年是一个不平凡的一年,接触到了很多新艳的,让人兴奋的东西,虽然自己的牙掉了两颗,但感觉自己又年青了两岁,哈哈!进入正题,今年公司开始启用数据库集群,对于Sqlserver来说,实现方式并不是很多,一 ...
- 基于Kubernetes的WAF集群介绍
Kubernetes是Google开源的容器集群管理系统.它构建Docker技术之上,为容器化的应用提供资源调度.部署运行.服务发现.扩容缩容等整一套功能,可看作是基于容器技术的PaaS平台. 本文旨 ...
随机推荐
- JVM命令手册
原文链接:https://blog.csdn.net/qq_41345773/article/details/93895532 aconst_null 将null对象引用压入栈iconst_m1 将i ...
- Kruskal重构树——[NOI2018] 归程
题目链接: UOJ LOJ 感觉 Kruskal 重构树比较简单,就不单独开学习笔记了. Statement 给定一个 \(n\) 点 \(m\) 边的无向连通图,用 \(l,a\) 描述一条边的长度 ...
- Python排序函数用法
Python排序函数完美体现了Python语言的简洁性,对于List对象,我们可以直接调用sort()函数(这里称为"方法"更合适)来进行排序,而对于其他可迭代对象(如set,di ...
- day108:MoFang:首页检测用户是否登录&在项目中使用MongoDB&用户页面更新用户信息&交易密码界面实现
目录 1.首页页面也要检测用户是否登录 2.在flask中使用MongoDB 3.用户页面更新用户信息 4.交易密码界面/密码修改界面/昵称修改界面初始化 5.交易密码实现 1.首页页面也要检测用户是 ...
- 精尽Spring MVC源码分析 - 调式环境搭建
该系列文档是本人在学习 Spring MVC 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释 Spring MVC 源码分析 GitHub 地址 进行阅读 Spring 版本:5.2. ...
- git+pycharm结合使用
Pycharm + git 进行结合使用 第一步:Pycharm配置本地安装的Git 测试框架的负责人: 编写好一套能用的基础框架代码 --- > 上传到公司远程仓库 --- 设置团队协作成员 ...
- 【opencv】学习笔记
安装 此笔记仅对python36实用 OpenCV装3.4.1.15 指令:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv ...
- js下 Day01、DOM对象,BOM浏览器对象模型
一.初识DOM 1.什么是DOM?为什么学习DOM 2.DOM是实现js在网页实现交互的关键环节,我们的js代码就是通过DOM的方法来实现对于html内容的操作. 3.认识DOM实现了js和网页结合的 ...
- RabbitMq基本概念理解
RabbitMQ的基本概念 RabbitMQ github项目地址 RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的 消息中间件 ...
- Linux下安装ffmpeg,视频格式转换
下载ffmpeg 从ffmpeg官网:http://ffmpeg.org/download.html 下载最新的ffmpeg安装包,然后通过如下命令解压: 解压 ffmpeg-*.tar.bz2 文件 ...