Elasticsearch java api操作(一)(Java Low Level Rest Client)
一、说明:
一、Elasticsearch提供了两个JAVA REST Client版本:
1、java low level rest client:
低级别的rest客户端,通过http与集群交互,用户需自己编组请求JSON串,及解析响应JSON串。兼容所有Elasticsearch版本。
特点:maven引入
使用介绍: https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-low.html
2、java high rest client:
高级别的REST客户端,基于低级别的REST客户端,增加了编组请求JSON串、解析响应JSON串等相关API,使用的版本需要保存和ES服务一致的版本,否则会有版本问题。
从6.0.0开始加入的,目的是以java面向对象的方式进行请求、响应处理。
每个API支持 同步、异步 两种方式,同步方法之间返回一个结果对象。异步的方法以async为后缀,通过listener参数来通知结果。高级java resy客户端依赖Elasticsearch core pproject
兼容性说明:
依赖jdk1.8和Elasticsearch core project
二、Java Low Level Rest Client的使用
版本:
Elasticsearch 6.3.1
pom文件:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.3.1</version>
</dependency> <dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.3.1</version>
</dependency> <dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency> <dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>0.9</version>
</dependency>
一、构建elasicsearch client工具类
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import java.net.InetAddress; /**
* @Author: xiaolaotou
* @Date: 2019/4/19
*/ /**
* 构建elasticsrarch client
*/
public class ClientUtil {
private static TransportClient client;
public TransportClient CreateClient() throws Exception {
// 先构建client
System.out.println("11111111111");
Settings settings=Settings.builder()
.put("cluster.name","elasticsearch1")
.put("client.transport.ignore_cluster_name", true) //如果集群名不对,也能连接
.build();
//创建Client
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(
new TransportAddress(
InetAddress.getByName(
"192.168.200.100"),
9300));
return client;
}
}
二、测试类
import net.sf.json.JSONObject;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingRequest;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchType;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.Requests;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHits;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder; /**
* @Author: xiaolaotou
* @Date: 2019/4/19
* ElasticSearch 6.3.1
*/
public class Test { private static TransportClient client; static {
try {
client = new ClientUtil().CreateClient();
} catch (Exception e) {
e.printStackTrace();
}
} public static void main(String[] args) throws Exception { //创建索引
// createEmployee();
//根据inde,type,id查询一个document的data
// FindIndex();
// CreateJsonIndex();
//批量导入
// BulkCreateIndex(); //批量导出
// OutData();
//创建带ik分词的index
// CreateIndexIkTest(); //更新索引
// UpdateIndex();
// createIndex2();
// Search();
get();
} /**
* 创建索引,普通格式
*
* @throws Exception
*/
public static void createEmployee() throws Exception {
IndexResponse response = client.prepareIndex("student", "doc", "1")
.setSource(jsonBuilder()
.startObject()
.field("name", "jack")
.field("age", 27)
.field("position", "technique")
.field("country", "china")
.field("join_date", "2017-01-01")
.field("salary", 10000)
.endObject())
.get();
System.out.println("创建成功!");
}

/**
* 根据 index ,type,id查询
*
* @throws Exception
*/
public static void FindIndex() throws Exception {
GetResponse getResponse = client.prepareGet("student", "doc", "1").get();
System.out.println(getResponse.getSourceAsString());
}

/**
* 创建索引,JSON
*
* @throws IOException
*/
public static void CreateJsonIndex() throws IOException {
JSONObject json = new JSONObject();
json.put("user", "小明");
json.put("title", "Java Engineer");
json.put("desc", "web 开发");
IndexResponse response = client.prepareIndex("studentjson", "doc", "1")
.setSource(json, XContentType.JSON)
.get();
String _index = response.getIndex();
System.out.println(_index);
}
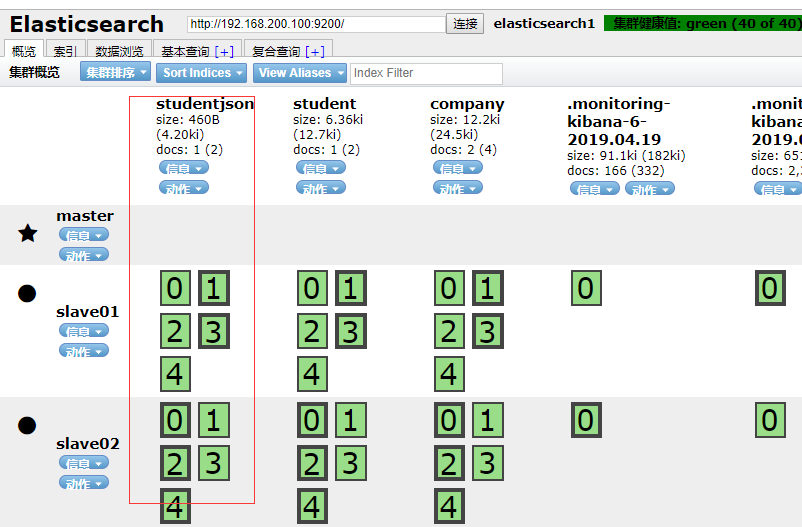
/**
* elasticsearch批量导入
*/
public static void BulkCreateIndex() {
BulkRequestBuilder builder = client.prepareBulk();
for (int i = 0; i < 100000; i++) {
HashMap<String, Object> map = new HashMap<>();
map.put("recordtime", "11");
map.put("area", "22");
map.put("usertype", "33");
map.put("count", 44);
builder.add(client.prepareIndex("bulktest", "1").setSource(map));
//每10000条提交一次
if (i % 10000 == 0) {
builder.execute().actionGet();
builder = client.prepareBulk();
}
}
}

/**
* 批量导出
*/
public static void OutData() throws IOException {
SearchResponse response = client.prepareSearch("bulktest").setTypes("1")
.setQuery(QueryBuilders.matchAllQuery())
.setSize(10000).setScroll(new TimeValue(600000))
.setSearchType(SearchType.DEFAULT).execute().actionGet();
// setScroll(new TimeValue(600000)) 设置滚动的时间
String scrollid = response.getScrollId();
//把导出的结果以JSON的格式写到文件里 //每次返回数据10000条。一直循环查询知道所有的数据都被查询出来
while (true) {
SearchResponse response2 = client.prepareSearchScroll(scrollid).setScroll(new TimeValue(1000000))
.execute().actionGet();
SearchHits searchHit = response2.getHits();
//再次查询不到数据时跳出循环
if (searchHit.getHits().length == 0) {
break;
}
System.out.println("查询数量 :" + searchHit.getHits().length);
for (int i = 0; i < searchHit.getHits().length; i++) {
String json = searchHit.getHits()[i].getSourceAsString();
putData(json);
}
System.out.println("查询结束");
}
}

public static void putData(String json) throws IOException {
String str = json + "\n";
//写入本地文件
String fileTxt = "D:\\data.txt";
File file = new File(fileTxt);
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
if (!file.exists()) {
file.createNewFile();
FileWriter fw = new FileWriter(file, true);
BufferedWriter bw = new BufferedWriter(fw);
System.out.println("写入完成啦啊");
bw.write(String.valueOf(str));
bw.flush();
bw.close();
fw.close();
} else {
FileWriter fw = new FileWriter(file, true);
BufferedWriter bw = new BufferedWriter(fw);
System.out.println("追加写入完成啦啦");
bw.write(String.valueOf(str));
bw.flush();
bw.close();
fw.close();
}
}
/**
* 创建索引,并给某些字段指定ik分词器,以后向该索引中查询时,就会用ik分词
*/
public static void CreateIndexIkTest() throws Exception {
//创建映射
XContentBuilder mapping = XContentFactory.jsonBuilder()
.startObject()
.startObject("properties")
//title:字段名, type:文本类型 analyzer :分词器类型
.startObject("title").field("type", "text").field("analyzer", "ik_smart").endObject() //该字段添加的内容,查询时将会使用ik_smart分词
.startObject("content").field("type", "text").field("analyzer", "ik_max_word").endObject()
.endObject()
.endObject();
//index:索引名 type:类型名(可以自己定义)
PutMappingRequest putmap = Requests.putMappingRequest("index").type("type").source(mapping);
//创建索引
client.admin().indices().prepareCreate("index").execute().actionGet();
//为索引添加映射
client.admin().indices().putMapping(putmap).actionGet();
//调用下面的方法为创建的索引添加内容
CreateIndex1();
}
//这个方法是为上一步创建的索引中添加内容,包括id,id不能重复
public static void CreateIndex1() throws IOException {
IndexResponse response = client.prepareIndex("index", "type", "1") //索引,类型,id
.setSource(jsonBuilder()
.startObject()
.field("title", "title") //字段,值
.field("content", "content")
.endObject()
).get();
}

/**
* 更新索引
*/
//更新索引,更新刚才创建的索引,如果id相同将会覆盖掉刚才的内容
public static void UpdateIndex() throws Exception {
//每次添加id应该不同,相当于数据表中的主键,相同的话将会进行覆盖
UpdateResponse response=client.update(new UpdateRequest("index","type","1")
.doc(XContentFactory.jsonBuilder()
.startObject()
.field("title","中华人民共和国国歌,国歌是最好听的歌")
.field("content","中华人民共和国国歌,国歌是最好听的歌")
.endObject()
)).get();
} //再插入一条数据
public static void createIndex2() throws IOException {
IndexResponse response = client.prepareIndex("index", "type", "2")
.setSource(jsonBuilder()
.startObject()
.field("title", "中华民族是伟大的民族")
.field("content", "中华民族是伟大的民族")
.endObject()
).get();
} /**
* 下面使用index索引下的2个document进行查询
*/
public static void Search(){
SearchResponse response1 = client.prepareSearch( "index") //指定多个索引
.setTypes("type") //指定类型
.setSearchType(SearchType.QUERY_THEN_FETCH)
.setQuery(QueryBuilders.matchQuery("title", "中华人民共和国国歌")) // Query
// .setPostFilter(QueryBuilders.rangeQuery("age").from(12).to(18)) // Filter
.setFrom(0).setSize(60).setExplain(true)
.get();
long totalHits1= response1.getHits().totalHits; //命中个数
System.out.println("response1======="+totalHits1); SearchResponse response2 = client.prepareSearch( "index") //指定多个索引
.setTypes("type") //指定类型
.setSearchType(SearchType.QUERY_THEN_FETCH)
.setQuery(QueryBuilders.matchQuery("content", "中华人民共和国国歌")) // Query
// .setPostFilter(QueryBuilders.rangeQuery("age").from(12).to(18)) // Filter
.setFrom(0).setSize(60).setExplain(true)
.get();
long totalHits2 = response2.getHits().totalHits; //命中个数
System.out.println("response2========="+totalHits2);
} /**
* GET操作
*/
public static void get() {
GetResponse response = client.prepareGet("index", "type", "2").get();
Map<String, Object> source = response.getSource();
Set<String> strings = source.keySet();
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()) {
System.out.println(source.get(iterator.next()));
}
}
}
Elasticsearch java api操作(一)(Java Low Level Rest Client)的更多相关文章
- 使用Java Low Level REST Client操作elasticsearch
Java REST客户端有两种风格: Java低级别REST客户端(Java Low Level REST Client,以后都简称低级客户端算了,难得码字):Elasticsearch的官方low- ...
- Elasticsearch java api操作(二)(Java High Level Rest Client)
一.说明: 一.Elasticsearch提供了两个JAVA REST Client版本: 1.java low level rest client: 低级别的rest客户端,通过http与集群交互, ...
- MongoDB Java API操作很全的整理
MongoDB 是一个基于分布式文件存储的数据库.由 C++ 语言编写,一般生产上建议以共享分片的形式来部署. 但是MongoDB官方也提供了其它语言的客户端操作API.如下图所示: 提供了C.C++ ...
- hive-通过Java API操作
通过Java API操作hive,算是测试hive第三种对外接口 测试hive 服务启动 package org.admln.hive; import java.sql.SQLException; i ...
- hadoop2-HBase的Java API操作
Hbase提供了丰富的Java API,以及线程池操作,下面我用线程池来展示一下使用Java API操作Hbase. 项目结构如下: 我使用的Hbase的版本是 hbase-0.98.9-hadoop ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- Kafka系列三 java API操作
使用java API操作kafka 1.pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xs ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
- zookeeper的java api操作
zookeeper的java api操作 创建会话: Zookeeper(String connectString,int sessionTimeout,Watcher watcher) Zookee ...
随机推荐
- 【APIO2019】路灯(ODT & (树套树 | CDQ分治))
Description 一条 \(n\) 条边,\(n+1\) 个点的链,边有黑有白.若结点 \(a\) 可以到达 \(b\),需要满足 \(a\to b\) 的路径上的边不能有黑的.现给出 \(0\ ...
- Oracle 迁移数据库到 mysql
一. oracle导出.sql文件(Navicat Premiu 11.0.8 无法实现oracle到mysql的数据传输亲测有效) exp username/pass@数据局地址ip:1521/ ...
- elasticsearch的基本了解
以下内容参考官方文档https://www.elastic.co/guide/en/elasticsearch/reference/7.2/elasticsearch-intro.html 使用的学 ...
- 【ubantu下安装python3.6】
Ubuntu16.04默认安装了Python2.7和3.5 请注意,系统自带的python千万不能卸载! 输入命令python
- 四、Jmeter安装插件
Jmeter安装插件方法和使用 1-下载Jmeter管理jar包 下载地址:https://jmeter-plugins.org/install/Install/ 2-点击下载 plugins-man ...
- 前端使用canvas生成盲水印的加密解密
为了保障信息安全,防止重大信息泄露,并且能够锁定泄露用户,需要对页面展示的图片加入当前用户信息的盲水印,即最终图片外观看起来和原图一样,但是经过解码以后可以识别出水印信息,并且在截图后仍能进行较好的识 ...
- 一个java文件被执行的历程
学习java以来,都是以语法,类库入手,最基本的也是最基础的java编译过程往往被我遗忘,先解释一下学习java第一课时,都听到过的一句话,"java是半解释语言".什么是半解释语 ...
- Oracle数据导入Mysql中
一.Navicat Premium中的数据迁移工具 为了生产库释放部分资源,需要将API模块迁移到mysql中,及需要导数据. 尝试了oracle to mysql工具,迁移时报错不说,这么大的数据量 ...
- Windows下anaconda换源和pip换源
换源解决下载安装速度慢的问题. 1. anaconda换源 打开cmd命令行,输入 conda config --set showchannelurls yes 会在C:\Users\xx文件夹下生成 ...
- 移动端SCSS
一.什么是SASS SASS是一种强化CSS的辅助工具,提供了许多便利的写法,大大节省了设计者的时间,使得CSS的开发,变得简单可维护. #二.安装和使用(VS Code中) #1.安装 下载扩展文件 ...