(二)数据源处理6-excel数据转换实战(下)
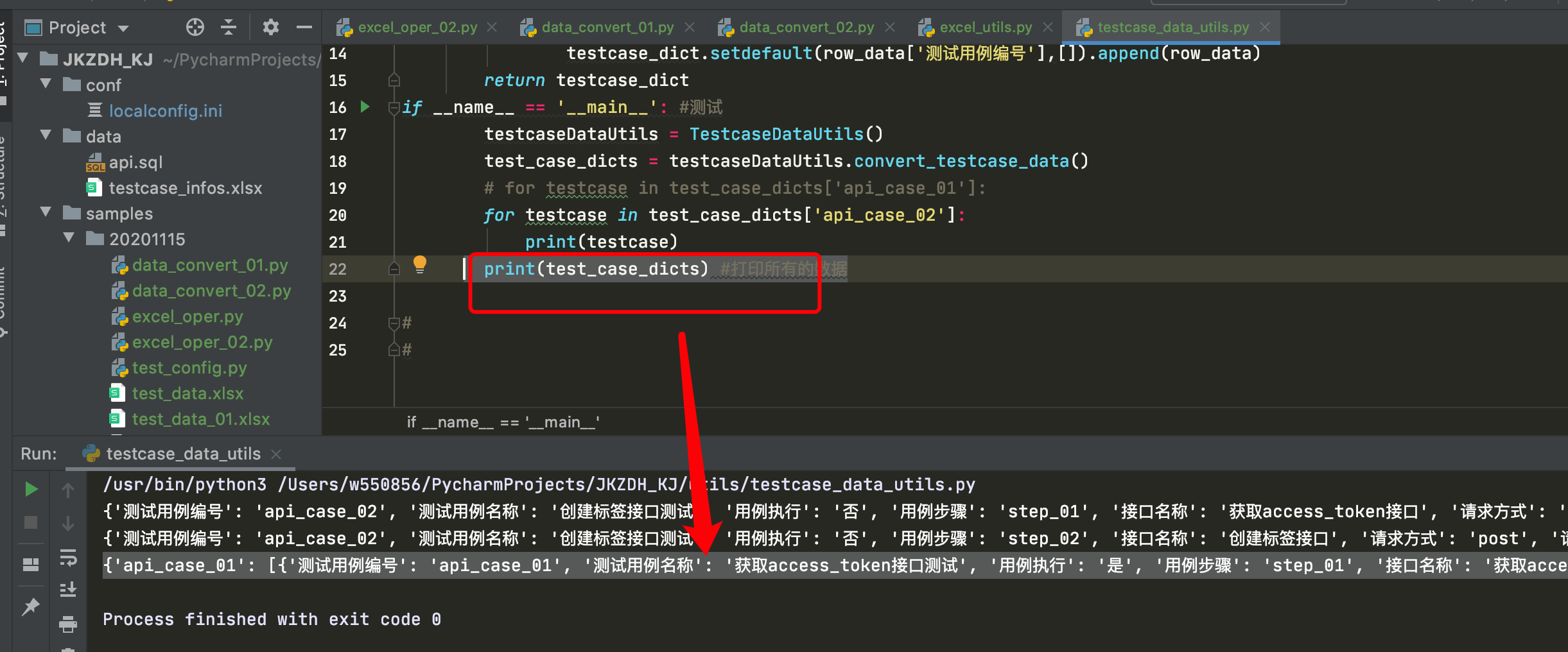
将结果的所有数据整理如下:
{'api_case_01':
[{'测试用例编号': 'api_case_01', '测试用例名称': '获取access_token接口测试', '用例执行': '是', '用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wx55614004f367f8ca","secret":"65515b46dd758dfdb09420bb7db2c67f"}', '请求参数(post)': '', '取值方式': '无', '取值代码': '', '取值变量': '', '断言类型': 'body_regexp', '期望结果': '"access_token":"(.+?)"'
}],
'api_case_02':
[{'测试用例编号': 'api_case_02', '测试用例名称': '创建标签接口测试', '用例执行': '否', '用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wx55614004f367f8ca","secret":"65515b46dd758dfdb09420bb7db2c67f"}', '请求参数(post)': '', '取值方式': '正则取值', '取值代码': '"access_token":"(.+?)"', '取值变量': 'token', '断言类型': 'json_key_value', '期望结果': '{"expires_in":7200}'},
{'测试用例编号': 'api_case_02', '测试用例名称': '创建标签接口测试', '用例执行': '否', '用例步骤': 'step_02', '接口名称': '创建标签接口', '请求方式': 'post', '请求头部信息': '', '请求地址': '/cgi-bin/tags/create', '请求参数(get)': '{"access_token":${token}}', '请求参数(post)': '{ "tag" : { "name" : "广东" } } ', '取值方式': '无', '取值代码': '', '取值变量': '', '断言类型': 'json_key', '期望结果': 'tag'
}],
'api_case_03':
[{'测试用例编号': 'api_case_03', '测试用例名称': '删除标签接口测试', '用例执行': '否', '用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wx55614004f367f8ca","secret":"65515b46dd758dfdb09420bb7db2c67f"}', '请求参数(post)': '', '取值方式': 'jsonpath取值', '取值代码': '$.access_token', '取值变量': 'token', '断言类型': 'json_key', '期望结果': 'access_token'},
{'测试用例编号': 'api_case_03', '测试用例名称': '删除标签接口测试', '用例执行': '否', '用例步骤': 'step_02', '接口名称': '创建标签接口', '请求方式': 'post', '请求头部信息': '', '请求地址': '/cgi-bin/tags/create', '请求参数(get)': '{"access_token":${token}}', '请求参数(post)': '{ "tag" : { "name" : "p3p4testddd" } } ', '取值方式': '正则取值', '取值代码': '"id":(.+?),', '取值变量': 'tag_id', '断言类型': 'json_key', '期望结果': ''},
{'测试用例编号': 'api_case_03', '测试用例名称': '删除标签接口测试', '用例执行': '否', '用例步骤': 'step_03', '接口名称': '删除标签接口', '请求方式': 'post', '请求头部信息': '', '请求地址': '/cgi-bin/tags/delete', '请求参数(get)': '{"access_token":${token}}', '请求参数(post)': '{ "tag":{ "id" : ${tag_id} } }', '取值方式': '无', '取值代码': '', '取值变量': '', '断言类型': 'json_key_value', '期望结果': '{"errcode":0}'}
]
}
思路分析:转化为:
‘case_id':‘api_case_01','case_info':[{'测试用例编号': 'api_case_01', '测试用例名称': '获取access_token接口测试', '用例执行': '是', '用例步骤': 'step_01', '接口名称': '获取access_token接口', '请求方式': 'get', '请求头部信息': '', '请求地址': '/cgi-bin/token', '请求参数(get)': '{"grant_type":"client_credential","appid":"wx55614004f367f8ca","secret":"65515b46dd758dfdb09420bb7db2c67f"}', '请求参数(post)': '', '取值方式': '无', '取值代码': '', '取值变量': '', '断言类型': 'body_regexp', '期望结果': '"access_token":"(.+?)"'
}]

例:
data_convert_02.py
a_dict = {'小红':[{'book1':'朝花夕拾'},{'book2':'红楼梦'}],
'小黑':[{'book1':'呐喊'},{'book2':'红楼梦'}]}
data_list = []
for key,value in a_dict.items():#同时返回键和值,a_dict.key返回key,a_dict.value返回value
b_dict = {}
b_dict['name'] = key
b_dict['books'] = value
data_list.append(b_dict)
print( data_list )

转换封装:
# import os
# from utils.excel_utils import ExcelUtils
# excel_file_path = os.path.join( os.path.dirname(__file__),'..','data','testcase_infos.xlsx')
# excel_sheet_name = 'Sheet1'
#
# class TestcaseDataUtils:
# def __init__(self):
# self.excel_data = ExcelUtils(excel_file_path=excel_file_path,sheet_name=excel_sheet_name)
#
# def convert_testcase_data(self):
# ''' 把excel的所有原始数据转换成符合框架需要的测试用例业务数据 '''
# testcase_dict = {}
# for row_data in self.excel_data.get_all_data():
# testcase_dict.setdefault(row_data['测试用例编号'],[]).append(row_data)
# return testcase_dict
# if __name__ == '__main__': #测试
# testcaseDataUtils = TestcaseDataUtils()
# test_case_dicts = testcaseDataUtils.convert_testcase_data()
# # for testcase in test_case_dicts['api_case_01']:
# for testcase in test_case_dicts['api_case_02']:
# print(testcase)
# print(test_case_dicts) #打印所有的数据
️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️
import os
from utils.excel_utils import ExcelUtils
# from utils.mysql_utils import MysqlUtils
excel_file_path = os.path.join( os.path.dirname(__file__),'..','data','testcase_infos.xlsx')
excel_sheet_name = 'Sheet1'
class TestcaseDataUtils:
def __init__(self):
self.test_data_obj = ExcelUtils(excel_file_path=excel_file_path,sheet_name=excel_sheet_name)
#self.test_data_obj = MysqlUtils()
def convert_testcase_data_to_dict(self):
''' 把excel的所有原始数据转换成符合框架需要的测试用例业务数据 '''
testcase_dict = {}
for row_data in self.excel_data.get_all_data():
testcase_dict.setdefault(row_data['测试用例编号'],[]).append(row_data)
return testcase_dict
def convert_testcase_data_to_list(self):
''' 把convert_testcase_data_to_dict产生的数据转换成列表并在每个元素中增加key '''
all_casedata_list = []
for key,value in self.convert_testcase_data_to_dict().items():
case_info_dict = {}
case_info_dict['case_id'] = key
case_info_dict['case_step'] = value
all_casedata_list.append( case_info_dict )
return all_casedata_list
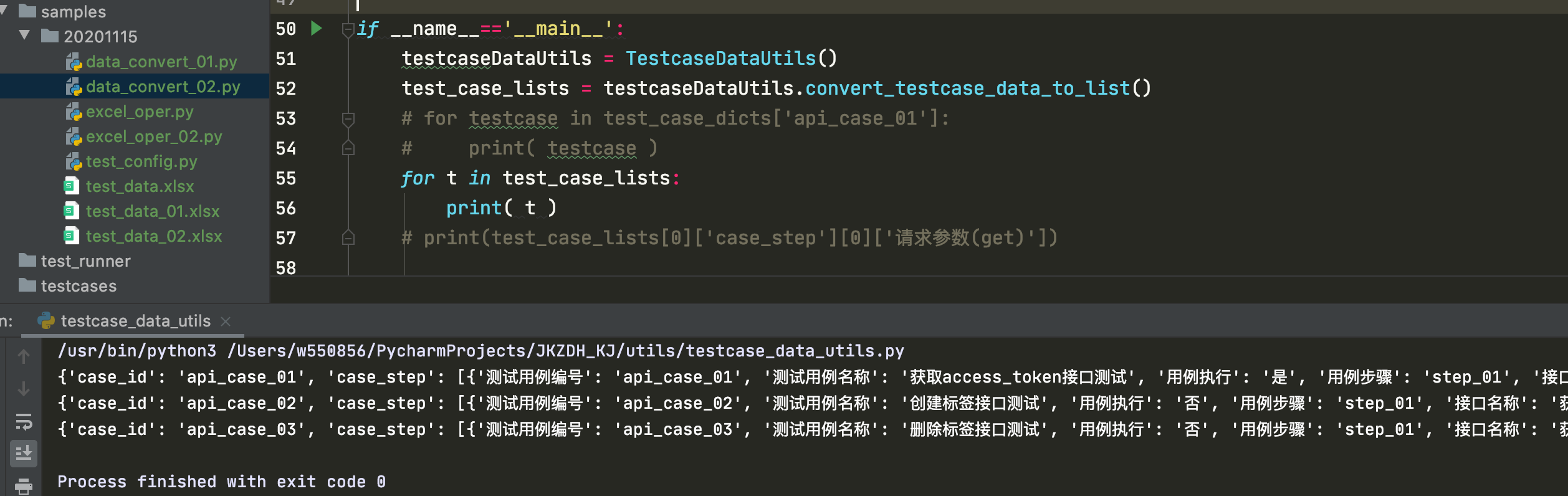
if __name__=='__main__':
testcaseDataUtils = TestcaseDataUtils()
test_case_lists = testcaseDataUtils.convert_testcase_data_to_list()
# for testcase in test_case_dicts['api_case_01']:
# print( testcase )
for t in test_case_lists:
print( t )
#print(test_case_lists[0]['case_step'][0]['请求参数(get)'])

数据源处理:
1、config读取的封装
2、excel存放测试数据转换到代码中的处理
合并单元格 == 》 封装excel_utils == 》把excel数据转换成测试用例业务数据
(setdefault() 为了把用例步骤整合到对应的测试编号中)==》封装testcase_data_utils
==》形态变化:
[{},{}] == {"":[],"":[]} == [{"case_id":'','case_step':[]},...]
(二)数据源处理6-excel数据转换实战(下)的更多相关文章
- (二)数据源处理5-excel数据转换实战(上)
把excel_oper02.py 里面实现的:通过字典的方式获取所有excel数据.放进utils: ️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️️ utils: def get_al ...
- EXCEL设置三级下拉框
EXCEL设置三级下拉框 1.添加下拉框数据源 公式--->指定 公式--->名称管理器 2.设置第一级下拉框的值 3.第一级下拉框选出一个值 4.设置第二级下拉框(INDIRECT($A ...
- EXCEL 如何实现下拉填充公式,保持公式部分内容不变,使用绝对引用
EXCEL 如何实现下拉填充公式,保持公式部分内容不变,使用绝对引用 在不想变的单元格前加$符号(列标和列数,两个都要加$),变成绝对引用,默认情况是相对引用 L4固定不变的方式:$L$4 M4固定不 ...
- 《剑指offer》第三十二题(分行从上到下打印二叉树)
// 面试题32(二):分行从上到下打印二叉树 // 题目:从上到下按层打印二叉树,同一层的结点按从左到右的顺序打印,每一层 // 打印到一行. #include <cstdio> #in ...
- Excel三个下拉互斥
Excel三个下拉互斥 描述:Excel有三个下拉列表,若选择了其中任意一个下拉,其他两个均不可以在选择. 尝试了很多种办法,级联,数据有效性等等,最后都没实现. 老大,最后用VBA实现. 附上代码: ...
- 手把手和你一起实现一个Web框架实战——EzWeb框架(二)[Go语言笔记]Go项目实战
手把手和你一起实现一个Web框架实战--EzWeb框架(二)[Go语言笔记]Go项目实战 代码仓库: github gitee 中文注释,非常详尽,可以配合食用 上一篇文章我们实现了框架的雏形,基本地 ...
- Mac下使用数据库将Excel数据转换存入.plist
记录于2013/10/26 基本步骤: 1.将Excel表格另存为.csv格式 2.用类似TextWrangler工具将.csv文件转成UTF-8格式 3.使用火狐插件SQLite Manager ...
- POI设置excel添加列下拉框
POI在生成excel模板时需要为列添加下拉框,我写了两个方法. @ 方法一:适用任何情况,不受下拉框值数量限制.但是需要通过引用其它列值. 思路大概如下: 1.创建一个隐藏的sheet页,用于存放下 ...
- 手把手带你实战下Spring的七种事务传播行为
目录 本文目录 一.什么是事务传播行为? 二.事务的7种传播行为 三.7种传播行为实战 本文介绍Spring的七种事务传播行为并通过代码演示下. 本文目录 一.什么是事务传播行为? 事务传播行为(pr ...
随机推荐
- Servlet中获取请求参数问题
1.GET方法,可以通过getParamter方法反复获取同一个变量的数据: 2.POST方法,需要注意请求类型(content-Type)是否是application/x-www-form-urle ...
- Linux下基于.NET5开发CAX应用
<<.NET5下的三维应用程序开发>>一文中介绍了如何在.NET5下使用AnyCAD开发应用程序.相比.NET4.x,.NET5一大进步便是可以跨平台,即可以在Linux.Ma ...
- Jmeter(5)JSON提取器
Jmeter后置处理器-JSON提取器 JSON是一种轻量级数据格式,以"键-值"对形式组织数据. JSON串中{}表示对象,[]表示对象组成的数组.对象包含多个"属性& ...
- Android全面解析之Activity生命周期
前言 很高兴遇见你~ 欢迎阅读我的文章. 关于Activity生命周期的文章,网络上真的很多,有很多的博客也都讲得相当不错,可见Activity的重要性是非常高的.事实上,我猜测每个android开发 ...
- 钩子与API截获
http://www.pudn.com/Download/type/id/19.html
- [RoarCTF 2019]Easy Calc
[RoarCTF 2019]Easy Calc 题目 题目打开是这样的 查看源码 .ajax是指通过http请求加载远程数据. 可以发现有一个calc.php,输入的算式会被传入到这个php文件里,尝 ...
- php 文件上传错误
假设文件上传字段的名称img,则: $_FILES['img']['error']有以下几种类型 1.UPLOAD_ERR_OK 其值为 0,没有错误发生,文件上传成功. 2.UPLOAD_ERR_I ...
- Java8 - Stream流:让你的集合变得更简单!
前段时间,在公司熟悉新代码,发现好多都是新代码,全是 Java8语法,之前没有了解过,一直在专研技术的深度,却忘了最初的语法,所以,今天总结下Stream ,算是一份自己理解,不会很深入,就讲讲常用的 ...
- 转载:从输入 URL 到页面加载完的过程中都发生了什么事情?
原帖地址:http://www.guokr.com/question/554991/ 1)把URL分割成几个部分:协议.网络地址.资源路径.其中网络地址指示该连接网络上哪一台计算机,可以是域名或者IP ...
- Core3.0返回的数据格式xml或json
前言 此方法从百度得,原文链接找不到了 步骤 //WebAPI接口返回xml格式,由Accept.application决定 services.AddMvc(opt => { opt.Respe ...