Spark BlockManager的通信及内存占用分析(源码阅读九)
之前阅读也有总结过Block的RPC服务是通过NettyBlockRpcServer提供打开,即下载Block文件的功能。然后在启动jbo的时候由Driver上的BlockManagerMaster对存在于Executor上的BlockManager统一管理,注册Executor的BlockManager、更新Executor上Block的最新信息、询问所需要Block目前所在的位置以及当Executor运行结束时,将Executor移除等等。那么Driver与Executor之间是怎么交互的呢?
在Spark1.6时,Drvier的BlockManagerMaster与BlockManager之间的通信,不再是通过AkkaUtil,而是用了RpcEndpoint,也就木有了BlockManagerMasterActor,而是BlockManagerMasterEndpoint:
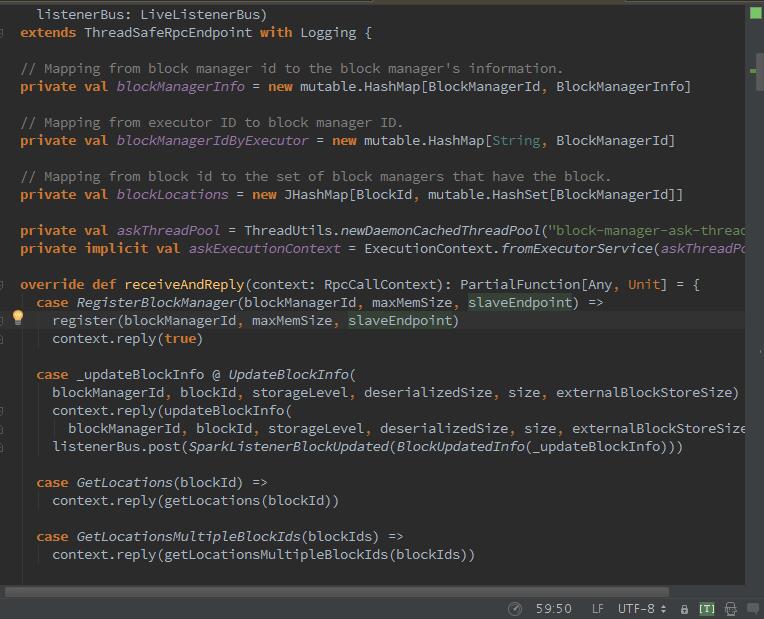
BlockManagerMaster与BlockManager之间的通信已经使用RPC远程过程调用来实现,RPC相关配置参数如下:
spark.rpc.retry.wait 3s(默认)等待时长 、 spark.rpc.numRetries 3(默认)重试次数、spark.rpc.askTimeout 120s(默认)请求时长、spark.rpc.lookupTimeout与spark.network.timeout 120s(默认)查找时长,是要一起配置。
好的,我们继续,每个executor中的BlockManager的创建,都要经过BlockManagerMaster注册BlockManagerId.
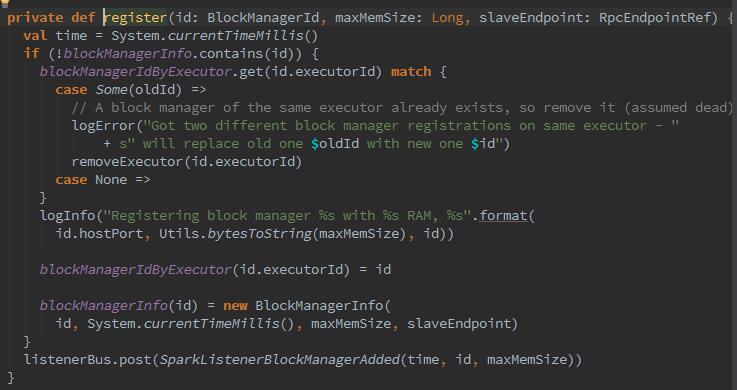
Executor或Driver自身的BlockMnager在初始化时,需要向Driver的BlockManager注册BlockMnager信息,注册的消息内容包括BlockMnagerI的d、时间戳、最大内存、以及slaveEndpoint。带有slaveEndpoint的目的是为了便于接收BlockManagerMaster回复的消息,在register方法执行结束后向发送者BlockManageMaster发送一个简单的消息true.

register方法确保blockManagerInfo持有消息中的blockManagerId及对应消息,并且确保每个Executor最多只能有一个blockManagerId,旧的blockManagerId会被移除。最后向listenerBus中post(推送)一个sparkListenerBlockManagerAdded事件。
那么下来,开始磁盘管理器DiskBlockManager的构造:
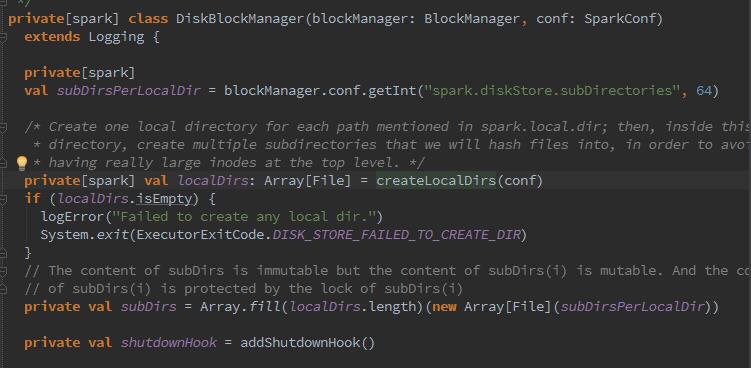
我们可以看到BlcokManager初始化时,创建DiskBlockManager,在创建时,调用了createLocalDirs方法创建本地文件目录,然后创建了二维数组subDirs,用来缓存一级目录localDirs及二级目录,其中二级目录的数量根据配置spark.diskStore.subDirectories获取,默认为64.那么为什么DisBlockManager要创建二级目录?因为二级目录用于对文件进行散列存储,散列存储可以使所有文件都随机存放,写入或删除文件更方便,存取速度快,节省空间。那么我们再细化看下这个磁盘路径是怎么配置的,从哪里来的?
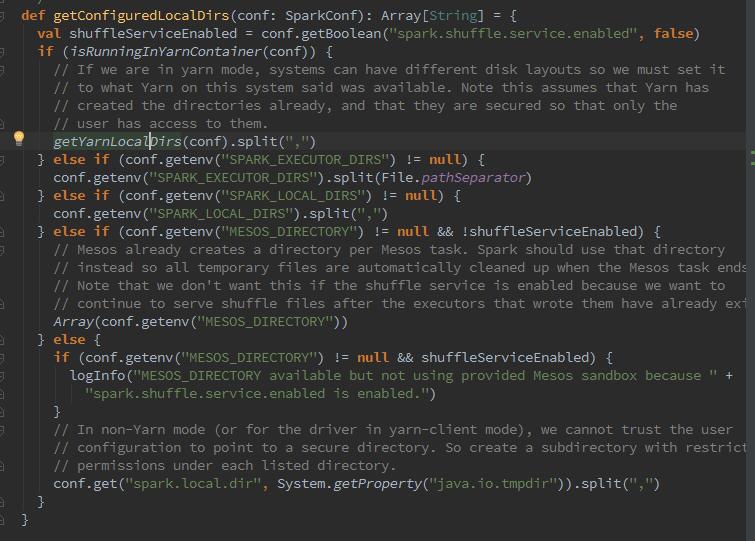
从图中可以看到,这个路径来源于spark.local.dir,但是呢,如果是spark on yarn模式,那么真正的路径是由yarn的配置参数决定的,参数为YARN_LOCAL_DIRS。
接下来查阅源码还会发现有个addShutdownHock()方法,它是干什么的呢,它是用来添加运行时环境结束时,在进程关闭的时候创建线程,通过调用Disk-BlockMnager的stop方法,清除一些临时目录:
下来我们来探索下,是如何获取磁盘文件的?
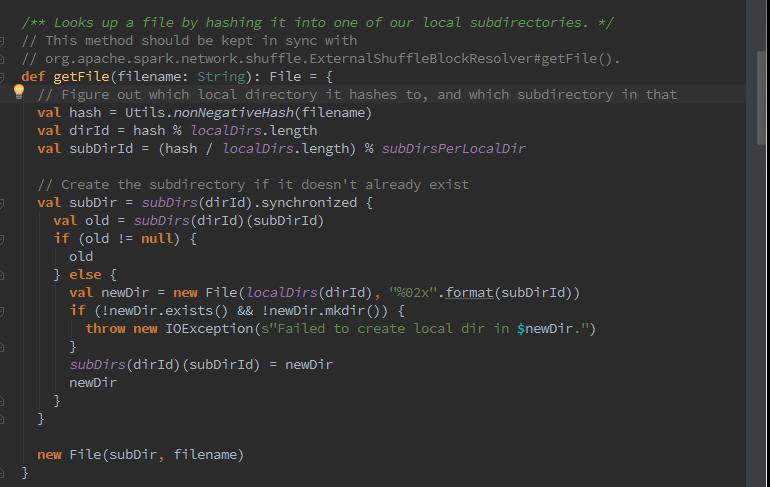
首先我们可以看到,nonNegativeHash方法,该方法用来根据文件名计算哈希值。然后根据哈希值与本地文件以及目录的总数求余数,记为dirId。随后又根据哈希值与本地文件一级目录的总数求商数,此商数与二级目录的数目再求余数,记为subDirId.那么如果dirId/subDirId目录存在,则获取dirId/subDirId目录下的文件,否则创建dirId/subDirId目录。
好的下来我们来创建本地临时文件与shuffle过程的临时文件:

我们可以看到,当MemoryStore没有足够空间时,就会使用DiskStore将块存入磁盘。当ShuffleMapTask运行结束需要把中间结果临时保存,此时就调用了createTempShuffleBlock方法创建临时Block,并返回TempShuffleBlockId与其文件的对偶,同时拼上随机字符串标识。
那么下来,我们再深入了解下MemoryStore,我们在配置spark的时候,会配置计算内存与缓存内存的比例,实质是通过MemoryStore将没有序列化的Java对象数组或者序列化的ByteBuffer存储到内存中,那么MemoryStore是如何构造的呢?

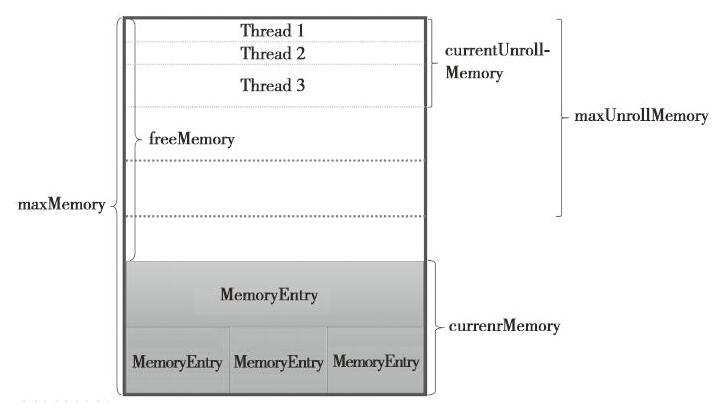
整个MemoryStore的存储分为两块:一块是被很多MemeoryEntry占据的内存currentMemory,这些currentMemory实际上是通过entryes持有的;另一块儿是通过unrollMemoryMap通过占座方式占用的内存currentUnrollMemory.其实意思就是预留空间,可以防止在向内存真正写入数据时,内存不足发生溢出。查阅数据,记录些概念:
-maxUnrollMemory:当前Driver或者Executor最多展开的Block所占用的内存,可以修改spark.storage.unrollFraction的大小。
-maxMemory:当前Driver或者Executor的最大内存。
-currentMemory:当前Driver或者Executor已经使用的内存。
-freeMemory:当前Driver或Executor未使用内存。freeMemoy = maxMemory - currentMemory。
这里有个重要的点,叫做unrollSafely,为了防止写入内存的数据过大,导致内存溢出,Spark采用了一种优化方案,在正式写入内存之前,先用逻辑方式申请内存,如果申请成功,再写入内存,这个过程就跟名字一样了,称为安全展开。
就到这里好了,去吃饭~
参考文献:《深入理解Spark:核心思想与源码分析》
Spark BlockManager的通信及内存占用分析(源码阅读九)的更多相关文章
- php 内存共享shmop源码阅读
多进程通信的时候,会涉及到共享内存.shmop_open()创建或打开一个内存块 PHP_FUNCTION(shmop_open) { long key, mode, size; struct php ...
- Unity3D–Texture图片空间和内存占用分析(转载)
原地址:http://www.unity蛮牛.com/home.php?mod=space&uid=1801&do=blog&id=756 Texture图片空间和内存占用分析 ...
- Unity3D–Texture图片空间和内存占用分析
Texture图片空间和内存占用分析.由于U3D并没有很好的诠释对于图片的处理方式,所以很多人一直对于图集的大小和内存的占用情况都不了解.在此对于U3D的图片问题做一个实际数据的分析.此前的项目都会存 ...
- Spark技术内幕:Stage划分及提交源码分析
http://blog.csdn.net/anzhsoft/article/details/39859463 当触发一个RDD的action后,以count为例,调用关系如下: org.apache. ...
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- java分析源码-ReentrantLock
一.前言 在分析了 AbstractQueuedSynchronier 源码后,接着分析ReentrantLock源码,其实在 AbstractQueuedSynchronizer 的分析中,已经提到 ...
- Spark技术内幕: Task向Executor提交的源码解析
在上文<Spark技术内幕:Stage划分及提交源码分析>中,我们分析了Stage的生成和提交.但是Stage的提交,只是DAGScheduler完成了对DAG的划分,生成了一个计算拓扑, ...
- 鸿蒙内核源码分析(源码结构篇) | 内核每个文件的含义 | 百篇博客分析OpenHarmony源码 | v18.04
百篇博客系列篇.本篇为: v18.xx 鸿蒙内核源码分析(源码结构篇) | 内核每个文件的含义 | 51.c.h .o 前因后果相关篇为: v08.xx 鸿蒙内核源码分析(总目录) | 百万汉字注解 ...
- 鸿蒙内核源码分析(源码注释篇) | 鸿蒙必定成功,也必然成功 | 百篇博客分析OpenHarmony源码 | v13.02
百篇博客系列篇.本篇为: v13.xx 鸿蒙内核源码分析(源码注释篇) | 鸿蒙必定成功,也必然成功 | 51.c.h .o 几点说明 kernel_liteos_a_note | 中文注解鸿蒙内核 ...
随机推荐
- HP T505恢复出厂系统
1.制作usb启动U盘. ------ 从HP网站上下载,或者找供应商提供 2.按F11,从U盘启动进去,会自动执行安装,等待完成即可以.
- js 自运行函数作用
var obj = new Object(); function test2() { for (var i=1;i<5;i++) { obj['f'+i] = function() { retu ...
- Win10/UWP 让你的App使用上扫描仪
UWP的扫描仪功能现在被微软划分到了[Windows Desktop Extensions for the UWP]中,如果要使用扫描仪扫描图片到自己的App中,首先我们要添加[Windows Des ...
- 必须掌握的八个cmd 命令
一,ping 它是用来检查网络是否通畅或者网络连接速度的命令.作为一个生活在网络上的管理员或者黑客来说,ping命令是第一个必须掌握的DOS命令,它 所利用的原理是这样的:网络上的机器都有唯一确定的I ...
- (进阶篇)PHP+Mysql+jQuery找回密码
通常所说的密码找回功能不是真的能把忘记的密码找回,因为我们的密码是加密保存的,一般开发者会在验证用户信息后通过程序生成一个新密码或者生成一个特定的链接并发送邮件到用户邮箱,用户从邮箱链接到网站的重置密 ...
- int类型究竟占几个字节
我最近也在看深入理解计算机系统这本书,上面提到了在32位机器和64机器中int类型都占用4个字节.后来,别人查了The C Programming language这本书,里面有一句话是这样的: Ea ...
- led驱动
驱动步骤: 1.驱动框架:一般读驱动代码需要module_init一层层找代码 2.硬件配置 代码中led_ioctl函数设置引脚的电平高低,该函数是驱动程序对设备的通道进行统一设置/控制的函数 一. ...
- 数组map()方法和filter()方法及字符串startsWith(anotherString)和endsWith(anotherString)方法
map方法的作用不难理解,"映射"嘛,也就是原数组被"映射"成对应新数组 var newArr = arr.map(function() {});例子: var ...
- java通过反射取得一个类的完整结构
首先我们在person包中新建一个Person.java: package person; import sex.Sex; public class Person{ private String na ...
- rails查询mongodb通用查询
ruby on rails 很好的跟mongodb进行了结合,gem包: 地址:https://rubygems.org/gems/mongoid 文档:https://docs.mongodb.co ...