Mysql分库分表方案
Mysql分库分表方案
1.为什么要分表:
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。
2. mysql proxy:amoeba
做mysql集群,利用amoeba。
从上层的java程序来讲,不需要知道主服务器和从服务器的来源,即主从数据库服务器对于上层来讲是透明的。可以通过amoeba来配置。
3.大数据量并且访问频繁的表,将其分为若干个表
比如对于某网站平台的数据库表-公司表,数据量很大,这种能预估出来的大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。
某网站现在的数据量至多是5000万条,可以设计每张表容纳的数据量是500万条,也就是拆分成10张表,
那么如何判断某张表的数据是否容量已满呢?可以在程序段对于要新增数据的表,在插入前先做统计表记录数量的操作,当<500万条数据,就直接插入,当已经到达阀值,可以在程序段新创建数据库表(或者已经事先创建好),再执行插入操作。
4. 利用merge存储引擎来实现分表
如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了。用merge存储引擎来实现分表, 这种方法比较适合.
举例子:
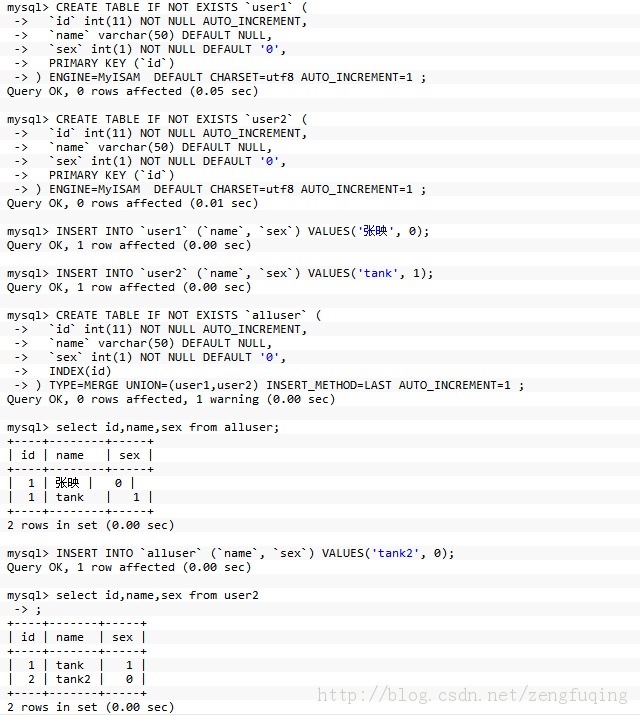
------------------- ----------华丽的分割线--------------------------------------
数据库架构
1、简单的MySQL主从复制:
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其图如下:
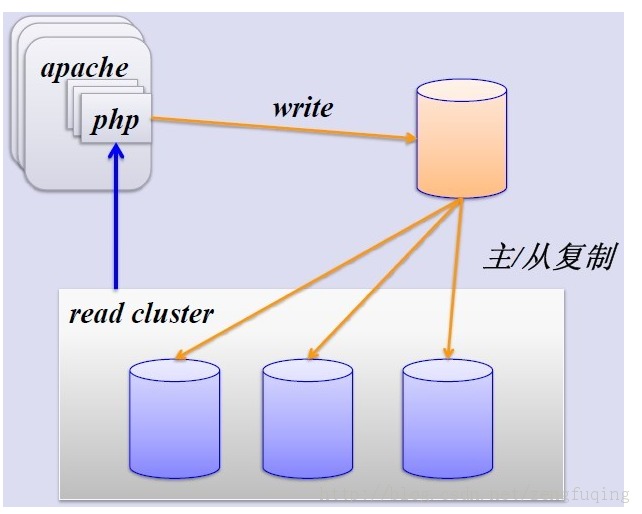
其主从复制的过程如下图所示:
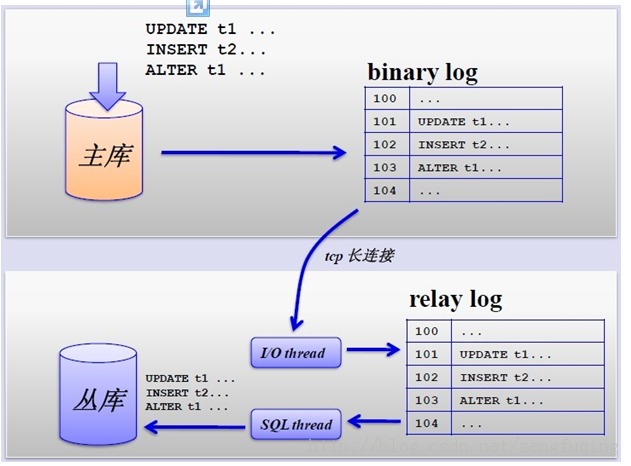
但是,主从复制也带来其他一系列性能瓶颈问题:
1. 写入无法扩展
2. 写入无法缓存
3. 复制延时
4. 锁表率上升
5. 表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案,一起来看看。
2、MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:
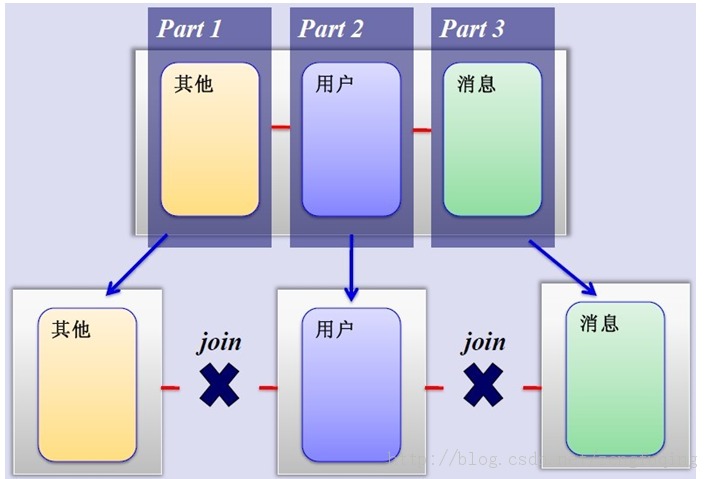
然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平分割呢?
3、MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:
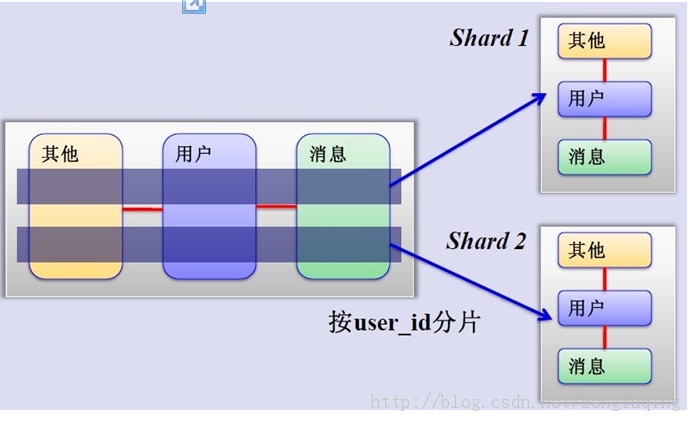
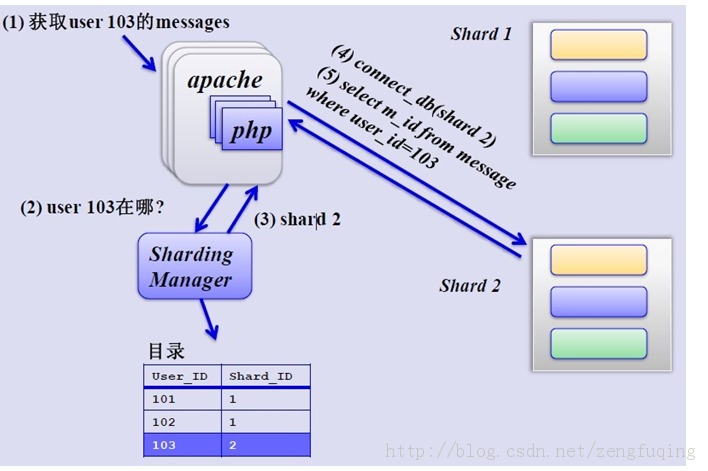
如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:
Mysql分库分表方案的更多相关文章
- 【分库、分表】MySQL分库分表方案
一.Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. ...
- mysql 数据库 分表后 怎么进行分页查询?Mysql分库分表方案?
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- MySQL 分库分表方案,总结的非常好!
前言 公司最近在搞服务分离,数据切分方面的东西,因为单张包裹表的数据量实在是太大,并且还在以每天60W的量增长. 之前了解过数据库的分库分表,读过几篇博文,但就只知道个模糊概念, 而且现在回想起来什么 ...
- Mysql 分库分表方案
0 引言 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. mysql中有一种机制是表锁定和行锁 ...
- mysql 分库分表 ~ 方案选择浅谈
一 简介:分库分表的理解二 具体: 1 当由于单台DB业务增长导致的服务器压力时,就必须横向进行扩展 2 本文仅从中间层观点进行分析三 现有方案 方案1 sharding家 ...
- Mysql分库分表方案,如何分,怎样分?
https://www.cnblogs.com/phpper/p/6937896.html 为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这 ...
- Mysql 之分库分表方案
Mysql分库分表方案 为什么要分表 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. mysq ...
- MySQL主从(MySQL proxy Lua读写分离设置,一主多从同步配置,分库分表方案)
Mysql Proxy Lua读写分离设置 一.读写分离说明 读写分离(Read/Write Splitting),基本的原理是让主数据库处理事务性增.改.删操作(INSERT.UPDATE.DELE ...
- mysql分库分表(一)
mysql分库分表 参考: https://blog.csdn.net/xlgen157387/article/details/53976153 https://blog.csdn.net/cleve ...
随机推荐
- Oracle Hang分析--转载
1. 数据库hang的几种可能性 oracle 死锁 或者系统负载非常高比如cpu使用或其他一些锁等待很高都可能导致系统hang住,比如大量的DX锁. 通常来说,我们所指的系统hang住,是指应用无响 ...
- zookeeper分布式部署-mac先测试
由于平台马上要引入zookeeper+dubbo,为了解决zookeeper单个实例运行的风险,需要做个集群. 1,先说配置:zoo.cfg十分简单,分两种情况: 一种是在一台机器采用不同的端口配置多 ...
- extentreports报告插件与testng集成(二)
之前的一篇文章中,是把extentreports 的报告的初始方法写在driver的初始方法中,写报告的方法在testng的 onTest中,这次将这些方法全都拆出来,写在一个方法类中,这个类重现实现 ...
- 使用ab进行压力测试
在Windows系统的命令行下,进入ab.exe程序所在目录,执行ab.exe程序.注意直接双击无法正确运行.
- Java的基本程序设计结构(上)
在Java中,每一个变量属于一种类型(type).在声明变量时,变量所属的类型位于变量名之前. 例如: double salary; int vacationDays; long earthPopul ...
- vmware workstation 上创建的centos 7.2 ,新添加一块网卡。无法找到配置文件。
在vmware workstation 11上,新建一个centos 7.2系统. 初装带有一个块网卡:能够在/etc/sysconfig/network-scripts/目录下找到相应的网卡配置文件 ...
- 分析一个类似于jquery的小框架 (2)
核心构造函数 (function ( window, undefined ) { // 定义Itcast构造函数 function Itcast ( selector ) { return new I ...
- 微软ASP.NET技术“乱谈”
微软ASP.NET技术“乱谈” 2014新年了,顺手写的一点文字,主要谈谈我对当前微软ASP.NET技术的看法,比较随意,大伙儿随便看看吧. 1 当前微软Web平台技术全貌 从2002年发布.NET ...
- python基础知识3——基本的数据类型2——列表,元组,字典,集合
磨人的小妖精们啊!终于可以归置下自己的大脑啦,在这里我要把--整型,长整型,浮点型,字符串,列表,元组,字典,集合,这几个知识点特别多的东西,统一的捯饬捯饬,不然一直脑袋里面乱乱的. 一.列表 1.列 ...
- Python语法二
1.raw_input 输入 2.如果想查看某个关键字的用法,可以在命令行输入pydoc raw_input. 如果是windows,那么试一下 python -m pydoc raw_input 3 ...