大数据挖掘: FPGrowth初识--进行商品关联规则挖掘
@(hadoop)[Spark, MLlib, 数据挖掘, 关联规则, 算法]
〇、简介
经典的关联规则挖掘算法包括Apriori算法和FP-growth算法。Apriori算法多次扫描交易数据库,每次利用候选频繁集产生频繁集;而FP-growth则利用树形结构,无需产生候选频繁集而是直接得到频繁集,大大减少扫描交易数据库的次数,从而提高了算法的效率。但是apriori的算法扩展性较好,可以用于并行计算等领域。
关联规则的目的就是在一个数据集中找出项与项之间的关系,适用于在大数量的项集中发现关联共现的项。也被称为购物篮分析 (Market Basket analysis),因为“购物篮分析”很贴切的表达了适用该算法情景中的一个子集。
购物网站里你买了一个商品,旁边列出一系列买过该商品的人还买的其他商品,并且按置信度高低排序,一般会发现买手机的还会买充电器(买充电器的人不一定会买手机),买牙刷的还会买牙膏,这大概就是关联规则的用处。
基础环境:
CentOS-6.5
JDK-1.7
spark:spark-1.2.0+cdh5.3.6+379
一、Apriori算法
支持度(Support):定义为
$$supp(X) = \frac{包含X的记录数}{数据集记录总数}= P(X)=\frac{occur(X)}{count(D)}$$
置信度(Confidence): 定义为
$$ conf(X=>Y) = \frac{同时包含X和Y的记录数}{数据集中包含X的记录数}=P(Y|X)=\frac{P(X \cap Y)}{P(X)} = \frac{occur(X \cap Y)}{occur(X)}$$
FP-growth算法是Apriori算法的优化。
二、MLlib实现
spark-1.2.0 版本中Mliib的FPGrowthModel并没有generateAssociationRules(minConfidence)方法。因此要引用高版本的jar包,并在提交任务时指定才行。这是可以实现的。
Ⅰ、获取购买历史数据
下面共选取了6931条购买历史记录,作为关联规则挖掘的数据集。
1、产生源数据
我们可能需要使用类Mysql中的group_concat()来产生源数据。在Hive中的替代方案是concat_ws()。但若要连接的列是非string型,会报以下错误:Argument 2 of function CONCAT_WS must be "string or array<string>", but "array<bigint>" was found.。使用以下hiveSQL可以避免此问题:
SELECT concat_ws(',', collect_set(cast(item_id AS String))) AS items FROM ods_angel_useritem tb GROUP BY tb.user_id;
得到item1,item2,item3式数据结构。
数据结构如下所示:
731478,732986,733494
731353
732985,733487,730924
731138,731169
733850,733447
731509,730796,733487
731169,730924,731353
730900
733494,730900,731509
732991,732985,730796,731246,733850
2、构造JavaRDD
JavaRDD<List<String>> transactions = ...;
Ⅱ、过滤掉出现频率较低的数据
Java代码:
//设置频率(支持率)下限
FPGrowth fpg = new FPGrowth().setMinSupport(0.03).setNumPartitions(10);
FPGrowthModel<String> model = fpg.run(transactions);
List<FPGrowth.FreqItemset<String>> list_freqItem = model.freqItemsets().toJavaRDD().collect();
System.out.println("list_freqItem .size: " + list_freqItem .size());
for (FPGrowth.FreqItemset<String> itemset : list_freqItem) {
System.out.println("[" + itemset.javaItems() + "], " + itemset.freq());
}
结果:
[[734902]], 275
[[733480]], 1051
[[734385]], 268
[[733151]], 895
[[733850]], 878
[[733850, 733480]], 339
[[733152]], 266
[[733230]], 243
[[731246]], 500
[[731246, 733480]], 233
[[734888]], 231
[[734894]], 483
[[733487]], 467
[[740697]], 222
[[733831]], 221
[[734900]], 333
[[731353]], 220
[[731169]], 311
[[730924]], 308
[[732985]], 212
[[732994]], 208
[[730900]], 291
$$\frac{208}{6931}=0.03001>0.03$$,6931是交易的订单数量,即数据源总条数。
可见,商品732994正好高于支持率下限。
Ⅲ、过滤掉可信度过低的判断
Java代码:
double minConfidence = 0.3; //置信下限
List<AssociationRules.Rule<String>> list_rule = model.generateAssociationRules(minConfidence).toJavaRDD().collect();
System.out.println("list_rule.size: " + list_rule.size());
for (AssociationRules.Rule<String> rule : list_rule) {
System.out.println(
rule.javaAntecedent() + " => " + rule.javaConsequent() + ", " + rule.confidence());
}
结果:
[733480] => [733850], 0.3225499524262607
[731246] => [733480], 0.466
[733850] => [733480], 0.38610478359908884
- $P(733850|733480)=\frac{occur(733850 \cap 733480)}{occur(733480)}=\frac{339}{1051}=0.3225499524262607$
- $P(733480|731246)=\frac{occur(733480 \cap 731246)}{occur(731246)}=\frac{233}{500}=0.466$
- $P(733480|733850)=\frac{occur(733850 \cap 733480)}{occur(733850)}=\frac{339}{878}=0.38610478359908884$
以上表明,用户在购买商品733480后往往还会购买商品733480,可信度为0.3225499524262607;用户在购买商品731246后往往还会购买商品731246,可信度为0.466;用户在购买商品733850后往往还会购买商品733480,可信度为0.38610478359908884。
三、提交任务
Ⅰ、Spark On Standalone
spark-submit --master spark://node190:7077 --class com.angel.mlib.FPGrowthTest --jars lib/hbase-client-0.98.6-cdh5.3.6.jar,lib/hbase-common-0.98.6-cdh5.3.6.jar,lib/hbase-protocol-0.98.6-cdh5.3.6.jar,lib/hbase-server-0.98.6-cdh5.3.6.jar,lib/htrace-core-2.04.jar,lib/zookeeper.jar,lib/spark-mllib_2.10-1.5.2.jar,lib/spark-core_2.10-1.5.2.jar spark-test-1.0.jar
Ⅱ、Spark On Yarn
spark-submit --master yarn-client --class com.angel.mlib.FPGrowthTest --jars lib/hbase-client-0.98.6-cdh5.3.6.jar,lib/hbase-common-0.98.6-cdh5.3.6.jar,lib/hbase-protocol-0.98.6-cdh5.3.6.jar,lib/hbase-server-0.98.6-cdh5.3.6.jar,lib/htrace-core-2.04.jar,lib/zookeeper.jar,lib/spark-mllib_2.10-1.5.2.jar,lib/spark-core_2.10-1.5.2.jar spark-test-1.0.jar
四、FPGrowth算法在现实中的应用调优
在实际情况中,真实的业务数据处处都是噪声。活用数据,设计有业务含义的特征体系,是构造鲁棒模型的基础!
具体的解决办法,我们可以多算法并用,这些将在后续的aitanjupt文章中详述。
五、综上所述
也就是说,“购买了该宝贝的人32%还购买了某某商品”就是使用商品关联规则挖掘实现的;还有一些捆绑销售,例如牙膏和牙刷一起卖,尿布和啤酒放在一起卖。
关联规则挖掘算法不只是能用在商品销售,使用它我们可以挖掘出更多的关联关系,比如我们可以挖掘出,温度、天气、性别等等与心情之间是否有关联关系,这是非常有意义的。
关联规则挖掘算法应用场景非常庞大,遥记多年前做的手机用户关联分析,那时尚未用到关联规则挖掘算法,用的是自己编写的类join算法,现在看起来,关联规则挖掘算法是再适合不过的了。
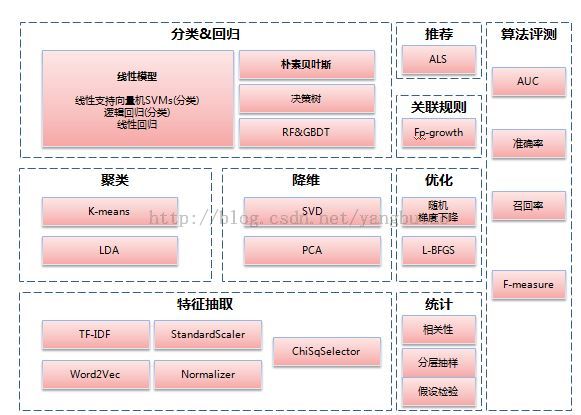
上面是mllib下所有的算法。
某一数据挖掘算法可以做某种特定的分析,也可以跨界使用,还可以联合应用,重要的是理解其思想以灵活运用。
幸福是有一颗感恩的心,健康的身体,称心的工作,一位深爱你的人,一帮信赖的朋友!
祝大家小年快乐!
作者 @王安琪

http://www.cnblogs.com/wgp13x/
2016 年 02月 02日
大数据挖掘: FPGrowth初识--进行商品关联规则挖掘的更多相关文章
- apriori && fpgrowth:频繁模式与关联规则挖掘
已迁移到我新博客,阅读体验更佳apriori && fpgrowth:频繁模式与关联规则挖掘 详细代码我放在github上:click me 一.实验说明 1.1 任务描述 1.2 数 ...
- 数据挖掘系列(1)关联规则挖掘基本概念与Aprior算法
整理数据挖掘的基本概念和算法,包括关联规则挖掘.分类.聚类的常用算法,敬请期待.今天讲的是关联规则挖掘的最基本的知识. 关联规则挖掘在电商.零售.大气物理.生物医学已经有了广泛的应用,本篇文章将介绍一 ...
- 数据挖掘进阶之关联规则挖掘FP-Growth算法
数据挖掘进阶之关联规则挖掘FP-Growth算法 绪 近期在写论文方面涉及到了数据挖掘,需要通过数据挖掘方法实现软件与用户间交互模式的获取.分析与分类研究.主要涉及到关联规则与序列模式挖掘两块.关联规 ...
- 数据挖掘系列(4)使用weka做关联规则挖掘
前面几篇介绍了关联规则的一些基本概念和两个基本算法,但实际在商业应用中,写算法反而比较少,理解数据,把握数据,利用工具才是重要的,前面的基础篇是对算法的理解,这篇将介绍开源利用数据挖掘工具weka进行 ...
- 数据挖掘算法之-关联规则挖掘(Association Rule)
在数据挖掘的知识模式中,关联规则模式是比较重要的一种.关联规则的概念由Agrawal.Imielinski.Swami 提出,是数据中一种简单但很实用的规则.关联规则模式属于描述型模式,发现关联规则的 ...
- 数据挖掘算法之-关联规则挖掘(Association Rule)(购物篮分析)
在各种数据挖掘算法中,关联规则挖掘算是比較重要的一种,尤其是受购物篮分析的影响,关联规则被应用到非常多实际业务中,本文对关联规则挖掘做一个小的总结. 首先,和聚类算法一样,关联规则挖掘属于无监督学习方 ...
- 数据挖掘系列(5)使用mahout做海量数据关联规则挖掘
上一篇介绍了用开源数据挖掘软件weka做关联规则挖掘,weka方便实用,但不能处理大数据集,因为内存放不下,给它再多的时间也是无用,因此需要进行分布式计算,mahout是一个基于hadoop的分布式数 ...
- 数据挖掘算法之关联规则挖掘(一)apriori算法
关联规则挖掘算法在生活中的应用处处可见,几乎在各个电子商务网站上都可以看到其应用 举个简单的例子 如当当网,在你浏览一本书的时候,可以在页面中看到一些套餐推荐,本书+有关系的书1+有关系的书2+... ...
- 数据挖掘系列(2)--关联规则FpGrowth算法
上一篇介绍了关联规则挖掘的一些基本概念和经典的Apriori算法,Aprori算法利用频繁集的两个特性,过滤了很多无关的集合,效率提高不少,但是我们发现Apriori算法是一个候选消除算法,每一次消除 ...
随机推荐
- iOS AFNetworking 打印从服务器返回的错误提示信息
每次做项目的时候都会在网络请求时候测试接口的时候会出现一些不同的错误,而控制台打印的错误提示信息都是data类型,看不出提示的错误的信息是什么.后面经过一些查阅发现其实是可以把这个转变为string的 ...
- singleCall单来源调用解析及实现
定义: 单来源调用指一个类的生成工作只能由特定类来执行. eg李宁牌鞋子只能由李宁专卖店生产 这个问题归结起来,也就是说在工厂模式中,指定的产品类只能通过具体的特定工厂类来生成,而不能自己new出来或 ...
- js 小数[非]四舍五入
1.四舍五入 (2.678).toFixed(2) // 2.68 2.不需要四舍五入 (parseInt(2.678*100)/100.0).toFixed(2) // 2.67 3.字节单位转换 ...
- 12款高质量的响应式 HTML5/CSS3 网站模板
HTML5 已经成为众所周知的语言,大量的 HTML5 资源和工具正在建立,以帮助开发人员和设计人员.今天,我们展示12款免费的响应式 HTML5/CSS3 网站模板,帮助你创建醒目和视觉震撼的网站. ...
- Skytte:一款令人印象深刻的 HTML5 射击游戏
Skytte 是一款浏览器里的 2D 射击游戏.使用 Canvas 元素和大量的 JavaScript 代码实现.Skytte 是用我们的开源和现代的前端技术创造的.经典,快节奏的横向滚动射击游戏,探 ...
- 小白的vue学习路程
最近公司开发新的项目,前端框架选定vue,对于前端小白的我,需要自己学习补充能量. vue的最大特点:响应的数据绑定.组合的视图组件. vue文件里面包含三种:<template>html ...
- vue安装
条件:已安装 node&npm 1.安装 cnpm : $ npm install -g cnpm --registry=https://regis ...
- js获取隐藏元素宽高的方法
网上有一些js获取隐藏元素宽高的方法,但是可能会存在某些情况获取不了. 例如: <!DOCTYPE html> <html lang="en"> <h ...
- Window对象
Window对象: Window 对象表示浏览器中打开的窗口,如果文档包含框架(frame 或 iframe 标签),浏览器会为 HTML 文档创建一个 window 对象,并为每个框 ...
- C4.5(决策树)
C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法.它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类.C4.5的目标是通过学习, ...