Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取
、编译Hadooop
1.1 搭建环境
1.1.1 安装并设置maven
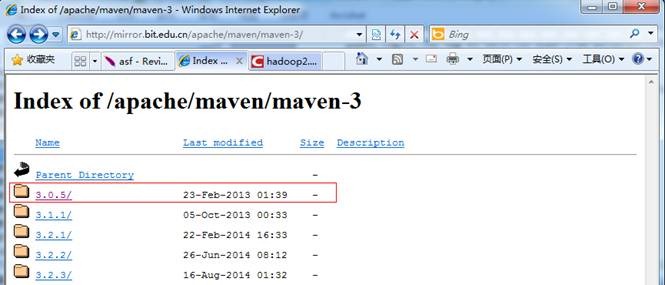
1. 下载maven安装包,建议安装3.0以上版本,本次安装选择的是maven3.0.5的二进制包,下载地址如下
http://mirror.bit.edu.cn/apache/maven/maven-3/
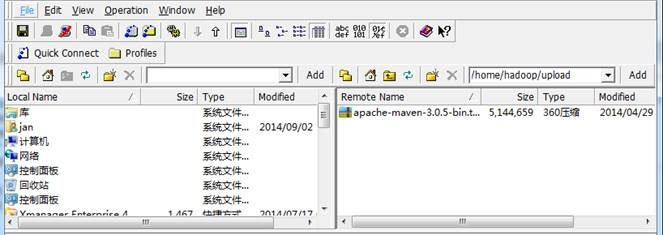
2. 使用ssh工具把maven包上传到/home/hadoop/upload目录
3. 解压缩apache-maven-3.0.5-bin.tar.gz包
$tar -zxvf apache-maven-3.0.5-bin.tar.gz

4. 把apache-maven-3.0.5目录移到/usr/local目录下
$sudo mv apache-maven-3.0.5 /usr/local

5. 在/etc/profile配置文件中加入如下设置
export PATH=$JAVA_HOME/bin:/usr/local/apache-maven-3.0.5/bin:$PATH

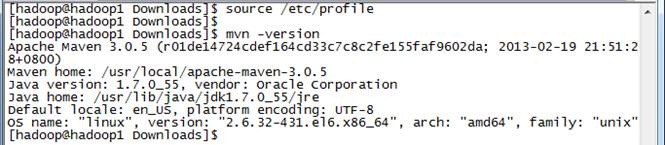
6. 编辑/etc/profile文件并验证配置是否成功:
$source /etc/profile
$mvn -version
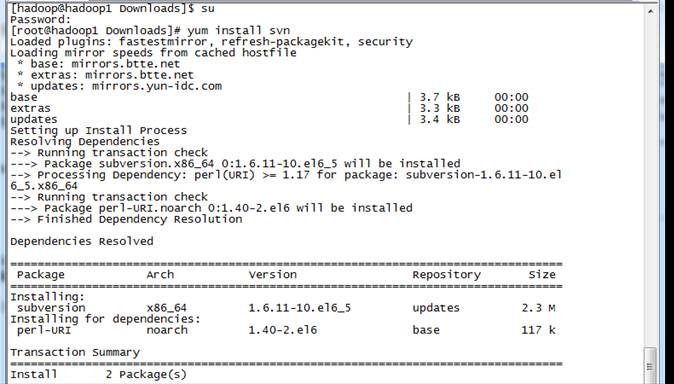
1.1.2 以root用户使用yum安装svn
#yum install svn
1.1.3 以root用户使用yum安装autoconf automake libtool cmake
#yum install autoconf automake libtool cmake

1.1.4 以root用户使用yum安装ncurses-devel
#yum install ncurses-devel
1.1.5 以root用户使用yum安装openssl-devel
#yum install openssl-devel
1.1.6 以root用户使用yum安装gcc*
#yum install gcc*
1.1.7 安装并设置protobuf
注:该程序包需要在gcc安装完毕后才能安装,否则提示无法找到gcc编译器。
1. 下载protobuf安装包
下载链接为: https://code.google.com/p/protobuf/downloads/list

2. 使用ssh工具把protobuf-2.5.0.tar.gz包上传到/home/hadoop/Downloads目录
3. 解压安装包
$tar -zxvf protobuf-2.5.0.tar.gz

4. 把protobuf-2.5.0目录转移到/usr/local目录下
$sudo mv protobuf-2.5.0 /usr/local

5. 进行目录运行命令
进入目录以root用户运行如下命令:
#./configure
#make
#make check
#make install

6. 验证是否安装成功
运行成功之后,通过如下方式来验证是否安装成功
#protoc

1.2 编译Hadoop
1.2.1 下载Hadoop源代码 Release2.2.0
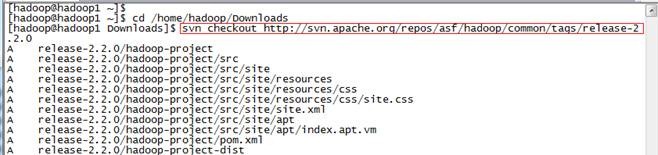
通过SVN获取Hadoop2.2.0源代码,在/home/hadoop/Downloads目录下命令:
$svn checkout http://svn.apache.org/repos/asf/hadoop/common/tags/release-2.2.0
获取时间较长,大小约75.3M
1.2.2 编译Hadoop源代码
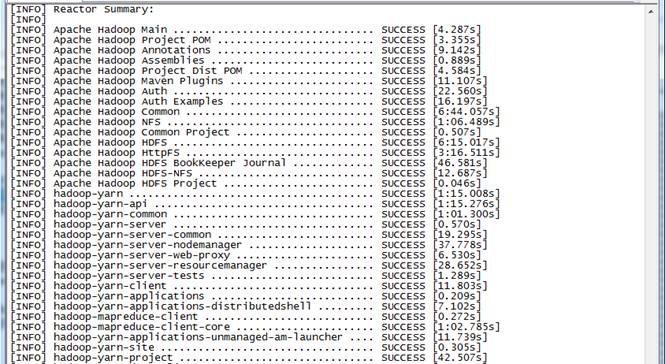
:) 由于hadoop2.2.0在svn中pom.xml有点问题,会造成编译中出错,可先参考3.2修复该问题。在Hadoop源代码的根目录执行如下命令:
$mvn package -Pdist,native -DskipTests –Dtar
(注意:这行命令需要手工输入,如果复制执行会报异常!)

分钟,在编译过程需要联网,从网络中下载所需要的资料。

1.2.3 验证编译是否成功
到 hadoop-dist/target/hadoop-2.2.0/lib/native 目录中查看libhadoop.so.1.0.0属性:
$file ./libhadoop.so.1.0.0
位
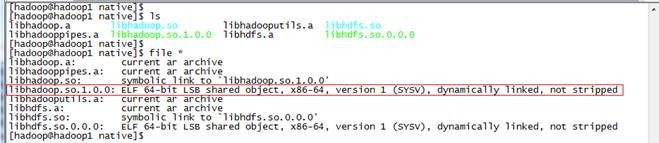
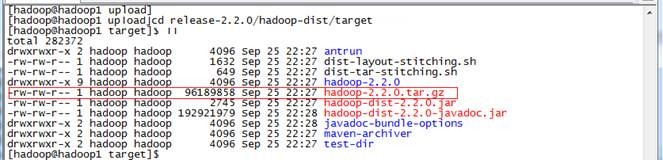
在hadoop-dist/target目录中已经打包好了hadoop-2.2.0.tar.gz,该文件作为Hadoop2.X 64位安装包。
、安装Hadoop
2.1 配置准备
2.1.1 上传并解压Hadoop安装包
位操作系统安装,在64位服务器安装会出现4.1的错误异常。我们使用上一步骤编译好的hadoop-2.2.0.tar.gz文件作为安装包(也可以从网上下载native文件夹或者打包好的64位hadoop安装包),使用"Spark编译与部署(上)"中1. 3.1介绍的工具上传到/home/hadoop/upload 目录下
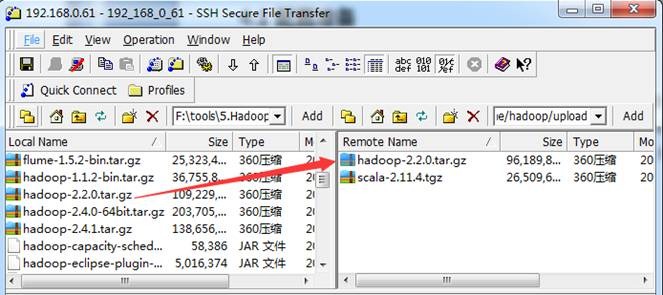
2. 在主节点上解压缩
$cd /home/hadoop/upload/
$tar -xzf hadoop-2.2.0.tar.gz

3. 把hadoop-2.2.0目录移到/app/hadoop目录下
$ mv hadoop-2.2.0 /app/hadoop
$ls /app/hadoop

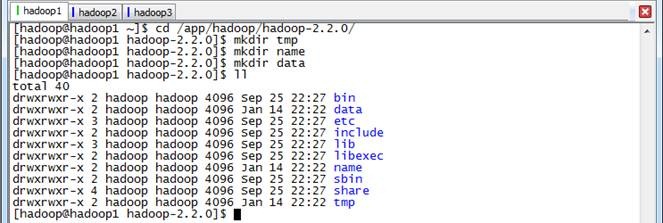
2.1.2 在Hadoop目录下创建子目录
hadoop用户在/app/hadoop/hadoop-2.2.0目录下创建tmp、name和data目录
$cd /app/hadoop/hadoop-2.2.0/
$mkdir tmp
$mkdir name
$mkdir data
$ll
2.1.3 配置hadoop-env.sh
1. 打开配置文件hadoop-env.sh
$cd /app/hadoop/hadoop-2.2.0/etc/hadoop
$sudo vi hadoop-env.sh
2. 加入配置内容,设置JAVA_HOME和PATH路径
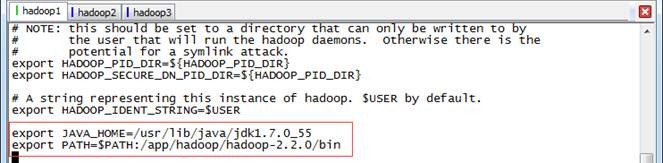
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export PATH=$PATH:/app/hadoop/hadoop-2.2.0/bin
3. 编译配置文件hadoop-env.sh,并确认生效
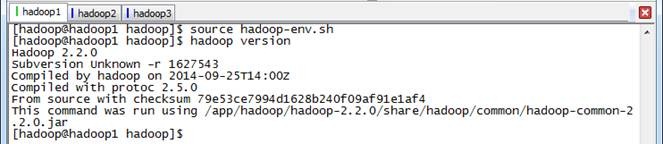
$source hadoop-env.sh
$hadoop version
2.1.4 配置yarn-env.sh
1. 在/app/hadoop/hadoop-2.2.0/etc/hadoop打开配置文件yarn-env.sh
$cd /app/hadoop/hadoop-2.2.0/etc/hadoop
$sudo vi yarn-env.sh
2. 加入配置内容,设置JAVA_HOME路径
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
3. 编译配置文件yarn-env.sh,并确认生效
$source yarn-env.sh
2.1.5 配置core-site.xml
1. 使用如下命令打开core-site.xml配置文件
$sudo vi core-site.xml
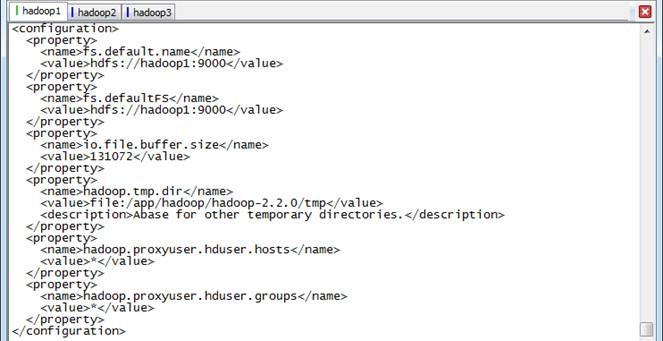
2. 在配置文件中,按照如下内容进行配置
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/app/hadoop/hadoop-2.2.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
2.1.6 配置hdfs-site.xml
1. 使用如下命令打开hdfs-site.xml配置文件
$sudo vi hdfs-site.xml
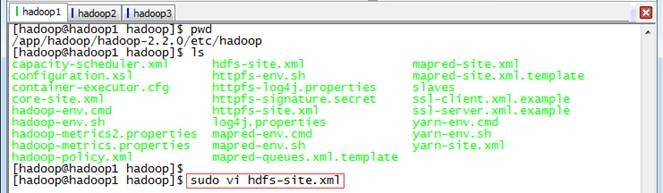
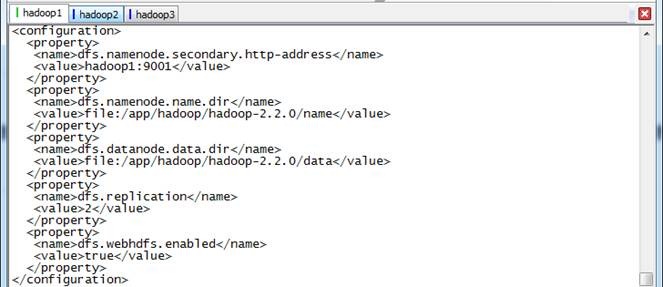
2. 在配置文件中,按照如下内容进行配置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/app/hadoop/hadoop-2.2.0/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/app/hadoop/hadoop-2.2.0/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
2.1.7 配置mapred-site.xml
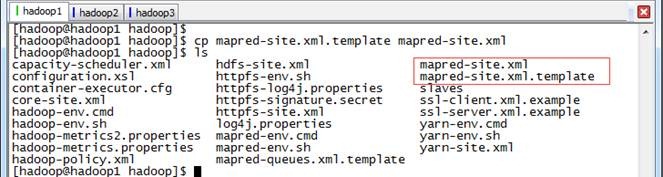
1. 默认情况下不存在mapred-site.xml文件,可以从模板拷贝一份
$cp mapred-site.xml.template mapred-site.xml
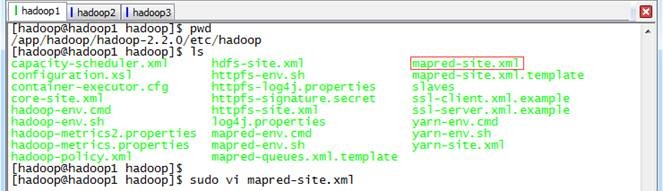
2. 使用如下命令打开mapred-site.xml配置文件
$sudo vi mapred-site.xml
3. 在配置文件中,按照如下内容进行配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
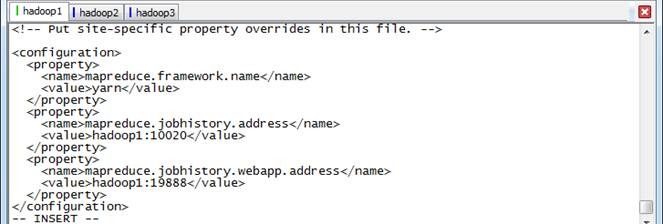
2.1.8 配置yarn-site.xml
1. 使用如下命令打开yarn-site.xml配置文件
$sudo vi yarn-site.xml
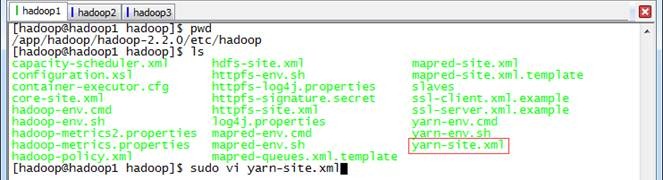
2. 在配置文件中,按照如下内容进行配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
</configuration>
2.1.9 配置Slaves文件
使用$sudo vi slaves打开从节点配置文件,在文件中加入
hadoop1
hadoop2
hadoop3

2.1.10 向各节点分发Hadoop程序
1.确认hadoop2和hadoop3节点/app/hadoop所属组和用户均为hadoop,然后进入hadoop1机器/app/hadoop目录,使用如下命令把hadoop文件夹复制到hadoop2和hadoop3机器
$cd /app/hadoop
$scp -r hadoop-2.2.0 hadoop@hadoop2:/app/hadoop/
$scp -r hadoop-2.2.0 hadoop@hadoop3:/app/hadoop/

2. 在从节点查看是否复制成功

2.2 启动部署
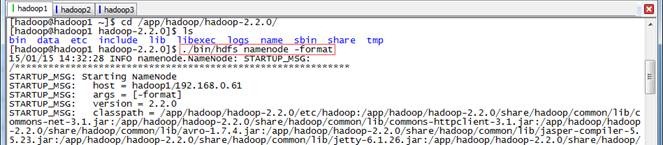
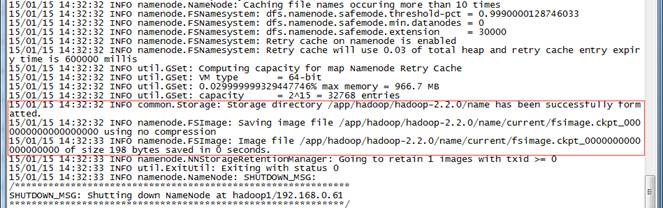
2.2.1 格式化NameNode
$cd /app/hadoop/hadoop-2.2.0/
$./bin/hdfs namenode -format
2.2.2 启动HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-dfs.sh
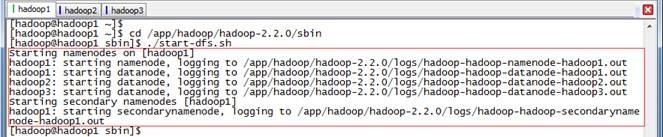
位时,出现问题3.1异常,可以参考解决
2.2.3 验证HDFS启动
此时在hadoop1上面运行的进程有:NameNode、SecondaryNameNode和DataNode

hadoop2和hadoop3上面运行的进程有:NameNode和DataNode

2.2.4 启动YARN
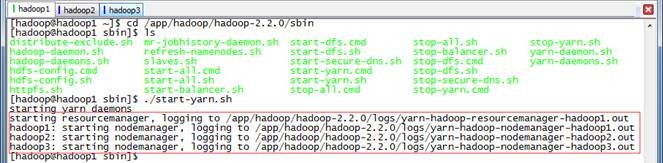
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-yarn.sh
2.2.5 验证YARN启动
此时在hadoop1上运行的进程有:NameNode、SecondaryNameNode、DataNode、NodeManager和ResourceManager

hadoop2和hadoop3上面运行的进程有:NameNode、DataNode和NodeManager


、问题解决
3.1 CentOS 64bit安装Hadoop2.2.0中出现文件编译位数异常
在安装hadoop2.2.0过程中出现如下异常:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
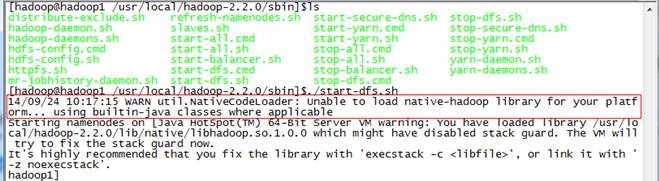
位编译,无法适应CentOS 64位环境造成

有两种办法解决:
l 重新编译hadoop,然后重新部署
l 暂时办法是修改配置,忽略有问题的文件

3.2 编译Hadoop2.2.0出现代码异常
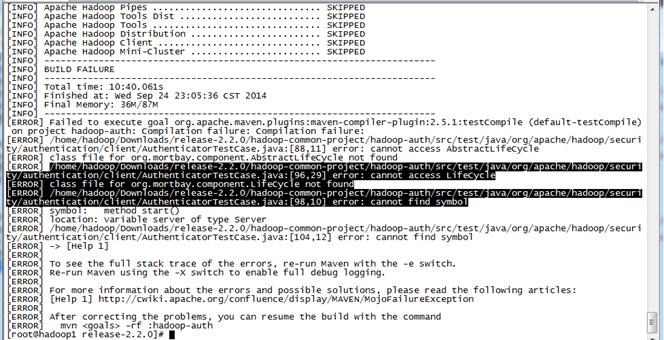
目前的2.2.0 的Source Code 压缩包解压出来的code有个bug 需要patch后才能编译。否则编译hadoop-auth 会提示下面错误:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:2.5.1:testCompile (default-testCompile) on project hadoop-auth: Compilation failure: Compilation failure:
[ERROR] /home/hadoop/Downloads/release-2.2.0/hadoop-common-project/hadoop-auth/src/test/java/org/apache/hadoop/security/authentication/client/AuthenticatorTestCase.java:[88,11] error: cannot access AbstractLifeCycle
[ERROR] class file for org.mortbay.component.AbstractLifeCycle not found
[ERROR] /home/hadoop/Downloads/release-2.2.0/hadoop-common-project/hadoop-auth/src/test/java/org/apache/hadoop/security/authentication/client/AuthenticatorTestCase.java:[96,29] error: cannot access LifeCycle
[ERROR] class file for org.mortbay.component.LifeCycle not found
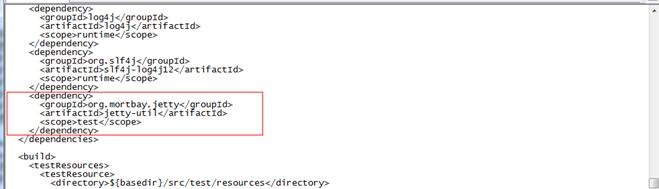
直接修改hadoop-common-project/hadoop-auth/pom.xml,其实就是少了一个包,添加一个dependency:
<dependency>
<groupId>org.mortbay.jetty</groupId>
<artifactId>jetty-util</artifactId>
<scope>test</scope>
</dependency>
3.3 安装Hadoop2.2.0出现不能找到/etc/hadoop目录异常
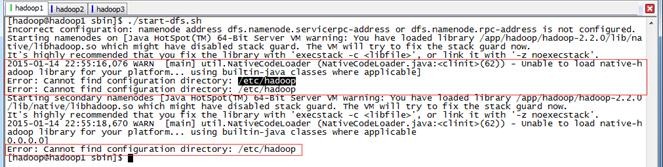
在安装过程中启动HDFS出现如下错误:
2015-01-14 22:55:16,076 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable]
Error: Cannot find configuration directory: /etc/hadoop
Error: Cannot find configuration directory: /etc/hadoop
127.0.0.1 localhost
改为
192.168.0.61 localhost

重启机器即可
Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装的更多相关文章
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 . 安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语 ...
- Spark入门实战系列--9.Spark图计算GraphX介绍及实例
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
随机推荐
- 关于HashTable的遍历方法解析
要遍历一个Hashtable,api中提供了如下几个方法可供我们遍历: keys() - returns an Enumeration of the keys of this Hashtable ke ...
- NSData与其它类型的转换
NSString转换成NSData对象 NSData *xmlData = [@"testdata" dataUsingEncoding:NSUTF8StringEncoding] ...
- NYOJ 536 开心的mdd(DP)
开心的mdd 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 himdd有一天闲着无聊,随手拿了一本书,随手翻到一页,上面描述了一个神奇的问题,貌似是一个和矩阵有关的 ...
- ansible 自动化(1)
安装篇: yum安装 1.安装第三方epel源 centos 6的epel rpm -ivh http://mirrors.sohu.com/fedora-epel/6/x86_64/epel-rel ...
- Replication的犄角旮旯(二)--寻找订阅端丢失的记录
<Replication的犄角旮旯>系列导读 Replication的犄角旮旯(一)--变更订阅端表名的应用场景 Replication的犄角旮旯(二)--寻找订阅端丢失的记录 Repli ...
- C++ REST SDK的基本用法
微软开发了一个开源跨平台的http库--C++ REST SDK(http://casablanca.codeplex.com/),又名卡萨布兰卡Casablanca,有个电影也叫这个名字,也许这个库 ...
- Wix 安装部署教程(十五) --CustomAction的七种用法
在WIX中,CustomAction用来在安装过程中执行自定义行为.比如注册.修改文件.触发其他可执行文件等.这一节主要是介绍一下CustomAction的7种用法. 在此之前要了解InstallEx ...
- angularjs组件之input mask
今天将奉献一个在在几个angularjs项目中抽离的angular组件 input mask.在我们开发中经常会对用户的输入进行控制,比如日期,货币格式,或者纯数字格式之类的限制,这就是input m ...
- [翻译]AKKA笔记 - LOGGING与测试ACTORS -2 (二)
3.THROW IN A LOGBACK.XML 现在我们把SLF4J日志配置在logback. <?xml version="1.0" encoding="UTF ...
- [数据库事务与锁]详解五: MySQL中的行级锁,表级锁,页级锁
注明: 本文转载自http://www.hollischuang.com/archives/914 在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的 ...