[151116 记录] 使用Python3.5爬取豆瓣电影Top250
这一段时间,一直在折腾Python爬虫。已有的文件记录显示,折腾爬虫大概个把月了吧。但是断断续续,一会儿鼓捣python、一会学习sql儿、一会调试OpenCV,结果什么都没学好。前几天,终于耐下心来,决定还是用python做一个小东西。想了想,决定从爬"豆瓣电影Top250"开始。大学的时候,经常根据豆瓣评分选电影。大二大三的时候,有段时间,基本上一天一部地刷。那时候,也真清闲... 后来top电影看的差不多了,对国产片基本上没什么胃口。后来就改行看动漫来消遣,还记得考研那会儿,追《进击的巨人》,熬夜看呐。然后今年的封杀令让《东京食尸鬼》、《寄生兽》、《火星异种》、《死神》等等一大批动漫都给禁播了。。。哎,扯远了。。。
1.准备工作
准备好工具 Python3.5 + requests + lxml + mysqlconnector
2.分析网页
豆瓣电影排行榜里,每个条目都是一致的,例如《这个杀手不太冷》的html代码如下:
<li>
<div class="item">
<div class="pic">
<em class="">2</em>
<a href="https://movie.douban.com/subject/1295644/">
<img alt="这个杀手不太冷" src="https://img3.doubanio.com/view/movie_poster_cover/ipst/public/p511118051.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1295644/" class="">
<span class="title">这个杀手不太冷</span>
<span class="title"> / Léon</span>
<span class="other"> / 杀手莱昂 / 终极追杀令(台)</span>
</a>
</div>
<div class="bd">
<p class="">
导演: 吕克·贝松 Luc Besson 主演: 让·雷诺 Jean Reno / 娜塔丽·波特曼 ...
<br> 1994 / 法国 / 剧情 动作 犯罪
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.4</span>
<span property="v:best" content="10.0"></span>
<span>620387人评价</span>
</div>
<p class="quote">
<span class="inq">怪蜀黍和小萝莉不得不说的故事。</span>
</p>
</div>
</div>
</div>
</li>
接下来,要解析的是:
- 排名:2
- 中文名:这个杀手不太冷
- 外文名:Léon
- 评分 : 9.4
- 简评: 怪蜀黍和小萝莉不得不说的故事。
使用lxml解析网页
先解析出item条目: item = root.xpath('//ol/li/div[@class="item"]')
然后排名: rank = item.xpath('./div[@class="pic"]/em[@text()]')[0]
写出python代码,运行结果:
1 9.6 希望让人自由。
肖申克的救赎 ,The Shawshank Redemption
2 9.4 怪蜀黍和小萝莉不得不说的故事。
这个杀手不太冷 ,Léon
3 9.4 一部美国近现代史。
阿甘正传 ,Forrest Gump
4 9.4 风华绝代。
霸王别姬
5 9.5 最美的谎言。
美丽人生 ,La vita è bella
6 9.2 每个人都要走一条自己坚定了的路,就算是粉身碎骨。
海上钢琴师 ,La leggenda del pianista sull'oceano
7 9.4 拯救一个人,就是拯救整个世界。
辛德勒的名单 ,Schindler's List
8 9.2 最好的宫崎骏,最好的久石让。
千与千寻 ,千と千の神し
9 9.3 小瓦力,大人生。
机器人总动员 ,WALLE
10 9.1 失去的才是永恒的。
泰坦尼克号 ,Titanic
...
244 8.2 琼瑶阿姨在韩国的深刻版。
假如爱有天意 ,
245 8.4 爆米花动作电影新标杆。
速度与激情5 ,Fast Five
246 8.4
黑鹰坠落 ,Black Hawk Down
247 8.5 一群演技精湛的戏骨,奉献出一个精致的黑帮小品,成就杜琪峰群戏的巅峰之作。
枪火 ,火
248 8.8 简简单单,回味悠长。
刺猬的优雅 ,Le hérisson
249 8.6 最冷的地方,有最温暖的感情。
帝企鹅日记 ,La marche de l'empereur
250 8.1
疯狂的石头
实现代码:
import requests
from lxml import etree
session = requests.Session()
for id in range(0,251,25):
URL = 'http://movie.douban.com/top250/?start=' + str(id)
req = session.get(URL)
req.encoding = 'utf8' # 设置网页编码格式
root=etree.HTML(req.content) #将request.content 转化为 Element
items = root.xpath('//ol/li/div[@class="item"]')
for item in items:
#注意可能只有中文名,没有英文名;可能没有quote简评
rank,name,alias,rating_num,quote,url = "","","","","",""
try:
url = item.xpath('./div[@class="pic"]/a/@href')[0]
rank = item.xpath('./div[@class="pic"]/em/text()')[0]
title = item.xpath('./div[@class="info"]//a/span[@class="title"]/text()')
name = title[0].encode('gb2312','ignore').decode('gb2312')
alias = title[1].encode('gb2312','ignore').decode('gb2312') if len(title)==2 else ""
rating_num = item.xpath('.//div[@class="bd"]//span[@class="rating_num"]/text()')[0]
quote_tag = item.xpath('.//div[@class="bd"]//span[@class="inq"]')
if len(quote_tag) is not 0:
quote = quote_tag[0].text.encode('gb2312','ignore').decode('gb2312').replace('\xa0','')
print(rank,rating_num,quote)
print(name.encode('gb2312','ignore').decode('gb2312') ,alias.encode('gb2312','ignore').decode('gb2312') .replace('/',','))
except:
print('faild!')
pass
当然,也可使使用数据库保存!
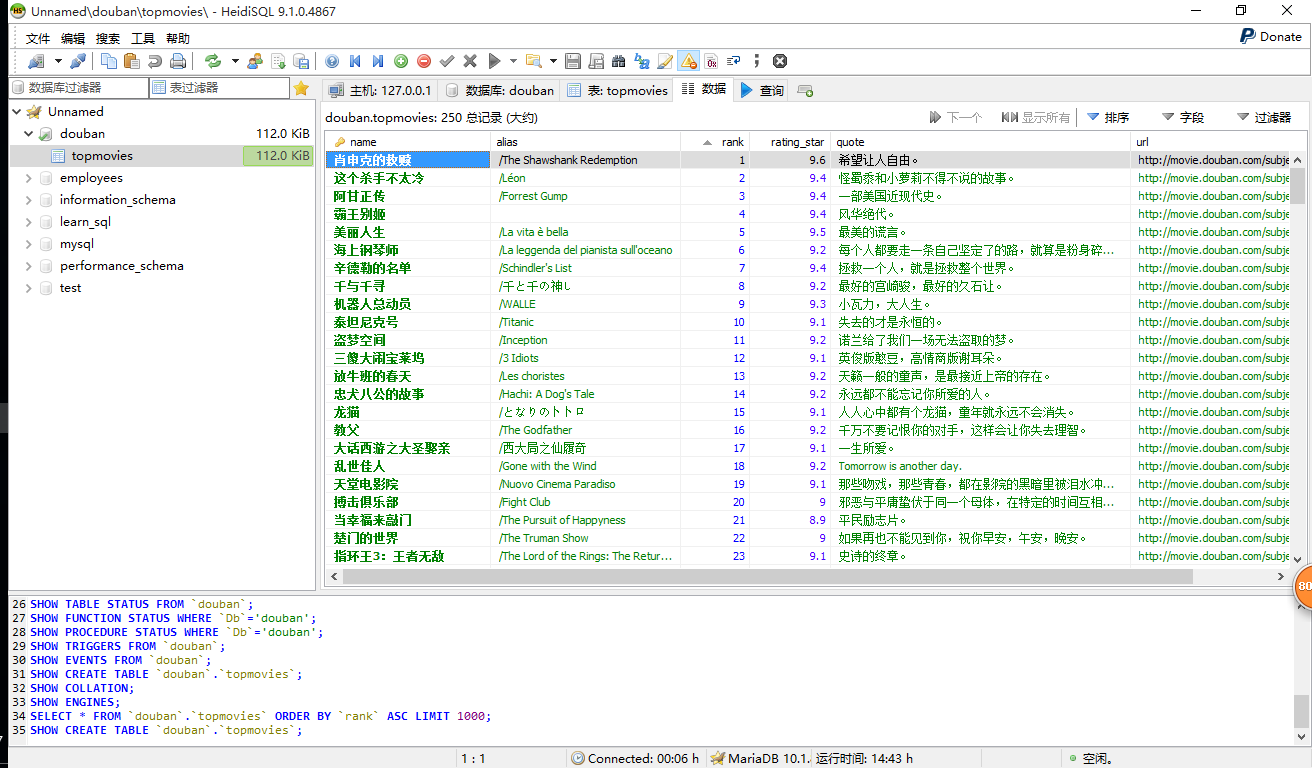
[151116 记录] 使用Python3.5爬取豆瓣电影Top250的更多相关文章
- python3 爬虫---爬取豆瓣电影TOP250
第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter= 分析网址'?'符号后的参数,第一个参数's ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
随机推荐
- thinkphp xml编码函数
/** * XML编码 * @param mixed $data 数据 * @param string $root 根节点名 * @param string $item 数字索引的子节点名 * @pa ...
- c#委托和事件(下) 分类: C# 2015-03-09 08:42 211人阅读 评论(0) 收藏
C#中的委托和事件(下) 引言 如果你看过了 C#中的委托和事件 一文,我想你对委托和事件已经有了一个基本的认识.但那些远不是委托和事件的全部内容,还有很多的地方没有涉及.本文将讨论委托和事件一些更为 ...
- SQL 按月统计(两种方式) 分类: SQL Server 2014-08-04 15:36 154人阅读 评论(0) 收藏
(1)Convert 函数 select Convert ( VARCHAR(7),ComeDate,120) as Date ,Count(In_code) as 单数,Sum(SumTrueNum ...
- ListView 分类: WinForm 2014-07-18 22:03 289人阅读 评论(0) 收藏
一.ListView类(转载) 1.常用的基本属性: (1)FullRowSelect:设置是否行选择模式.(默认为false) 提示:只有在Details视图该属性才有意义. (2) GridLin ...
- uvalive 2326 - Moving Tables(区间覆盖问题)
题目连接:2326 - Moving Tables 题目大意:在一个走廊上有400个教室, 先在有一些桌子要移动, 每次移动需要十分钟, 但是不同房间的桌子可以在同一个十分钟内移动,只要走廊没有被占用 ...
- android 13 5种click事件不同实现方式 比较
第一种:不便于管理. <Button android:id="@+id/btn_Gridlayout" android:layout_width="match_pa ...
- hadoop文件的序列化
目录 1.为什么要序列化? 2.什么是序列化? 3.为什么不用Java的序列化? 4.为什么序列化对Hadoop很重要? 5.Hadoop中定义哪些序列化相关的接口呢? 6.Hadoop 自定义Wri ...
- iOS-UIResponse之事件响应链及其事件传递
UIResponse之事件响应链及其事件传递 我们的App与用户进行交互,基本上是依赖于各种各样的事件.一个视图是一个事件响应者,可以处理点击等事件,而这些事件就是在UIResponder类中定义的. ...
- Linux PATH变量的设置
一般Linux系统,有两个配置文件可以设置PATH变量,一:.bashrc 二:.bash_profile; 还有一种方法可以临时设置PATH变量(三) 一: 1.编辑.bashrc,添加 expo ...
- centos mysql 编译安装
centos mysql 编译安装 1.安装 创建MySQL用户 sudo useradd mysql 下载MySQL的源码包,我们这里使用的时5.5.18 安装依赖 sudo yum -y inst ...