Flask中的后端并发思考(以Mysql:too many connections为例)
之前写过一篇《CentOS 下部署Nginx+Gunicorn+Supervisor部署Flask项目》,最近对该工程的功能进行了完善,基本的功能单元测试也做了。
觉得也是时候进行一下压力测试了,所以利用Jmeter对部署到服务器的项目进行了简单的压力测试。在之前的笔记中写过,这个API的资源获取,为了不对数据库造成大量的读取压力,采用了Redis进行缓存,所以大量的GET方法下的接口都很坚挺,基本没有出乱子,但是在其中一个需要Log数据到Mysql的接口出问题了,具体表示是数据库插入失败。检查服务器上的Mysql日志发现,错误内容为:
ERROR 1040: Too many connections
想起来之前一篇笔记中遇到Mysql server has gone away的问题,其中一步是需要对数据库的time_out进行设置,所以自然而然,搜索这个问题的解决方案中,最初步的自然是增大mysql对于最大连接数的上限:
show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
1 row in set (0.00 sec)
然后对mysql的最大连接数进行修改来尝试解决问题。具体可见参考一。可是这个方法有两个问题:
1.最大连接数设置到多少比较合适?太大Mysql会占用服务资源。
2.极端高并发情况下,只是允许更大的连接,可是Mysql的I/O瓶颈还是会造成有些服务如果等待Mysql操作完成再返回很可能很久甚至超时。
考虑到我这个接口中,是存储日志,也就是大量写入Mysql数据而且无需校检。所以我决定采用异步来解决这个问题:
1.请求过来的时候先处理请求并立即返回给客户端
2.日志写入这个功能做成异步,也就是后台操作,考虑到高并发通常不会太持久,把日志写入的压力分散到后面的时间是比较可行的一个办法。
所以找到了这个异步操作的Python库Celery, 简单来说就是把耗时的操作丢给他去处理,Flask(或者说Gunicorn)不管这个操作而在处理完成请求之后直接返回。
对于为什么Flask应用一步步加上了Redis, 加上了Gunicorn(Gevent),到现在需要Celery, 我画了几张张图来理解。
一个典型的Flask应用(自带调试WSGI):
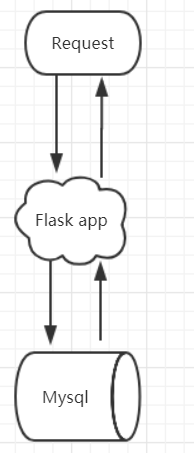
但是这个的问题在于他是阻塞的,每次请求过来没处理完没办法处理下一个请求!所以在调试的时候,会有提示你:
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
所以真正用的时候我们都要吧WSGI更换成Gunicorn, 利用服务器的多进程来达到并发,也就是同时处理多个请求。事实上,在利用了协成的Gevent后,每一个gunicorn的worker还可以处理多个请求:
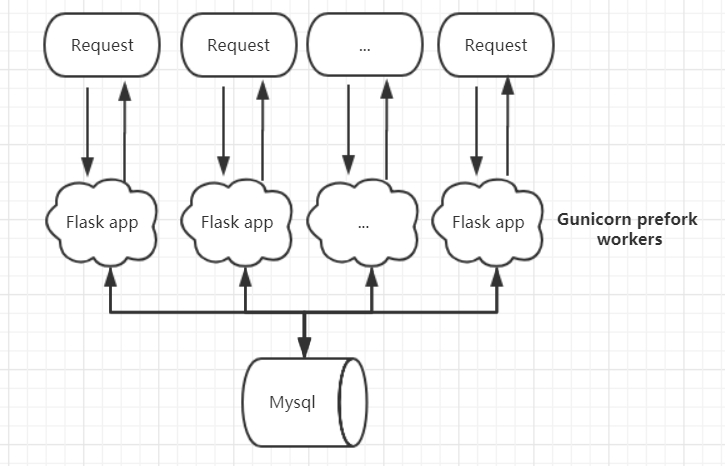
到这一步后的问题是每个worker都要去对mysql的资源进行处理,这就造成数据库压力大而且响应速度慢。所以我们就利用Redis来缓存常用的数据在内存中来达到加速资源访问的目的:
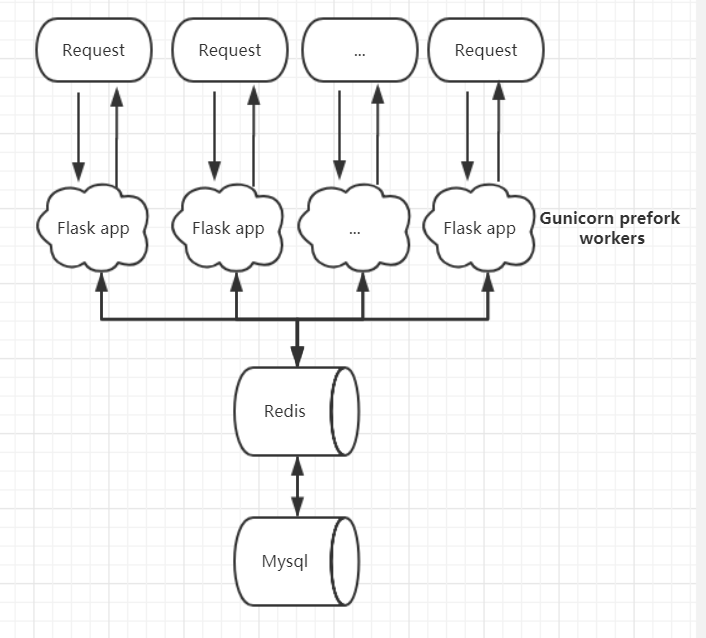
但是,今天的问题出来了,利用Redis达到了对资源缓存减轻数据库压力的目的,但是对Mysql的写入呢,每个worker 每个请求还是要直接写入数据库(比如我的api的Log),那么这个在高并发的时候就是个问题了。所以利用Celery,而celery本身不存储资源,他需要一个中间人来帮忙存储异步处理的数据,既然官方推荐也有Redis我自然就把redis作为中间人。也就是说Celery会以队列的形式,不断的从中间人那里拿到自己的任务并后台进行处理。
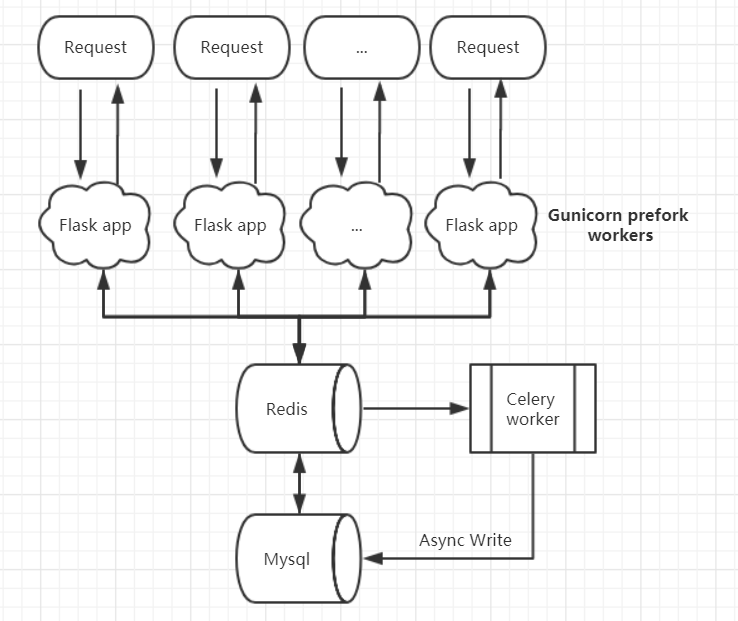
也就是说每次请求,如果还有对数据库的写入,那么我们把它延迟执行而不是等它执行完毕才返回给客户。这样子Flask就可以不断的接收新请求,而且通过对于延迟执行时间的调度,我们可以把高峰时间的写入请求压力分散到后续的时间中去。
总结起来:
1.Gunicorn和gevent保证了flask可以同时处理多个请求
2.利用Redis/Memecached 缓存可以减轻数据库的读取压力
2.但是如果请求耗时(比如大量的数据库插入,发送验证邮件等),你这个进程资源还是有被卡住的可能。
3.而利用Celery来后台处理耗时任务可以保证Flask能够较快响应而且不被阻塞,同时减轻了数据库的高峰写入压力。
注意:
1.Celery的worker和Gunicorn一样需要启动,可以与flask服务放在一起通过supervisor来管理,这样他们可以保持协同工作。
2.Windows的Celery只支持到3.1.25,所以你如果在windows上调试,请指定该版本。
3.如果你的后台任务是操作数据库,操作完成后记得释放数据库连接,例如Session.remove(Sqlalchemy scoped_session).
3.具体的操作步骤可见参考
参考:
1.https://bluemedora.com/mysql-performance-max-connections/
4.官方:Celery - Distributed Task Queue
5.supervisor 启动 celery 及启动中的问题
Flask中的后端并发思考(以Mysql:too many connections为例)的更多相关文章
- [问题][已解决] 并发场景下 "mysql: too many connections" 原因
问题出现是这样的,用node写爬虫, 之前每条数据都是await插入,并且是阻塞的,后来改成了非阻塞,可以并行插入操作,结果一直找不到原因. 后来在日志中找到了 too many connection ...
- 简述C#中IO的应用 RabbitMQ安装笔记 一次线上问题引发的对于C#中相等判断的思考 ef和mysql使用(一) ASP.NET/MVC/Core的HTTP请求流程
简述C#中IO的应用 在.NET Framework 中. System.IO 命名空间主要包含基于文件(和基于内存)的输入输出(I/O)服务的相关基础类库.和其他命名空间一样. System.I ...
- Flask中使用mysql
Flask中使用mysql 先安装相关模块: pip install Flask-MySQL 先准备一下数据库 登录: mysql -u root -p 创建Database和创建Table ...
- 关于flask(前后端分离)的后端开发的小白笔记整理(含postman,jwt,json,SQLAlchemy等)
首先是提醒自己的一些唠嗑: 学会劳逸结合,文档看累了可以看视频,动手操作很关键,遇到问题先动脑子冷静地想,不要跟着步骤都不带脑子,想不出来了再查一查!有时候打出来的代码很虚,但是实践不花钱,实践出真知 ...
- 性能测试中TPS和并发用户数
并发用户数与TPS之间的关系 1. 背景 在做性能测试的时候,很多人都用并发用户数来衡量系统的性能,觉得系统能支撑的并发用户数越多,系统的性能就越好:对TPS不是非常理解,也根本不知道它们之间的关系 ...
- 使用flask开发网站后端
Flask 是一个用于 Python 的微型网络开发框架,可以用于快速的搭建一个小型的网站. 我的搜索引擎:http://www.abelkhan.com 就是基于flask开发 一个flask的He ...
- Flask中使用数据库连接池 DBUtils ——(4)
DBUtils是Python的一个用于实现数据库连接池的模块. 此连接池有两种连接模式: 模式一:为每个线程创建一个连接,线程即使调用了close方法,也不会关闭,只是把连接重新放到连接池,供自己线程 ...
- 第四篇flask中模板语言 jinja2
Flask中默认的模板语言是Jinja2 首先我们要在后端定义几个字符串,用于传递到前端 STUDENT = {, 'gender': '中'}, STUDENT_LIST = [ {, 'gende ...
- flask框架----整合Flask中的目录结构
一.SQLAlchemy-Utils 由于sqlalchemy中没有提供choice方法,所以借助SQLAlchemy-Utils组件提供的choice方法 import datetime from ...
随机推荐
- Louvain Modularity Fast unfolding of communities in large networks
Louvain Modularity Fast unfolding of communities in large networks https://arxiv.org/pdf/0803.0476.p ...
- Tomcat学习笔记【3】--- Tomcat目录结构
本文主要讲Tomcat包的目录结构. 1 bin目录 这个目录只要是存放了一些bat文件或者sh文件.比如说我们需要启动tomcat的bat文件就在这个目录下. 2 conf 这个目录中存放的都是一些 ...
- Yii 框架 URL路径简化
Yii 框架的訪问地址若不简化会让人认为非常繁琐.未简化的地址一般格式例如以下: http://localhost:80/test/index.php?r=xxx/xxx/xxx 若是带有參数会更复杂 ...
- python网络爬虫之requests库 二
前面一篇在介绍request登录CSDN网站的时候,是采用的固定cookie的方式,也就是先通过抓包的方式得到cookie值,然后将cookie值加在发送的数据包中发送到服务器进行认证. 就好比获取如 ...
- 升级pip3的正确姿势
如果你的电脑里装了两个python,就会有两个pip,一个是pip2,一个是pip3,还有可能出现一个既没有2也没有3的pip,一般情况下,pip等于pip2 有时候我们使用pip安装东西会提示我们p ...
- fragment 动态加载
/** * 测试使用Fragment(动态使用) 1. * 使用FragmentManager和FragmentTransaction动态使用一个Fragment 2. 方式: * add(viewI ...
- swift和oc的混编
一.Swift工程中加入oc代码 1.在将oc代码加入到Swift工程的时候Xcode会自动创建一个桥接文件“yourProgectName-Bridging-Header.h”,如果没有创建或者删除 ...
- iOS开发中集成Reveal
[转]http://blog.devzeng.com/blog/ios-reveal-integrating.html 配置方式一简介有效. Reveal 是一个界面调试工具.使用Reveal,我们可 ...
- American Heritage usaco
基础题,主要思路是找到根,然后分别递归即可: #include<iostream> #include<cstring> #include<string> #incl ...
- LightOJ - 1265 Island of Survival —— 概率
题目链接:https://vjudge.net/problem/LightOJ-1265 1265 - Island of Survival PDF (English) Statistics F ...