【读书笔记】周志华《机器学习》第三版课后习题讨<第一章-绪论>
虽然是绪论。。但是。。。真的有点难!不管怎么说,一点点前进吧。。。
声明一下答案不一定正确,仅供参考,为本人的作答,希望大神们能多多指教~
1.1 表1.1中若只包含编号为1和4的两个样例,试给出相应的版本空间。
解答:本题考查版本空间、假设空间的概念。简而言之,假设空间是该问题情景下,所有的取值可能性(包括单属性泛化、二属性泛化、X属性泛化……全泛化的情况),而版本空间则是指在测试用样本情境下,满足样本内所有正例的假设集合(一般版本空间内的假设都是带有属性泛化)。
我们先来看一下1和4样例组成的表,以供接下来探讨进行参考:
| 编号 | 色泽 | 根蒂 | 敲声 | 好瓜? |
| 1 | 青绿 | 蜷缩 | 浊响 | 是 |
| 4 | 乌黑 | 稍蜷 | 沉闷 | 否 |
解题中,要紧扣“我只知道这张表的信息,去推测整体”的思想。根据此表信息,假设空间是(2+1)X(2+1)X(2+1)+1=28种假设,版本空间则应该是假设空间内能确定1是好瓜,同时刚好能排除4是好瓜的所有可能,所以应该是(色泽=青绿)∧(根蒂=蜷缩)∧(敲声=浊响),以及本例的一个属性泛化(三种),和两个属性泛化(三种),共7种。不可加入三属性泛化,因为(色泽=*)∧(根蒂=*)∧(敲声=*),这种情况会把编号4也判定为好瓜,与样本不符。
1.2 与使用单个合取式来进行假设表示相比,使用“析合范式”将使得假设空间具有更强的表示能力。若使用最多包含K个合取式的析合范式来表达表1.1西瓜分类问题的假设空间,试估算共有多少种可能的假设。
解答:本题考查一些离散数学的知识,同时为后文提示了使假设空间具有更强表示能力的一种编程表达。我们再来看一下表1.1:
| 编号 | 1 | 2 | 3 | 4 |
| 色泽 | 青绿 | 乌黑 | 青绿 | 乌黑 |
| 根蒂 | 蜷缩 | 蜷缩 | 硬挺 | 稍蜷 |
| 敲声 | 浊响 | 浊响 | 清脆 | 沉闷 |
| 好瓜 | 是 | 是 | 否 | 否 |
根据此表,总共有三种属性,每种属性分别有2,3,3种取值。根据假设空间计算式,应该有3X4X4+1=49种可能假设。由于问了几个人都不确定空集是否加入析合范式,所以下文讨论除去空集,48种假设。
其中,题设要求的析合范式,无非就是若干个上述假设的组合。可以理解为上述48种假设挑一种,挑2种,挑3种……挑48种,以此类推。不考虑冗余情况,很容易推算出以下的公式:
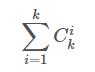
该公式计算出的值减1即可(不减1则是把空集包含在析合范式内的情况),同时,这个式子的值也等于2的K次方。
但是,要考虑冗余情况。根据离散数学的知识,如果(A=a)∨(A=*),则该项可以化简成(A=*).那么上式包括的结果内,会包含大量冗余。经过计算,这个问题在总假设可能在48种的情况下,远没有2的48次方这么大的量。具体的计算将会在另外一片文章内说明:
1.3 若数据包含噪声,则假设空间中有可能不存在与所有训练样本都一致的假设。在此情形下,试设计一种归纳偏好用于假设选择。
解答:题目换一种意思就是,可能无法找到一种标准,既能区分所有正例,也能排除所有反例。相当于还是一个过拟合和欠拟合的一个问题引入。这个问题是一定没有标准答案的。思路两种,一种,设定一个阈值,对大部分属性与训练样本正例一致的反例,也划入正例范畴。另外一种就是,只取最核心、最无异议的正例进行区分。这里不详述。
1.4 本章1.4节在讨论NFL(没有免费的午餐的英文缩写)定理时,默认使用了分类错误率作为性能度量来对分类器进行评估,若换用其他性能度量l,则式1.1将改为:
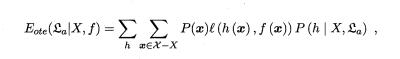 试依然证明“天下没有免费的午餐”。
试依然证明“天下没有免费的午餐”。
解答:不会不会。。。放弃。。。好好去看概率论去。。。
1.5 试简述机器学习能在互联网搜索的哪些环节起到什么作用?
解答:开放题,不多bb
【读书笔记】周志华《机器学习》第三版课后习题讨<第一章-绪论>的更多相关文章
- 周志华-机器学习西瓜书-第三章习题3.5 LDA
本文为周志华机器学习西瓜书第三章课后习题3.5答案,编程实现线性判别分析LDA,数据集为书本第89页的数据 首先介绍LDA算法流程: LDA的一个手工计算数学实例: 课后习题的代码: # coding ...
- 机器学习周志华 pdf统计学习人工智能资料下载
周志华-机器学习 pdf,下载地址: https://u12230716.pipipan.com/fs/12230716-239561959 统计学习方法-李航, 下载地址: https://u12 ...
- 【Todo】【读书笔记】机器学习-周志华
书籍位置: /Users/baidu/Documents/Data/Interview/机器学习-数据挖掘/<机器学习_周志华.pdf> 一共442页.能不能这个周末先囫囵吞枣看完呢.哈哈 ...
- (二)《机器学习》(周志华)第4章 决策树 笔记 理论及实现——“西瓜树”——CART决策树
CART决策树 (一)<机器学习>(周志华)第4章 决策树 笔记 理论及实现——“西瓜树” 参照上一篇ID3算法实现的决策树(点击上面链接直达),进一步实现CART决策树. 其实只需要改动 ...
- 《AlphaGo世纪对决》与周志华《机器学习》观后感
这两天看了<AlphaGo世纪对决>纪录片与南大周志华老师的<机器学习>,想谈谈对人工智能的感想. 首先概述一下视频的内容吧,AlphaGo与李世石对战的过程大家都有基本的了解 ...
- 【深度森林第三弹】周志华等提出梯度提升决策树再胜DNN
[深度森林第三弹]周志华等提出梯度提升决策树再胜DNN 技术小能手 2018-06-04 14:39:46 浏览848 分布式 性能 神经网络 还记得周志华教授等人的“深度森林”论文吗?今天, ...
- 周志华《机器学习》高清电子书pdf分享
周志华<机器学习>高清电子书pdf下载地址 下载地址1:https://545c.com/file/20525574-415455837 下载地址2: https://pan.baidu. ...
- 偶尔转帖:AI会议的总结(by南大周志华)
偶尔转帖:AI会议的总结(by南大周志华) 说明: 纯属个人看法, 仅供参考. tier-1的列得较全, tier-2的不太全, tier-3的很不全. 同分的按字母序排列. 不很严谨地说, tier ...
- 【转载】 AI会议的总结(by南大周志华)
原文地址: https://blog.csdn.net/LiFeitengup/article/details/8441054 最近在查找期刊会议级别的时候发现这篇博客,应该是2012年之前的内容,现 ...
随机推荐
- 【STSRM10】dp只会看规律
[算法]区间DP [题意]平面上有n个点(xi,yi),用最少个数的底边在x轴上且面积为S的矩形覆盖这些点(在边界上也算覆盖),n<=100. [题解]随机大数据下,贪心几乎没有错误,贪心出奇迹 ...
- lua滚动文字效果
基本的思想都是创建一个clippingNode,将要截取的节点添加到clippingNode中,节点加上action即可. 下面是左右滚动的代码,如果是上下滚动,更简单了,只需修改Y坐标即可,都不用动 ...
- 【洛谷 T47488】 D:希望 (点分治)
题目链接 看到这种找树链的题目肯定是想到点分治的. 我码了一下午,\(debug\)一晚上,终于做到只有两个点TLE了. 我的是不完美做法 加上特判\(A\)了这题qwq 记录每个字母在母串中出现的所 ...
- base--AuditObject
//参考base-4.0.2.jarpublic class AuditObject extends HashMap<String, Object> implements TimeRefe ...
- Python中的subprocess模块
Subprocess干嘛用的? subprocess模块是python从2.4版本开始引入的模块.主要用来取代 一些旧的模块方法,如os.system.os.spawn*.os.popen*.comm ...
- C++学习之路(三):volatile关键字
volatile是c++中的一个关键字.用volatile修饰的变量,具有三个性质:易变性 (一)易变性: 由于编译器对代码执行的优化,两条赋值语句,下一条语句可能会直接从上一条语句使用的寄存器中取得 ...
- Linux汇编教程03:大小比较操作
我们在上一讲中,简单了解了汇编程序大概的样子.接下来我们来了解一下,汇编程序的大小比较操作.所以我们以编写寻找一堆数中的最大值作为学习的载体. 在编写程序之前,先要分析我们的目的,在得出解决方案. 目 ...
- caffe Python API 之卷积层(Convolution)
1.Convolution层: 就是卷积层,是卷积神经网络(CNN)的核心层. 层类型:Convolution lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配 ...
- 我的新博客地址http://xxxbw.github.io/
最近在学github,在github搭了个博客,以后也会使用另外一个博客.有兴趣的小伙伴可以看看~ 地址:http://xxxbw.github.io/
- java中的Map集合
Map接口 Map为一个接口.实现Map接口的类都有一个特点:有键值对,将键映射到值的对象. Map不能包含重复的键,每个键可以映射到最多一个值. Map常见的接口方法有: V put(K key, ...