Linux3.10.0块IO子系统流程(5)-- 为SCSI命令准备聚散列表
SCSI数据缓冲区组织成聚散列表的形式。Linux内核中表示聚散列表的基本数据结构是scatterlist,虽然名字中有list,但它只对应一个内存缓冲区,聚散列表就是多个scatterlist的组合。这种组合是链表+数组的结合。这是因为他使用的内存以页面为基本单位分配,每个页面相当于一个scatterlist。每个scatterlist以链表方式组织起来。
/*
* Function: scsi_init_io()
*
* Purpose: SCSI I/O initialize function.
*
* Arguments: cmd - Command descriptor we wish to initialize
*
* Returns: 0 on success
* BLKPREP_DEFER if the failure is retryable
* BLKPREP_KILL if the failure is fatal
*/
int scsi_init_io(struct scsi_cmnd *cmd, gfp_t gfp_mask)
{
struct request *rq = cmd->request; // 初始化sg列表
int error = scsi_init_sgtable(rq, &cmd->sdb, gfp_mask);
if (error)
goto err_exit; // 如果是双向请求,则为关联的request分配SCSI数据缓冲区,用于另一方向的数据传输,然后调用scsi_init_sgtable分配聚散列表,最后进行映射
if (blk_bidi_rq(rq)) {
struct scsi_data_buffer *bidi_sdb = kmem_cache_zalloc(
scsi_sdb_cache, GFP_ATOMIC);
if (!bidi_sdb) {
error = BLKPREP_DEFER;
goto err_exit;
} rq->next_rq->special = bidi_sdb;
error = scsi_init_sgtable(rq->next_rq, bidi_sdb, GFP_ATOMIC);
if (error)
goto err_exit;
} /*
* 如果是完整性请求,即原始bio中带有完整性载荷,则调用blk_rq_count_integrity_sg计算完整性数据段的数目
* 然后调用scsi_alloc_sgtable分配聚散列表,再调用blk_rq_map_integrity_sg将完整性数据映射到这个聚散列表,最后更新聚散列表已映射的项数
* 实际上,完整性请求的处理过程概括了scsi_init_sgtable的操作流程,它实际上是这个过程的一个封装
* 即调用scsi_alloc_sgtable分配指定数据数据段的聚散列表,然后调用blk_rq_map_sg进行映射,最后更新列表已映射的项数
*/
if (blk_integrity_rq(rq)) {
struct scsi_data_buffer *prot_sdb = cmd->prot_sdb;
int ivecs, count; BUG_ON(prot_sdb == NULL);
ivecs = blk_rq_count_integrity_sg(rq->q, rq->bio); if (scsi_alloc_sgtable(prot_sdb, ivecs, gfp_mask)) {
error = BLKPREP_DEFER;
goto err_exit;
} count = blk_rq_map_integrity_sg(rq->q, rq->bio,
prot_sdb->table.sgl);
BUG_ON(unlikely(count > ivecs));
BUG_ON(unlikely(count > queue_max_integrity_segments(rq->q))); cmd->prot_sdb = prot_sdb;
cmd->prot_sdb->table.nents = count;
} return BLKPREP_OK ; err_exit:
scsi_release_buffers(cmd);
cmd->request->special = NULL;
scsi_put_command(cmd);
return error;
}
blk_rq_map_sg函数如下:
/*
* map a request to scatterlist, return number of sg entries setup. Caller
* must make sure sg can hold rq->nr_phys_segments entries
*/
int blk_rq_map_sg(struct request_queue *q, struct request *rq,
struct scatterlist *sglist)
{
struct bio_vec *bvec, *bvprv;
struct req_iterator iter;
struct scatterlist *sg;
int nsegs, cluster; nsegs = ;
cluster = blk_queue_cluster(q); /*
* for each bio in rq
*/
bvprv = NULL;
sg = NULL;
rq_for_each_segment(bvec, rq, iter) {
__blk_segment_map_sg(q, bvec, sglist, &bvprv, &sg,
&nsegs, &cluster);
} /* segments in rq */ if (unlikely(rq->cmd_flags & REQ_COPY_USER) &&
(blk_rq_bytes(rq) & q->dma_pad_mask)) {
unsigned int pad_len =
(q->dma_pad_mask & ~blk_rq_bytes(rq)) + ; sg->length += pad_len;
rq->extra_len += pad_len;
} if (q->dma_drain_size && q->dma_drain_needed(rq)) {
if (rq->cmd_flags & REQ_WRITE)
memset(q->dma_drain_buffer, , q->dma_drain_size); sg->page_link &= ~0x02;
sg = sg_next(sg);
sg_set_page(sg, virt_to_page(q->dma_drain_buffer),
q->dma_drain_size,
((unsigned long)q->dma_drain_buffer) &
(PAGE_SIZE - ));
nsegs++;
rq->extra_len += q->dma_drain_size;
} if (sg)
sg_mark_end(sg); return nsegs;
}
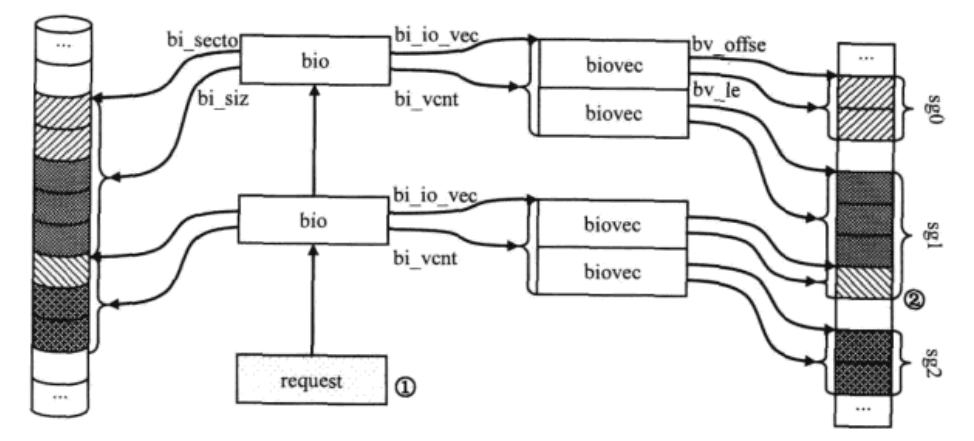
在bio处理过程中的两次合并,第一个合并由IO调度算法负责,它将在磁盘扇区上连续的请求合并到一个request中。第二次合并出现在SCSI策略例程,如果低层驱动支持,则进而将内存中连续的段合并为聚散列表中的一项,如下图,两个bio(每个bio有两段请求)在经过两个合并之后,聚散列表最终有三个项目。
Linux3.10.0块IO子系统流程(5)-- 为SCSI命令准备聚散列表的更多相关文章
- Linux3.10.0块IO子系统流程(0)-- 块IO子系统概述
前言:这个系列主要是记录自己学习Linux块IO子系统的过程,其中代码分析皆基于Linux3.10.0版本,如有描述错误或不妥之处,敬请指出! 参考书籍:存储技术原理分析--基于Linux 2.6内核 ...
- Linux3.10.0块IO子系统流程(3)-- SCSI策略例程
很长时间以来,Linux块设备使用了一种称为“蓄流/泄流”(plugging/unplugging)的技术来改进吞吐率.简单而言,这种工作方式类似浴盆排水系统的塞子.当IO被提交时,它被储存在一个队列 ...
- Linux3.10.0块IO子系统流程(7)-- 请求处理完成
和提交请求相反,完成请求的过程是从低层驱动开始的.请求处理完成分为两个部分:上半部和下半部.开始时,请求处理完成总是处在中断上下文,在这里的主要任务是将已完成的请求放到某个队列中,然后引发软终端让中断 ...
- Linux3.10.0块IO子系统流程(2)-- 构造、排序、合并请求
Linux块设备可以分为三类.分别针对顺序访问物理设备.随机访问物理设备和逻辑设备(即“栈式设备”) 类型 make_request_fn request_fn 备注 SCSI 设备等 从bio构 ...
- Linux3.10.0块IO子系统流程(6)-- 派发SCSI命令到低层驱动
在SCSI策略例程中最后调用scsi_dispatch_cmd将SCSI命令描述符派发给低层驱动进行处理 /** * scsi_dispatch_command - Dispatch a comman ...
- Linux3.10.0块IO子系统流程(4)-- 为请求构造SCSI命令
首先来看scsi_prep_fn int scsi_prep_fn(struct request_queue *q, struct request *req) { struct scsi_device ...
- Linux3.10.0块IO子系统流程(1)-- 上层提交请求
Linux通用块层提供给上层的接口函数是submit_bio.上层在构造好bio之后,调用submit_bio提交给通用块层处理. submit_bio函数如下: void submit_bi ...
- DPA 9.1.85 升级到DPA 10.0.352流程
SolarWinds DPA的升级其实是一件非常简单的事情,这里介绍一下从DPA 9.1.95升级到 DPA 10.0.352版本的流程.为什么要升级呢? DPA给用户发的邮件已经写的非常清楚了(如下 ...
- 【转】linux IO子系统和文件系统读写流程
原文地址:linux IO子系统和文件系统读写流程 我们含有分析的,是基于2.6.32及其后的内核. 我们在linux上总是要保存数据,数据要么保存在文件系统里(如ext3),要么就保存在裸设备里.我 ...
随机推荐
- The All-purpose Zero (最长公共子序列)
题意:求最长公共子序列,但是有个辅助条件,那就是如果那个值为0,那么他可以更换为任意值. 思路:假设现在只剩下没有0的序列是不是就很好求了?那么我们的想法就是看有没有办法将0往最左端或者最有端移动,显 ...
- winfrom进程、线程、用户控件
一.进程 一个进程就是一个程序,利用进程可以在一个程序中打开另一个程序. 1.开启某个进程Process.Start("文件缩写名"); 注意:Process要解析命名空间. 2. ...
- input 输入速度和方向判断、搜索功能的延迟请求
1.input 输入速度和方向判断 var wxApp = {} wxApp.click = function (str,speed) { var lastInput = { d: "&qu ...
- 详解Python变量在内存中的存储
这篇文章主要是对python中的数据进行认识,对于很多初学者来讲,其实数据的认识是最重要的,也是最容易出错的.本文结合数据与内存形态讲解python中的数据,内容包括: 引用与对象 可变数据类型与不可 ...
- Bamboo基础概念
1.project 1)提供报告.展板.连接 |——2.plan 1)指定默认代码仓库(同一个仓库) 2)构建触发条件的配置 3)构建结果的发送与通知 ...
- python核心技术
基本语法 Python的设计目标之一是让代码具备高度的可阅读性.它设计时尽量使用其它语言经常使用的标点符号和英文单字,让代码看起来整洁美观.它不像其他的静态语言如C.Pascal那样需要重复书写声明语 ...
- 判断(if)语句
目标 开发中的应用场景 if语句体验 if语句进阶 综合应用 一 开发中的应用场景 转换成代码 判断的定义 如果 条件满足,才能做某件事 如果 条件不满足,就做另外一件事,或者什么也不做 判断语句 又 ...
- java41 类的高级概念
- poj2142 The Balance
poj2142 The Balance exgcd 应分为2种情况分类讨论 显然我们可以列出方程 ax-by=±d 当方程右侧为-d时,可得 by-ax=d 于是我们就得到了2个方程: ax-by=d ...
- WIN10下,JAVA安装及环境变量配置(cmd可以运行java,却不能运行javac)
1.安装JDK 选择安装目录 安装过程中会出现两次 安装提示 . 第一次是安装 jdk ,第二次是安装 jre .建议两个都安装在同一个java文件夹中的不同文件夹中.(不能都安装在java文件夹的根 ...