Iris数据集实战
本次主要围绕Iris数据集进行一个简单的数据分析, 另外在数据的可视化部分进行了重点介绍.
环境
win8, python3.7, jupyter notebook
目录
1. 项目背景
2. 数据概览
3. 特征工程
4. 构建模型
正文
1. 项目背景
鸢尾属(拉丁学名:Iris L.), 单子叶植物纲, 鸢尾科多年生草本植物, 开的花大而美丽, 观赏价值很高. 鸢尾属约300种, Iris数据集中包含了其中的三种: 山鸢尾(Setosa), 杂色鸢尾(Versicolour), 维吉尼亚鸢尾(Virginica), 每种50个数据, 共含150个数据. 在每个数据包含四个属性: 花萼长度,花萼宽度,花瓣长度,花瓣宽度, 可通过这四个属性预测鸢尾花卉属于 (山鸢尾, 杂色鸢尾, 维吉尼亚鸢尾) 哪一类.
2. 数据概览
数据来源: https://www.kaggle.com/benhamner/python-data-visualizations/data
2.1 读取数据
数据为csv文件, 读取数据:
import pandas as pd
df_Iris = pd.read_csv('Iris.csv')
2.2 查看前/后5行数据
#前5行
df_Iris.head()
#后5行
df_Iris.tail()

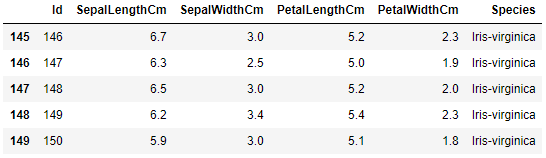
通过这10行数据也就大致确定数据维度150行X6列以及各特征内的基本信息:
Id: 鸢尾花编号
SepaLengthCm: 花萼长度, 单位cm
SepalWidthCm: 花萼宽度, 单位cm
PetalLengthCm: 花瓣长度, 单位cm
PetalWidthCm; 花瓣宽度, 单位cm
Species: 鸢尾花种类.
2.3 查看数据整体信息
#查看数据整体信息
df_Iris.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
Id 150 non-null int64
SepalLengthCm 150 non-null float64
SepalWidthCm 150 non-null float64
PetalLengthCm 150 non-null float64
PetalWidthCm 150 non-null float64
Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.1+ KB
得出信息: 150行, 6列,4个64位浮点数, 1个64位整型, 1个python对象, 数据中无缺失值.
2.4 描述性统计
df_Iris.describe()
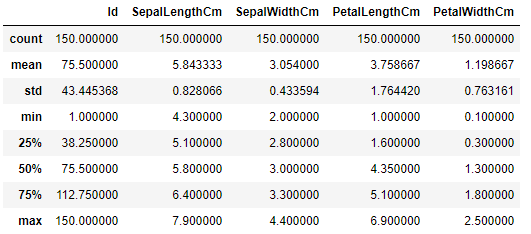
花萼长度最小值4.30, 最大值7.90, 均值5.84, 中位数5.80, 右偏
花萼宽度最小值2.00, 最大值4.40, 均值3.05, 中位数3.00, 右偏
花瓣长度最小值1.00, 最大值6.90, 均值3.76, 中位数4.35, 左偏
花瓣宽度最小值0.10, 最大值2.50, 均值1.20, 中位数1.30, 左偏
按中位数来度量: 花萼长度 > 花瓣长度 > 花萼宽度 > 花瓣宽度
#注意这里是大写的字母O, 不是数字0.
df_Iris.describe(include =['O']).T
总数150, 3个种类, 最大频数为50, 也就是每种都为50个. 注意top里的指的不是Iris-versicolor最多, 是在频数相同的基础上按照字符串长度进行排名.

可以通过这样对每种进行计数:
df_Iris.Species.value_counts()
Iris-versicolor 50
Iris-virginica 50
Iris-setosa 50
Name: Species, dtype: int64
通过以上, 大致了解数据的基本信息, 现想把Species特征中的'Iris-'字符去掉, 进入特征工程环节.
3. 特征工程
3.1 数据清洗
去掉Species特征中的'Iris-'字符.
#第一种方法: 替换
# df_Iris['Species']= df_Iris.Species.str.replace('Iris-','')
#第二种方法: 分割
df_Iris['Species']= df_Iris.Species.apply(lambda x: x.split('-')[1])
df_Iris.Species.unique()
array(['setosa', 'versicolor', 'virginica'], dtype=object)
3.2 数据可视化
Seaborn是一个python的可视化库, 它基于matplotlib, 这使得它能与pandas紧密结合, 并且提供了高级绘图界面, 能更方便地完成探索性分析.
我想在这个项目上对seaborn多加练习, 因此, 会对这部分内容着重介绍.
3.2.1 relplot
import seaborn as sns
import matplotlib.pyplot as plt
#sns初始化
sns.set()
#设置散点图x轴与y轴以及data参数
sns.relplot(x='SepalLengthCm', y='SepalWidthCm', data = df_Iris)
plt.title('SepalLengthCm and SepalWidthCm data analysize')
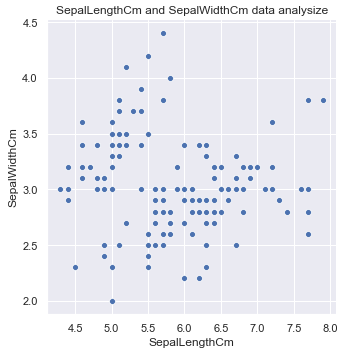
花萼的长度和宽度在散点图上分了两个簇, 而且两者各自都有一定的关系. 鸢尾花又分为三个品种, 不妨看看关于这三个品种的分布.
#hue表示按照Species对数据进行分类, 而style表示每个类别的标签系列格式不一致.
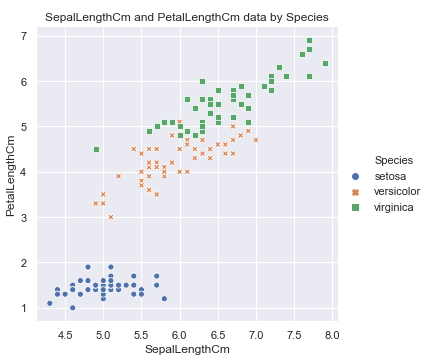
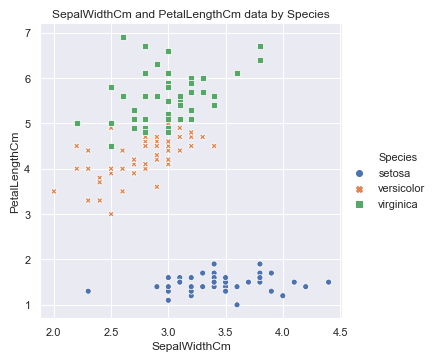
sns.relplot(x='SepalLengthCm', y='SepalWidthCm', hue='Species', style='Species', data=df_Iris )
plt.title('SepalLengthCm and SepalWidthCm data by Species')
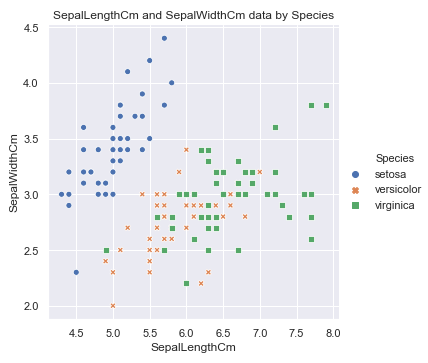
可以看到setosa这种花的花萼长度和宽度有明显的线性关系, 当然其他两种也存在一定的关系, 花萼的属性看完了, 看下花瓣的:
#花瓣长度与宽度分布散点图
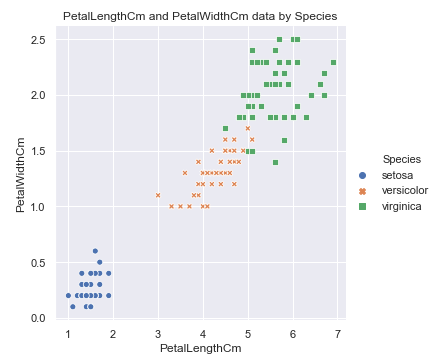
sns.relplot(x='PetalLengthCm', y='PetalWidthCm', hue='Species', style='Species', data=df_Iris )
plt.title('PetalLengthCm and PetalWidthCm data by Species')
花的品种和花瓣的长度, 宽度之间存在一定的关系.
另外, 还可以对比花萼与花瓣的长度, 花萼与花瓣的宽度之间的关系.
#花萼与花瓣长度分布散点图
# sns.relplot(x='SepalLengthCm', y='PetalLengthCm', hue='Species', style='Species', data=df_Iris )
#plt.title('SepalLengthCm and PetalLengthCm data by Species')
#花萼与花瓣宽度分布散点图
sns.relplot(x='SepalWidthCm', y='PetalWidthCm', hue='Species', style='Species', data=df_Iris )
plt.title('SepalWidthCm and PetalWidthCm data by Species')
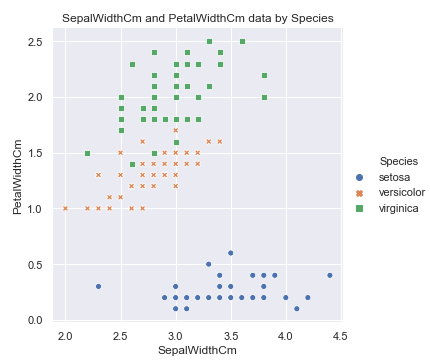
花萼的长度与花瓣的宽度, 花萼的宽度与花瓣的长度之间应当也存在某种关系:
#花萼的长度与花瓣的宽度分布散点图
# sns.relplot(x='SepalLengthCm', y='PetalWidthCm', hue='Species', style='Species', data=df_Iris )
#plt.title('SepalLengthCm and PetalWidthCm data by Species')
#花萼的宽度与花瓣的长度分布散点图
sns.relplot(x='SepalWidthCm', y='PetalLengthCm', hue='Species', style='Species', data=df_Iris )
plt.title('SepalWidthCm and PetalLengthCm data by Species')
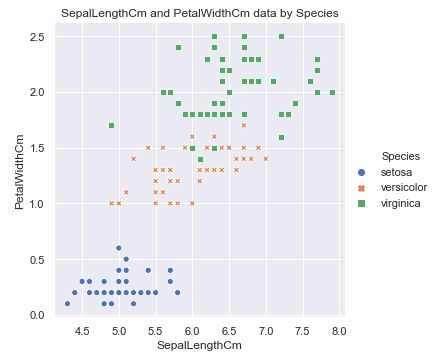
Id编号与花萼长度, 花萼宽度, 花瓣长度, 花瓣宽度之间有没有关系呢:
#花萼长度与Id之间关系图
sns.relplot(x="Id", y="SepalLengthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('SepalLengthCm and Id data analysize')
#花萼宽度与Id之间关系图
sns.relplot(x="Id", y="SepalWidthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('SepalWidthCm and Id data analysize')
#花瓣长度与Id之间关系图
sns.relplot(x="Id", y="PetalLengthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('PetalLengthCm and Id data analysize')
#花瓣宽度与Id之间关系图
sns.relplot(x="Id", y="PetalWidthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('PetalWidthCm and Id data analysize')
可以得到信息: Id中前50个为setosa, 51到100为versicolour, 101到150为Virginica, 以及每个种类对应属性值的范围, 每个种类中的属性与其对应的Id没有明确的关系.

3.2.2 jointplot
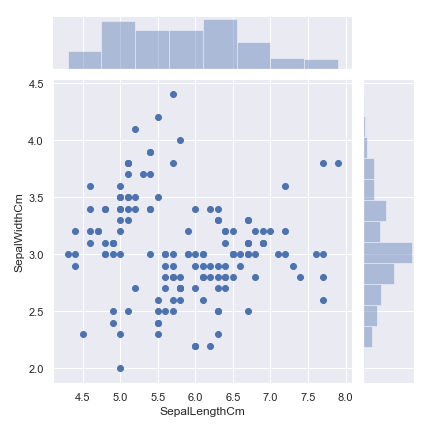
sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=df_Iris)
sns.jointplot(x='PetalLengthCm', y='PetalWidthCm', data=df_Iris)
散点图和直方图同时显示, 可以直观地看出哪组频数最大, 哪组频数最小.

对于频数的值, 在散点图上数点的话, 显然效率太低, 还易出错, 下面引出distplot
3.2.3 distplot
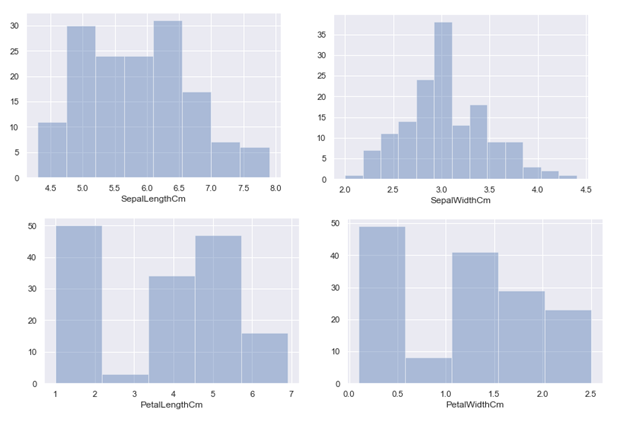
#绘制直方图, 其中kde=False表示不显示核函数估计图,这里为了更方便去查看频数而设置它为False.
# sns.distplot(df_Iris.SepalLengthCm,bins=8, hist=True, kde=False)
# sns.distplot(df_Iris.SepalWidthCm,bins=13, hist=True, kde=False)
# sns.distplot(df_Iris.PetalLengthCm, bins=5, hist=True, kde=False)
sns.distplot(df_Iris.PetalWidthCm, bins=5, hist=True, kde=False)
我这里的分组是按照上面jointplot里的组数进行设置, 现在就很直观地看到各组对应的频数
前面我们已经通过describe()方法计算出四个属性所对应的四分位数, 最大值以及最小值等统计量. 这些均是以表格的形式展示, 我们下面就介绍怎么以图样的形式展示四分位数.
3.2.4 boxplot
boxplot所绘制的就是箱线图, 它能显示出一组数据的最大值, 最小值, 四分位数以及异常点.
对于异常点的定义: 区间[Q1-1.5IQR, Q3+1.5IQR]之外的点, 其中Q1下四分位数(25%), Q3上四分位数(75%), IQR=Q3-Q1
在seaborn.boxplot中, 箱线图的画法分两种情况
如果数据中无异常点, 那么箱线图的下边缘就是数据中的最小值, 上边缘就是数据中的最大值, 即下图的实线部分(虚线以及红点部分不会显示)
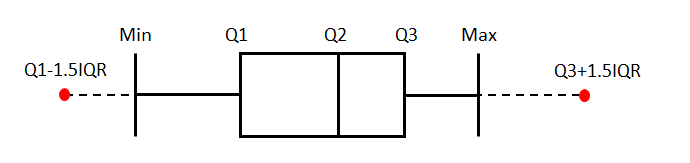
如果数据中有异常点, 那么箱线图的下边缘Limit1指的是区间[Q1-1.5IQR, Q3+1.5IQR]内的最小值, 上边缘Limit2指的是区间内的最大值, 即下图的实线部分(虚线以及红点部分不会显示)

#比如数据中的SepalLengthCm属性
sns.boxplot(x='SepalLengthCm', data=df_Iris)
#比如数据中的SepalWidthCm属性
sns.boxplot(x='SepalWidthCm', data=df_Iris)
为了更直观地对比四个属性之间的关系, 我将四个属性对应的数值合并在新的DataFrame Iris中.
#对于每个属性的data创建一个新的DataFrame
Iris1 = pd.DataFrame({"Id": np.arange(1,151), 'Attribute': 'SepalLengthCm', 'Data':df_Iris.SepalLengthCm, 'Species':df_Iris.Species})
Iris2 = pd.DataFrame({"Id": np.arange(151,301), 'Attribute': 'SepalWidthCm', 'Data':df_Iris.SepalWidthCm, 'Species':df_Iris.Species})
Iris3 = pd.DataFrame({"Id": np.arange(301,451), 'Attribute': 'PetalLengthCm', 'Data':df_Iris.PetalLengthCm, 'Species':df_Iris.Species})
Iris4 = pd.DataFrame({"Id": np.arange(451,601), 'Attribute': 'PetalWidthCm', 'Data':df_Iris.PetalWidthCm, 'Species':df_Iris.Species})
#将四个DataFrame合并为一个.
Iris = pd.concat([Iris1, Iris2, Iris3, Iris4])
#绘制箱线图
sns.boxplot(x='Attribute', y='Data', data=Iris)
对下图做一下简单分析: 就中位数来说, SepalLenthCm > PetalLengthCm > SepalWidthCm > PetalWidthCm; 就波动程度来说, PetalLengthCm > PetalWidthCm > SepalLengthCm > SepalWidthCm; 就异常值来说, 只有SepalWidthCm中存在异常值.

将鸢尾花的三种种类再加入到箱线图中:
sns.boxplot(x='Attribute', y='Data',hue='Species', data=Iris)
这样就很容易能够对比三个种类在四个属性中的表现状况:
除了SepalWidthCm属性外, 中位数在其他属性的三种花中均表现为: Virginica > versicolour > setosa
除了setosa种类外, 中位数在其他种类的四个属性中均表现为: SepalLengthCm > PetalLengthCm > SepalWidthCm > PetalWidthCm
下面将介绍一种更高级的四分位数展示方式: violinplot
3.2.5 violinplot
violinplot绘制的是琴图, 是箱线图与核密度图的结合体, 既可以展示四分位数, 又可以展示任意位置的密度.
sns.violinplot(x='Attribute', y='Data', hue='Species', data=Iris )
上图中具体细节显示不是很明显, 对于PetalWidthCm都有些模糊了, 下面将拆分成四个小图, 另外为了和箱线图对比, 将箱线图也绘制出来.
#花萼长度
# sns.boxplot(x='Species', y='SepalLengthCm', data=df_Iris)
# sns.violinplot(x='Species', y='SepalLengthCm', data=df_Iris)
# plt.title('SepalLengthCm data by Species')
#花萼宽度
# sns.boxplot(x='Species', y='SepalWidthCm', data=df_Iris)
# sns.violinplot(x='Species', y='SepalWidthCm', data=df_Iris)
# plt.title('SepalWidthCm data by Species')
#花瓣长度
# sns.boxplot(x='Species', y='PetalLengthCm', data=df_Iris)
# sns.violinplot(x='Species', y='PetalLengthCm', data=df_Iris)
# plt.title('PetalLengthCm data by Species')
#花瓣宽度
sns.boxplot(x='Species', y='PetalWidthCm', data=df_Iris)
sns.violinplot(x='Species', y='PetalWidthCm', data=df_Iris)
plt.title('PetalWidthCm data by Species')
可以明显看出, 琴图中的白点就是中位数, 黑色矩形的上短边则是上四分位数Q3, 黑色下短边则是下四分位数Q1; 而贯穿矩形的黑线的上端点则代表最小非异常值, 下端点则代表最大非异常值; 黑色矩形外部形状则表示核概率密度估计.
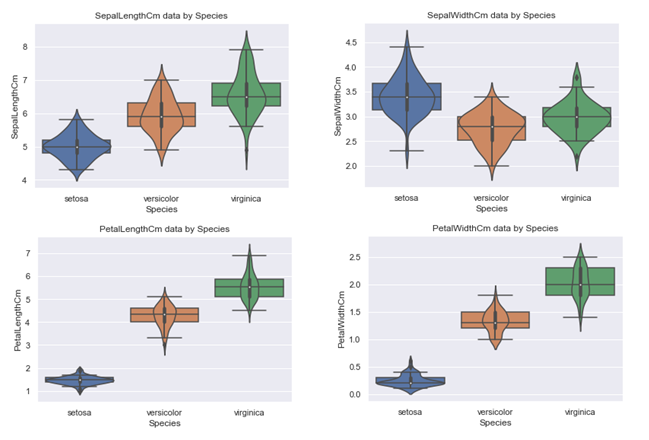
最后介绍一种图形, 它能直接显示各个特征之间的不同关系
3.2.6 pairplot
#删除Id特征, 绘制分布图
sns.pairplot(df_Iris.drop('Id', axis=1), hue='Species')
#保存图片, 由于在jupyter notebook中太大, 不能一次截图
plt.savefig('pairplot.png')
plt.show()
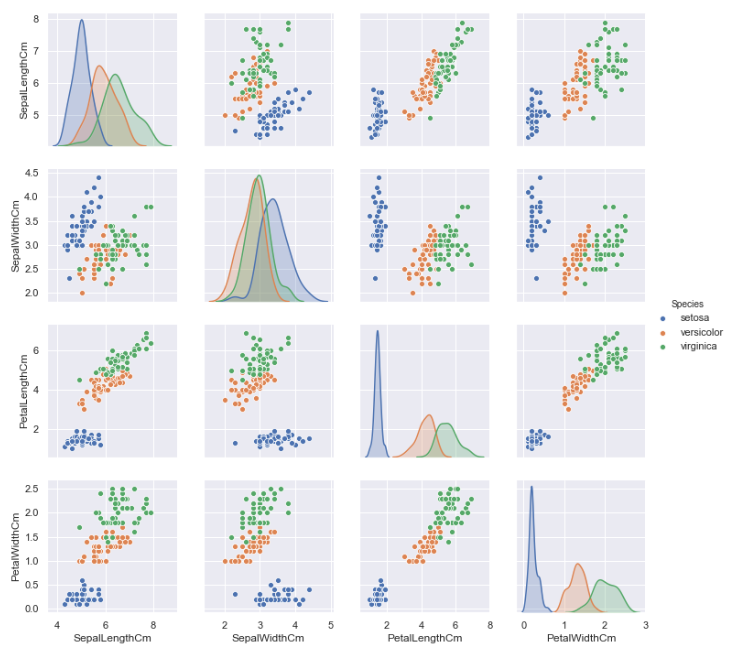
综上, 花萼的长度, 花萼的宽度, 花瓣的长度, 花瓣的宽度与花的种类之间均存在一定的相关性, 且对于这三个种类的分布, satosa在任何一种分布中较其他两者集中; 就同一种花的平均水平来看, 其花萼的长度最长, 花瓣的宽度最短; 就同一属性的平均水平来看, 三种花在除了花萼的宽度外的属性中平均水平均表现为: Virginica > versicolour > setosa.
4. 构建模型
采用决策树分类算法.
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
X = df_Iris[['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm']]
y = df_Iris['Species']
#将数据按照8:2的比例随机分为训练集, 测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#初始化决策树模型
dt = DecisionTreeClassifier()
#训练模型
dt.fit(X_train, y_train)
#用测试集评估模型的好坏
dt.score(X_test, y_test)
0.9666666666666667
在测试集上准确率达到97%,也还不错, 此次没有对决策树模型设置参数, 如果参数设置好了, 想必准确率会更高.
参考:
https://www.kaggle.com/benhamner/python-data-visualizations/notebook
Iris数据集实战的更多相关文章
- 机器学习笔记2 – sklearn之iris数据集
前言 本篇我会使用scikit-learn这个开源机器学习库来对iris数据集进行分类练习. 我将分别使用两种不同的scikit-learn内置算法--Decision Tree(决策树)和kNN(邻 ...
- 用Python实现支持向量机并处理Iris数据集
SVM全称是Support Vector Machine,即支持向量机,是一种监督式学习算法.它主要应用于分类问题,通过改进代码也可以用作回归.所谓支持向量就是距离分隔面最近的向量.支持向量机就是要确 ...
- iris数据集(.csv .txt)免费下载
我看CSDN下载的iris数据集都需要币,我愿意免费共享,希望下载后的朋友们给我留个言 分享iris数据集(供学习使用): 链接: https://pan.baidu.com/s/1Knsp7zn-C ...
- 从Iris数据集开始---机器学习入门
代码多来自<Introduction to Machine Learning with Python>. 该文集主要是自己的一个阅读笔记以及一些小思考,小总结. 前言 在开始进行模型训练之 ...
- 85、使用TFLearn实现iris数据集的分类
''' Created on 2017年5月21日 @author: weizhen ''' #Tensorflow的另外一个高层封装TFLearn(集成在tf.contrib.learn里)对训练T ...
- R语言实现分层抽样(Stratified Sampling)以iris数据集为例
R语言实现分层抽样(Stratified Sampling)以iris数据集为例 1.观察数据集 head(iris) Sampling)以iris数据集为例"> 选取数据集中前6个 ...
- iris数据集预测
iris数据集预测(对比随机森林和逻辑回归算法) 随机森林 library(randomForest) #挑选响应变量 index <- subset(iris,Species != " ...
- 彩虹女神跃长空,Go语言进阶之Go语言高性能Web框架Iris项目实战-项目入口与路由EP01
书接上回,我们已经安装好Iris框架,并且构建好了Iris项目,同时配置了fresh自动监控项目的实时编译,万事俱备,只欠东风,彩虹女神蓄势待发.现在我们来看看Iris的基础功能,如何编写项目入口文件 ...
- IRIS数据集的分析-数据挖掘和python入门-零门槛
所有内容都在python源码和注释里,可运行! ########################### #说明: # 撰写本文的原因是,笔者在研究博文“http://python.jobbole.co ...
随机推荐
- 推荐一些关于学习Html Css和Js的书吗?
前端易学易懂,随着移动互联网的日益兴起,it行业对于前端的需求也在不断的提高,那么从前端小白修炼成为前端大神的这个过程之中,一些必备的枕边书也是必不可少的. 第一本,入门<Head first ...
- SUID、SGID、粘滞位
粘滞位(Stikybit) +t,只有用户自己可以删除自己创建文件,其他用户只能查看,不能删除. 1:创建两个用户 useradd oo ...
- ubuntu-docker入门到放弃(七)Dockerfile简介
一.dockerfile基本结构 最简单的理解就是dockerfile实际上是一些命令的堆叠,有点像最基础的shell脚本,没有if 没有for,就是串行的一堆命令. 一般而言,dockerfile分 ...
- 使用gitbook plugin
使用gitbook plugin. { "title": "xx doc", "author": "morya", &q ...
- 刘志梅 201771010115 《面向对象程序设计(java)》 第七周学习总结
实验七 继承附加实验 实验时间 2018-10-11 1.实验目的与要求 (1)进一步理解4个成员访问权限修饰符的用途: 即将类中的域标记为private,而方法标记为public.任何声明为priv ...
- 深入了解scanf()/getchar()和gets()/cin等函数
转:http://www.cnblogs.com/FCWORLD/archive/2010/12/04/1896511.html 转:问题描述一:(分析scanf()和getchar()读取字符) s ...
- Altmetric
网站名称: Altmetric 所属国家: 美国 网站分类: 科研软件 网站地址: https://www.altmetric.com Altmetric是一个新兴的指标,字面意思是替代指标,但“社会 ...
- Twisted网络库编程实例
于这一周看了python的第三方网络库Twisted,英文看的头比较大,想看英文的话点击这里.如果英文很烂,可以看中文,这里.总的来说我了解到的主要包括以下三个东东:Factory.protocol和 ...
- Python第2天
今天学习的主要内容: pycharm专业版的安装和注册,采用注册码的方式注册. 运算符,+ — * / // % < > <= >= != <> . 基本数据类型 ...
- SOA和微服务的原则及对比
一.面向服务设计的原则 服务可复用:不管是否存在即时复用的机会,服务均被设计为支持潜在的可复用 服务共享一个标准契约:为了与服务提供者交互,消费者需要导入服务提供者的服务契约,这个契约可以是一个IDL ...