【Spark-core学习之七】 Spark广播变量、累加器
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
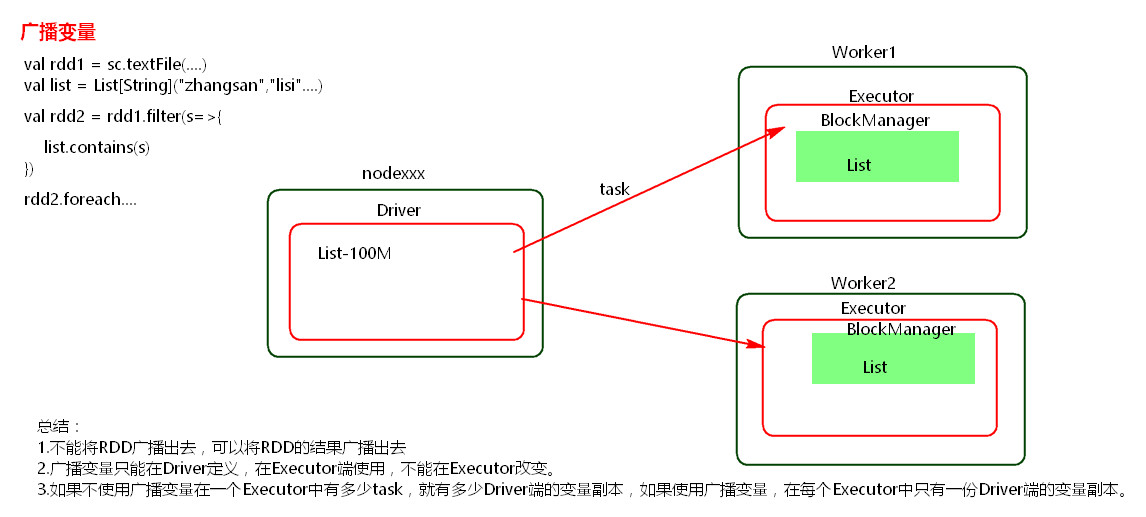
一、广播变量
package com.wjy import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object GuboVal {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("broadcast");
val sc= new SparkContext(conf); val list = List("hello wjy");
val broadcast = sc.broadcast(list);//定义一个广播变量 val linesRDD = sc.textFile("./data/words.txt");
//广播变量可以在excutor使用
linesRDD.filter{x=>broadcast.value.contains(x)}.foreach(println); sc.stop();
}
}
注意:
(1) 能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
(2)广播变量只能在Driver端定义,不能在Executor端定义。
(3) 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
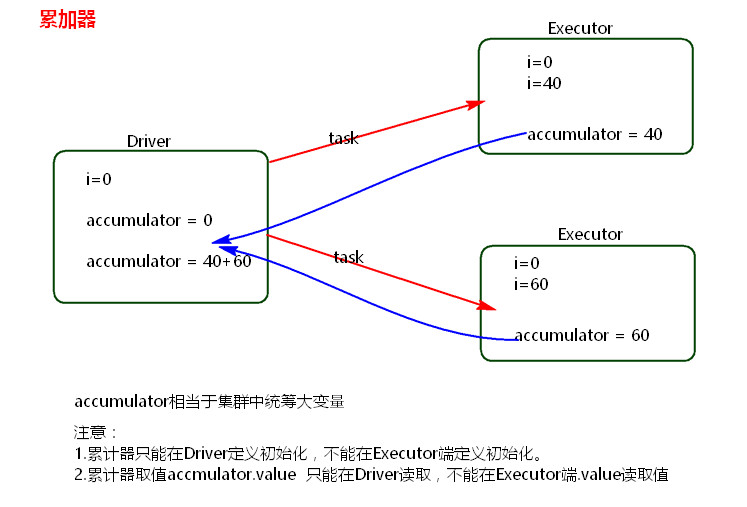
二、累加器
package com.wjy import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object accumulator {
def main(args: Array[String]): Unit = {
val conf =new SparkConf();
conf.setMaster("local").setAppName("accumulator");
val sc = new SparkContext(conf);
//创建累加器 累加器可以是整形 也可以是其他自定义对象
val accumulator = sc.accumulator(0);
//累加器在excutor里累加
sc.textFile("./data/words.txt").foreach(x=>{accumulator.add(1)});
println(accumulator.value); sc.stop();
}
}
注意:
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
参考:
Spark
【Spark-core学习之七】 Spark广播变量、累加器的更多相关文章
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- 【spark core学习---算子总结(java版本) (第1部分)】
map算子 flatMap算子 mapParitions算子 filter算子 mapParttionsWithIndex算子 sample算子 distinct算子 groupByKey算子 red ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- Spark Core源代码分析: Spark任务模型
概述 一个Spark的Job分为多个stage,最后一个stage会包含一个或多个ResultTask,前面的stages会包含一个或多个ShuffleMapTasks. ResultTask运行并将 ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
随机推荐
- mysql可以远程连接的配置
由于配置好几次了,老是会忘记命令,所以记录下来 1.修改配置文件 我的配置文件是/etc/mysql/mysql.conf.d/mysqld.cnf 找到 bind-address = 127.0.0 ...
- 基金 、社保和QFII等机构的重仓股排名评测
基金前15大重仓股持仓股排名 基金重仓前15大个股,相较于同期沪深300的平均收益, 近1月:2.45%, 近3月:10.0%, 近1年:11.22%, 近3年:105.23%. 1,中国平安(SH6 ...
- LeetCode 51 N-Queens II
Follow up for N-Queens problem. Now, instead outputting board configurations, return the total numbe ...
- 【AI】神经网络基本词汇
neural networks 神经网络activation function 激活函数hyperbolic tangent 双曲正切函数bias units 偏置项activation 激活值for ...
- linux telnet检测与某个端口是否开通
转自:http://blog.51cto.com/meiling/1982402 一:telnet此法常被用来检测是个远端端口是否通畅. 测试域名: # telnet baidu.com 80 Try ...
- 编译PHP扩展amqp & php消息队列 rabbitmq
首先介绍下AMQP: AMQP——高级消息队列协议,目前比较有名气的实现大概就是大名鼎鼎的RabbitMQ了. RabbitMQ是一个在AMQP基础上完成的,可复用的企业消息系统.他遵循Mozilla ...
- <转>牛顿法与拟牛顿法
转自:http://blog.csdn.net/itplus/article/details/21896619 机器学习算法中经常碰到非线性优化问题,如 Sparse Filtering 算法,其主要 ...
- Tomcat中的Listener源码片段解读
@Override public <T extends EventListener> void addListener(T t) { if (!context.getState().equ ...
- 下载Crypto,CyCrypto,PyCryptodome 报错问题
python下载Crypto,CyCrypto,PyCryptodome,如有site-packages中存在crypto.pycrypto,在pip之前,需要pip3 uninstall crypt ...
- Sring 类的例子
public class ZongHe { public static void main(String[] args) { function1(); funct ...