【Spark-core学习之七】 Spark广播变量、累加器
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
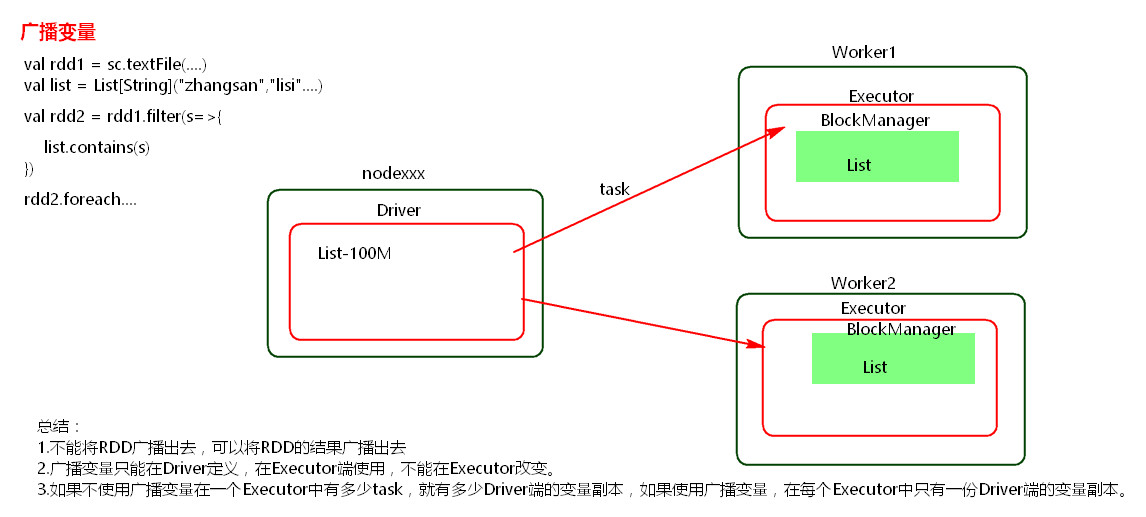
一、广播变量
package com.wjy import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object GuboVal {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("broadcast");
val sc= new SparkContext(conf); val list = List("hello wjy");
val broadcast = sc.broadcast(list);//定义一个广播变量 val linesRDD = sc.textFile("./data/words.txt");
//广播变量可以在excutor使用
linesRDD.filter{x=>broadcast.value.contains(x)}.foreach(println); sc.stop();
}
}
注意:
(1) 能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
(2)广播变量只能在Driver端定义,不能在Executor端定义。
(3) 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
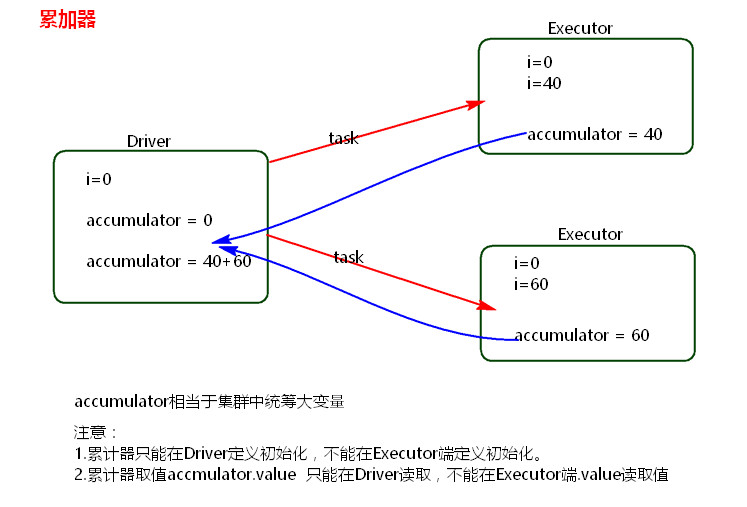
二、累加器
package com.wjy import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object accumulator {
def main(args: Array[String]): Unit = {
val conf =new SparkConf();
conf.setMaster("local").setAppName("accumulator");
val sc = new SparkContext(conf);
//创建累加器 累加器可以是整形 也可以是其他自定义对象
val accumulator = sc.accumulator(0);
//累加器在excutor里累加
sc.textFile("./data/words.txt").foreach(x=>{accumulator.add(1)});
println(accumulator.value); sc.stop();
}
}
注意:
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
参考:
Spark
【Spark-core学习之七】 Spark广播变量、累加器的更多相关文章
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- 【spark core学习---算子总结(java版本) (第1部分)】
map算子 flatMap算子 mapParitions算子 filter算子 mapParttionsWithIndex算子 sample算子 distinct算子 groupByKey算子 red ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- Spark Core源代码分析: Spark任务模型
概述 一个Spark的Job分为多个stage,最后一个stage会包含一个或多个ResultTask,前面的stages会包含一个或多个ShuffleMapTasks. ResultTask运行并将 ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
随机推荐
- shell脚本 切换用户
如下: #!/usr/bin/expect -f spawn su root expect "Password:" send "mypasswd\r" inte ...
- Windows 性能监视器的基本指标说明(CPU,内存,硬盘参数)
[转]Windows 性能监视器的基本指标说明(CPU,内存,硬盘参数) 作为一个系统工程师来说,要看懂监控的数据至关重要,关系着优化和分析出现的问题.我是在运维过程中要用到的.因此,今天给出Wind ...
- 一个第三方Dart库导致的编译错误!
今天学习flutter过程中,突然程序不能运行了,无论是命令行,抑或Android Studio,还是Idea都是出现同样错误,如下: Running .5s Launching lib\main.d ...
- oracle 子查询中null的问题(in 和 not in)
这里的in后面的句子可以理解为or拼接,简单举例即 in (9566,9839,null)可以等价于mgr=9566 or mgr=9839 or mgr=null, not in (9566,983 ...
- python使用requests发送text/xml报文数据
def client_post_xmldata_requests(request_url,requestxmldata): #功能说明:发送请求报文到指定的地址并获取请求响应报文 #输入参数说明:接收 ...
- Android学习:代码控制UI界面示例
package allegro.test2; import android.support.v7.app.AppCompatActivity; import android.os.Bundle; im ...
- Linux下的搜索查找命令的详解(locate)
3.locate locate 让使用者可以很快速的搜寻档案系统内是否有指定的档案.其方法是先建立一个包括系统内所有档案名称及路径的数据库,之后当寻找时就只需查询这个数据库,而不必实际深入档案系统之中 ...
- thinkphp5中使用PHPExcel(转载)
thinkphp5中可以使用composer来获取第三方类库,使用起来特别方便,例如:可是使用composer下载PHPMailer,think-captcha(验证码)等等…… 接下来说一下怎么使用 ...
- 27.用webpack自搭react和vue框架
自己搭建react-app vue-cli 前置条件 cnpm i -D webpack webpack-cli webpack-dev-server cnpm i -D css-loader sty ...
- 18.jwt加密
jwt 官网https://jwt.io/ jwt:json web token jwt-simple: https://www.npmjs.com/package/jwt-simple jsonwe ...