MapReduce业务 - 图片关联计算
1.概述
最近在和人交流时谈到数据相似度和数据共性问题,而刚好在业务层面有类似的需求,今天和大家分享这类问题的解决思路,分享目录如下所示:
- 业务背景
- 编码实践
- 预览截图
下面开始今天的内容分享。
2.业务背景
目前有这样一个背景,在一大堆数据中,里面存放着图片的相关信息,如下图所示:
上图只是给大家列举的一个示例数据格式,第一列表示自身图片,第二、第三......等列表示与第一列相关联的图片信息。那么我们从这堆数据中如何找出他们拥有相同图片信息的图片。
2.1 实现思路
那么,我们在明确了上述需求后,下面我们来分析它的实现思路。首先,我们通过上图所要实现的目标结果,其最终计算结果如下所示:
pic_001pic_002 pic_003,pic_004,pic_005
pic_001pic_003 pic_002,pic_005
pic_001pic_004 pic_002,pic_005
pic_001pic_005 pic_002,pic_003,pic_004
......
结果如上所示,找出两两图片之间的共性图片,结果未列完整,只是列举了部分,具体结果大家可以参考截图预览的相关信息。
下面给大家介绍解决思路,通过观察数据,我们可以发现在上述数据当中,我们要计算图片两两的共性图片,可以从关联图片入手,在关联图片中我们可以找到共性图片的关联信息,比如:我们要计算pic001pic002图片的共性图片,我们可以在关联图片中找到两者(pic001pic002组合)后对应的自身图片(key),最后在将所有的key求并集即为两者的共性图片信息,具体信息如下图所示:
通过上图,我们可以知道具体的实现思路,步骤如下所示:
- 第一步:拆分数据,关联数据两两组合作为Key输出。
- 第二步:将相同Key分组,然后求并集得到计算结果。
这里使用一个MR来完成此项工作,在明白了实现思路后,我们接下来去实现对应的编码。
3.编码实践
- 拆分数据,两两组合。
public static class PictureMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer strToken = new StringTokenizer(value.toString());
Text owner = new Text();
Set<String> set = new TreeSet<String>();
owner.set(strToken.nextToken());
while (strToken.hasMoreTokens()) {
set.add(strToken.nextToken());
}
String[] relations = new String[set.size()];
relations = set.toArray(relations);
for (int i = 0; i < relations.length; i++) {
for (int j = i + 1; j < relations.length; j++) {
String outPutKey = relations[i] + relations[j];
context.write(new Text(outPutKey), owner);
}
}
}
}
- 按Key分组,求并集
public static class PictureReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String common = "";
for (Text val : values) {
if (common == "") {
common = val.toString();
} else {
common = common + "," + val.toString();
}
}
context.write(key, new Text(common));
}
}
- 完整示例
package cn.hadoop.hdfs.example; import java.io.IOException;
import java.util.Set;
import java.util.StringTokenizer;
import java.util.TreeSet; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import cn.hadoop.hdfs.util.HDFSUtils;
import cn.hadoop.hdfs.util.SystemConfig; /**
* @Date Aug 31, 2015
*
* @Author dengjie
*
* @Note Find picture relations
*/
public class PictureRelations extends Configured implements Tool { private static Logger log = LoggerFactory.getLogger(PictureRelations.class);
private static Configuration conf; static {
String tag = SystemConfig.getProperty("dev.tag");
String[] hosts = SystemConfig.getPropertyArray(tag + ".hdfs.host", ",");
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://cluster1");
conf.set("dfs.nameservices", "cluster1");
conf.set("dfs.ha.namenodes.cluster1", "nna,nns");
conf.set("dfs.namenode.rpc-address.cluster1.nna", hosts[0]);
conf.set("dfs.namenode.rpc-address.cluster1.nns", hosts[1]);
conf.set("dfs.client.failover.proxy.provider.cluster1",
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
conf.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());
} public static class PictureMap extends Mapper<LongWritable, Text, Text, Text> { @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer strToken = new StringTokenizer(value.toString());
Text owner = new Text(); Set<String> set = new TreeSet<String>(); owner.set(strToken.nextToken());
while (strToken.hasMoreTokens()) {
set.add(strToken.nextToken());
} String[] relations = new String[set.size()];
relations = set.toArray(relations); for (int i = 0; i < relations.length; i++) {
for (int j = i + 1; j < relations.length; j++) {
String outPutKey = relations[i] + relations[j];
context.write(new Text(outPutKey), owner);
} }
}
} public static class PictureReduce extends Reducer<Text, Text, Text, Text> { @Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String common = "";
for (Text val : values) {
if (common == "") {
common = val.toString();
} else {
common = common + "," + val.toString();
}
}
context.write(key, new Text(common));
}
} public int run(String[] args) throws Exception {
final Job job = Job.getInstance(conf);
job.setJarByClass(PictureMap.class);
job.setMapperClass(PictureMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(PictureReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, args[0]);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
int status = job.waitForCompletion(true) ? 0 : 1;
return status;
} public static void main(String[] args) {
try {
if (args.length != 1) {
log.warn("args length must be 1 and as date param");
return;
}
String tmpIn = SystemConfig.getProperty("hdfs.input.path.v2");
String tmpOut = SystemConfig.getProperty("hdfs.output.path.v2");
String inPath = String.format(tmpIn, "t_pic_20150801.log");
String outPath = String.format(tmpOut, "meta/" + args[0]); // bak dfs file to old
HDFSUtils.bak(tmpOut, outPath, "meta/" + args[0] + "-old", conf); args = new String[] { inPath, outPath };
int res = ToolRunner.run(new Configuration(), new PictureRelations(), args);
System.exit(res);
} catch (Exception ex) {
ex.printStackTrace();
log.error("Picture relations task has error,msg is" + ex.getMessage());
} } }
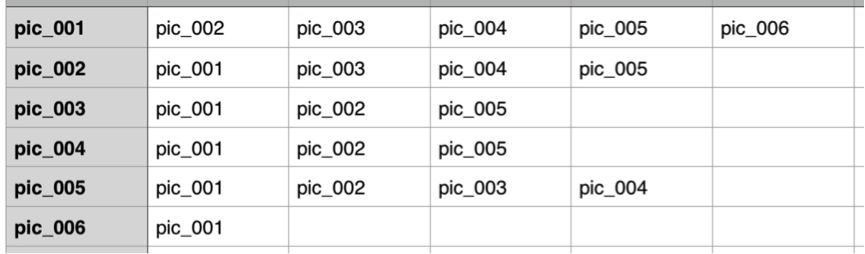
4.截图预览
关于计算结果,如下图所示:

5.总结
本篇博客只是从思路上实现了图片关联计算,在数据量大的情况下,是有待优化的,这里就不多做赘述了,后续有时间在为大家分析其中的细节。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
MapReduce业务 - 图片关联计算的更多相关文章
- linq查询数值为null的问题以及数据表的关联计算问题
说明:下面实例都是我进行项目开发时的真实部分代码,毫无保留 一.数据表的关联计算 //把当前年度的分差计算出来,建立两个关联的数据表 try { using(TransactionScope scop ...
- 【MapReduce】经常使用计算模型具体解释
前一阵子參加炼数成金的MapReduce培训,培训中的作业样例比較有代表性,用于解释问题再好只是了. 有一本国外的有关MR的教材,比較有用.点此下载. 一.MapReduce应用场景 MR能解决什么问 ...
- ios 拉伸图片和计算文字的大小
一.拉伸图片 /** * 传入图片的名称,返回一张可拉伸不变形的图片 * * @param imageName 图片名称 * * @return 可拉伸图片 */ + (UIImage *)resiz ...
- MapReduce单表关联学习~
首先考虑表的自连接,其次是列的设置,最后是结果的整理. 文件内容: import org.apache.hadoop.conf.Configuration; import org.apache.had ...
- opencv 霍夫变换 实现图片旋转角度计算
在OCR实际开发中,证件照采集角度有很大的偏差,需要将图片进行旋转校正, 效果图: 在应用中发现应该加入高斯模糊,可以极大减少误差线条. 知道线条后 通过求斜率 得旋转角度 .(x1-x2)/(y1- ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- 大数据计算的基石——MapReduce
MapReduce Google File System提供了大数据存储的方案,这也为后来HDFS提供了理论依据,但是在大数据存储之上的大数据计算则不得不提到MapReduce. 虽然现在通过框架的不 ...
- 【MySQL】pt-query-digest数据处理并关联业务
参考:www.percona.com/doc/percona-toolkit/2.1/pt-query-digest.htm 通过pt-query-digest将慢日志导入数据库后在表global_q ...
- Caffe学习系列(15):计算图片数据的均值
图片减去均值后,再进行训练和测试,会提高速度和精度.因此,一般在各种模型中都会有这个操作. 那么这个均值怎么来的呢,实际上就是计算所有训练样本的平均值,计算出来后,保存为一个均值文件,在以后的测试中, ...
随机推荐
- 33.MySQL高可用架构
33.高可用架构33.1 MMM架构MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序(Perl).主要用来 ...
- 目录命令(cd)
cd 命令: // 描述: (Change Directory) 更改当前目录或显示当前目录的名称. 如果仅使用驱动器号(例如,cd C :),则cd将显示指定驱动器中当前目录的名称. 如果不带参数使 ...
- J2CACHE 两级缓存框架
概述 缓存框架我们有ehcache 和 redis 分别是 本地内存缓存和 分布式缓存框架.在实际情况下如果单台机器 使用ehcache 就可以满足需求了,速度快效率高,有些数据如果需要多台机器共享这 ...
- vue报错TypeError: Cannot read property '$createElement' of undefined
报错截图: 这个错误就是路由上的component写成了components
- 简单好用的时间选择插件My97datepicker
我们经常会需要验证字符串的格式,比如密码长度范围.电子邮件格式.固定电话号码和手机号码格式等,这个时候我们经常会需要用到正则表达式.但是正则表达式用起来性能会低一点,所以在需要验证的时候能不使用正则表 ...
- .NET Core微服务之路:让我们对上一个Demo通讯进行修改,完成RPC通讯
最近一段时间有些事情耽搁了更新,抱歉各位了. 上一篇我们简单的介绍了DotNetty通信框架,并简单的介绍了基于DotNetty实现了回路(Echo)通信过程. 我们来回忆一下上一个项目的整个流程: ...
- MySQL--CREATE INDEX在各版本的优化
在MySQL 5.5版本中引入FIC(Fast index creation)特性,提升索引的创建速度. FCI 操作流程: (1)对表加共享S锁,允许其他会话读操作,但禁止写操作, (2)扫描Clu ...
- Unity全面的面试题(包含答案)
一:什么是协同程序? 在主线程运行的同时开启另一段逻辑处理,来协助当前程序的执行,协程很像多线程,但是不是多线程,Unity的协程实在每帧结束之后去检测yield的条件是否满足. 二:Unity3D中 ...
- 枚举类型enum详解——C语言
enum enum是C语言中的一个关键字,enum叫枚举数据类型,枚举数据类型描述的是一组整型值的集合(这句话其实不太妥当),枚举型是预处理指令#define的替代,枚举和宏其实非常类似,宏在预处理阶 ...
- Java中的代理机制
Java的三种代理模式 代理模式是一种设计模式,提供了对目标对象额外的访问方式,即通过代理对象访问目标对象,这样可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能. 简言之,代理模 ...