极小极大搜索方法、负值最大算法和Alpha-Beta搜索方法
1. 极小极大搜索方法
一般应用在博弈搜索中,比如:围棋,五子棋,象棋等。结果有三种可能:胜利、失败和平局。暴力搜索,如果想通过暴力搜索,把最终的结果得到的话,搜索树的深度太大了,机器不能满足,一般都是规定一个搜索的深度,在这个深度范围内进行深度优先搜索。
假设:A和B对弈,轮到A走棋了,那么我们会遍历A的每一个可能走棋方法,然后对于前面A的每一个走棋方法,遍历B的每一个走棋方法,然后接着遍历A的每一个走棋方法,如此下去,直到得到确定的结果或者达到了搜索深度的限制。当达到了搜索深度限制,此时无法判断结局如何,一般都是根据当前局面的形式,给出一个得分,计算得分的方法被称为评价函数,不同游戏的评价函数差别很大,需要很好的设计。
在搜索树中,表示A走棋的节点即为极大节点,表示B走棋的节点为极小节点。
如下图:A为极大节点,B为极小节点。称A为极大节点,是因为A会选择局面评分最大的一个走棋方法,称B为极小节点,是因为B会选择局面评分最小的一个走棋方法,这里的局面评分都是相对于A来说的。这样做就是假设A和B都会选择在有限的搜索深度内,得到的最好的走棋方法。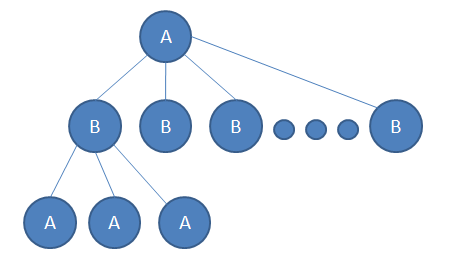
图-极大节点(A)与极小节点(B)
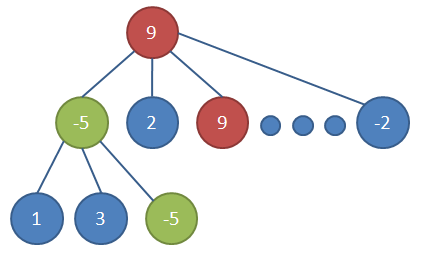
图-极大极小搜索
伪代码如下(来自维基百科):
function minimax(node, depth) // 指定当前节点和搜索深度
// 如果能得到确定的结果或者深度为零,使用评估函数返回局面得分
if node is a terminal node or depth =
return the heuristic value of node
// 如果轮到对手走棋,是极小节点,选择一个得分最小的走法
if the adversary is to play at node
let α := +∞
foreach child of node
α := min(α, minimax(child, depth-))
// 如果轮到我们走棋,是极大节点,选择一个得分最大的走法
else {we are to play at node}
let α := -∞
foreach child of node
α := max(α, minimax(child, depth-))
return α;
更加具体一些的算法:
int MinMax(int depth) { // 函数的评估都是以白方的角度来评估的
if (SideToMove() == WHITE) { // 白方是“最大”者
return Max(depth);
} else { // 黑方是“最小”者
return Min(depth);
}
}
int Max(int depth) {
int best = -INFINITY;
if (depth <= ) {
return Evaluate();
}
GenerateLegalMoves();
while (MovesLeft()) {
MakeNextMove();
val = Min(depth - );
UnmakeMove();
if (val > best) {
best = val;
}
}
return best;
}
int Min(int depth) {
int best = INFINITY; // 注意这里不同于“最大”算法
if (depth <= ) {
return Evaluate();
}
GenerateLegalMoves();
while (MovesLeft()) {
MakeNextMove();
val = Max(depth - );
UnmakeMove();
if (val < best) { // 注意这里不同于“最大”算法
best = val;
}
}
return best;
}
上面这段代码与前面的伪代码的思路都是一样的,只不过把最大算法和最小算法分为了两个函数。
2. 负值最大算法
前面的两段代码都是分别用两部分代码处理了极大节点和极小节点两种情况,其实,可以只用一部分代码,既处理极大节点也处理极小节点。
不同的是,前面的评估函数是针对白方即,指定的一方来给出分数的,这里的评估函数是根据当前搜索节点来给出分数的。每个人都会选取最大的分数,然后,返回到上一层节点时,会给出分数的相反数。
int NegaMax(int depth) {
int best = -INFINITY;
if (depth <= ) {
return Evaluate();
}
GenerateLegalMoves();
while (MovesLeft()) {
MakeNextMove();
val = -NegaMax(depth - ); // 注意这里有个负号
UnmakeMove();
if (val > best) { // 都是选择最大的分数,因为评估分数的对象变化了
best = val;
}
}
return best;
}
这个负值最大算法,主要是代码量上的减少,时间与空间上的效率没有什么提升。
3. Alpha-Beta搜索方法
举例来说,考虑下面的例子:
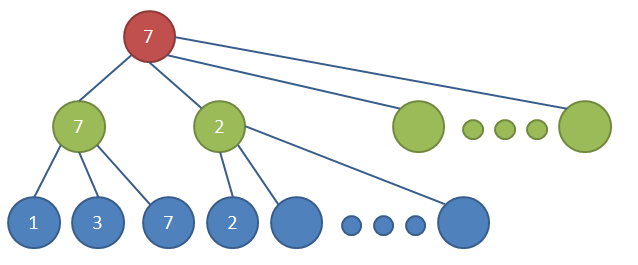
图-alpha-beta搜索
极小极大搜索是一个深度搜索,当搜索到第二层的第二个绿色的节点时,已知其第一个子节点返回值为2,因为这是一个极小节点,那么这个节点得到的值肯定是小于2的,而第二层的第一个绿色节点的值为7,因此这个节点后面即使都搜索了,也不会超过2,更不会超过7,因此这个节点后面的节点可以忽略,即图中第三册没有数字的节点。这属于Alpha剪枝,可能是剪掉的节点是极大节点的原因吧。相应的也有Beta剪枝,图中忽略了。
下面的维基百科伪代码,其中两个值,α表示搜索到的最好的值,β表示搜索到的最坏的值。
function alphabeta(node, depth, α, β, Player)
if depth = or node is a terminal node
return the heuristic value of node
if Player = MaxPlayer // 极大节点
for each child of node // 极小节点
α := max(α, alphabeta(child, depth-, α, β, not(Player) ))
if β ≤ α // 该极大节点的值>=α>=β,该极大节点后面的搜索到的值肯定会大于β,因此不会被其上层的极小节点所选用了。对于根节点,β为正无穷
break (* Beta cut-off *)
return α
else // 极小节点
for each child of node // 极大节点
β := min(β, alphabeta(child, depth-, α, β, not(Player) )) // 极小节点
if β ≤ α // 该极大节点的值<=β<=α,该极小节点后面的搜索到的值肯定会小于α,因此不会被其上层的极大节点所选用了。对于根节点,α为负无穷
break (* Alpha cut-off *)
return β
(* Initial call *)
alphabeta(origin, depth, -infinity, +infinity, MaxPlayer)
4. 参考资料
维基百科-极小化极大算法
最小-最大搜索 http://www.xqbase.com/computer/search_minimax.htm
Alpha-Beta搜索 http://www.xqbase.com/computer/search_alphabeta.htm
原文地址:http://www.cnblogs.com/pangxiaodong/archive/2011/05/26/2058864.html
极小极大搜索方法、负值最大算法和Alpha-Beta搜索方法的更多相关文章
- 转:极小极大搜索方法、负值最大算法和Alpha-Beta搜索方法
转自:极小极大搜索方法.负值最大算法和Alpha-Beta搜索方法 1. 极小极大搜索方法 一般应用在博弈搜索中,比如:围棋,五子棋,象棋等.结果有三种可能:胜利.失败和平局.暴力搜索,如果想通 ...
- IRT模型的参数估计方法(EM算法和MCMC算法)
1.IRT模型概述 IRT(item response theory 项目反映理论)模型.IRT模型用来描述被试者能力和项目特性之间的关系.在现实生活中,由于被试者的能力不能通过可观测的数据进行描述, ...
- 最小生成树的两种方法(Kruskal算法和Prim算法)
关于图的几个概念定义: 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图. 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连 ...
- 最短路径——Dijkstra算法和Floyd算法
Dijkstra算法概述 Dijkstra算法是由荷兰计算机科学家狄克斯特拉(Dijkstra)于1959 年提出的,因此又叫狄克斯特拉算法.是从一个顶点到其余各顶点的最短路径算法,解决的是有向图(无 ...
- 最小生成树---Prim算法和Kruskal算法
Prim算法 1.概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (gra ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- MP算法和OMP算法及其思想
主要介绍MP(Matching Pursuits)算法和OMP(Orthogonal Matching Pursuit)算法[1],这两个算法尽管在90年代初就提出来了,但作为经典的算法,国内文献(可 ...
- BM算法和Sunday快速字符串匹配算法
BM算法研究了很久了,说实话BM算法的资料还是比较少的,之前找了个资料看了,还是觉得有点生涩难懂,找了篇更好的和算法更好的,总算是把BM算法搞懂了. 1977年,Robert S.Boyer和J St ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
随机推荐
- ubuntu 命令安装软件
终端安装(命令安装).第一,找到终端或者按住Ctrl+Alt+t 打开终端;第二输入命令,命令如下:cd /xxx/xxx/,(xxx代表软件包路径,一直到你放置软件包的文件夹),之后输入命令:sud ...
- Java常见的乱码解决方式
JAVA几种常见的编码格式(转) 简介 编码问题一直困扰着开发人员,尤其在 Java 中更加明显,因为 Java 是跨平台语言,不同平台之间编码之间的切换较多.本文将向你详细介绍 Java 中编码 ...
- lucene教程--全文检索技术
1 Lucene 示例代码 https://blog.csdn.net/qzqanzc/article/details/80916430 2 Lucene 实例教程(一)初识L ...
- sqlserver列重命名
EXEC sp_rename 'tablename.[OldFieldName ]', 'NewFieldName', 'COLUMN'
- java.lang.AbstractMethodError: com.microsoft.jdbc.base.BaseDatabaseMetaData.supportsGetGeneratedKeys()Z
解决:问谷老师得知是microsoft提供的数据库驱动存在bug.需要换一种驱动连接,使用jtds(下载地址:http://sourceforge.net/projects/jtds/files/)下 ...
- 迷你MVVM框架 avalonjs 1.3.6发布
本版本是一次重要的升级,考虑要介绍许多东西,也有许多东西对大家有用,也发到首页上来了. 本来是没有1.36的,先把基于静态收集依赖的1.4设计出来后,发现改动太多,为了平缓升级起见,才减少了一部分新特 ...
- DELPHI WM_CopyData 用法
unit Unit1; interface usesWindows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, ...
- LPSN获取菌python脚本
本文转载于https://mp.weixin.qq.com/s?__biz=MzIxNzEzODA5NQ==&mid=2649373408&idx=1&sn=232c2cb36 ...
- 【校招面试 之 C/C++】第7题 C++构造函数不能是虚函数的原因
1.虚拟函数调用只需要“部分的”信息,即只需要知道函数接口,而不需要对象的具体类型.但是构建一个对象,却必须知道具体的类型信息.如果你调用一个虚拟构造函数,编译器怎么知道你想构建是继承树上的哪种类型呢 ...
- 使用Ansible部署etcd 3.2高可用集群
之前写过一篇手动搭建etcd 3.1集群的文章<etcd 3.1 高可用集群搭建>,最近要初始化一套新的环境,考虑用ansible自动化部署整套环境, 先从部署etcd 3.2集群开始. ...