Service Fabric基本概念:Partition/Replicas示例
作者:张鼎松 (Dingsong Zhang) @ Microsoft
在上一节的结尾简单介绍了Service Fabric中分区Partitions和复制replicas的概念,本节主要以示例的形式来具体说明这个抽象概念在Service Fabric中的工作方式。
1. 分区Partitions和复制replicas
一个service可以包含多个分区Partition,Service Fabric通过使用分区作为扩展的机制来将工作分布到不同的service实例上。
一个分区Partition可以包含一个或者多个复制replicas。Service Fabric通过使用复制来实现可用性。一个分区可以有一个主复制和多个从复制,多个复制之间的状态可以自动同步。当主复制出现错误时,其中一个从复制被自动提升为主复制,以保证系统的可用性。然后将从复制的个数恢复到正常水平,保证足够的从复制冗余。
(Note: 下文中出现的所有Instance 跟Replica是同一个意思)
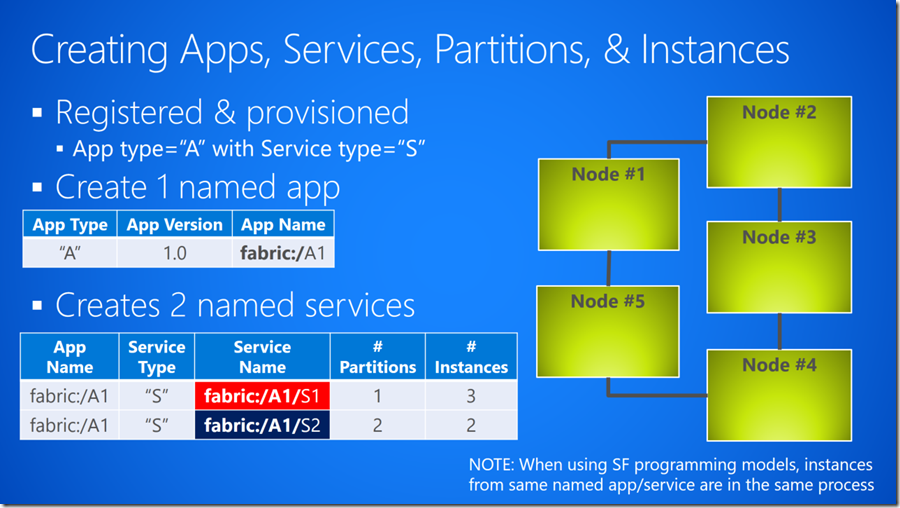
如下图示例,我们假设一个有一个Cluster中有5个Node, 现在我们要在Cluster上部署一个Application, 这个Application包含两个Service。 Application Type为“A”,Service Type为“S”。
首先我们要创建一个Named Application, 按照上一节提到的Application的命名规范,我们将这个Named Application叫做“faric:/A1”。依次再创建两个“S” type的Named Service,并将它们命名为“fabric:/A1/S1”和“fabric:/A1/S2”。
2. 创建Named Application
对于创建的这个Named Application “faric:/A1”, Service Fabric提供三种方式对其进行管理:
- REST API: 可以使用REST API 通过HTTP 协议和 port 19080进行管理
- PowerShell commands: PS Cmdlet 使用的是 TCP 协议和 port 19000进行管理
- Fabric Client: 还可以使用 C#/VB的.Net 类库Fabric Client, 其实内部使用的仍然是 TCP on port 19000的方式
3. 创建Named Service
我们希望S1有一个分区,三个Instance. S2有2个分区,2个Instance.

我们看到Named Service fabric:/A1/S1,按照要求我们希望设置 Partition count为 1, Instances count 为 3。 1个Partition乘以3个 Instances等于3。 (1x3=3). 所以Service Fabric会选择Cluster中的3个Node来存放这个Named Service. 我们不需要去控制这个过程,Service Fabric会帮我们完成这个操作。
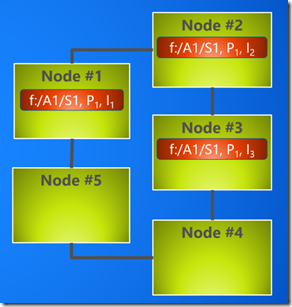
现在,S1在Cluster中的分布如下图:
Service fabric选择了 Node #1 #2 和 #3 给
Partition 1, Instance 1: fabric:/A1/S1, P1, I1
Partition 1, Instance 2: fabric:/A1/S1, P1, I2
Partition 1, Instance 3: fabric:/A1/S1, P1, I3
同一Partition的不同instance要分布在不同的Node上。
就是说Instance1 和Instance2永远不可能在同一个Node上,这样设计的原因是高可用性:当任何一个Node突然出现故障不能工作时,其他Node能够正常提供服务。 但是如果两个或两个以上的Instance在同一个Node上时,这个Node出现故障,您将会失去这个Node上的所有数据。
Service Fabric 被设计成可以将 instance分散发布在不同的Nodes上,以保证可以给用户高可用性的体验。
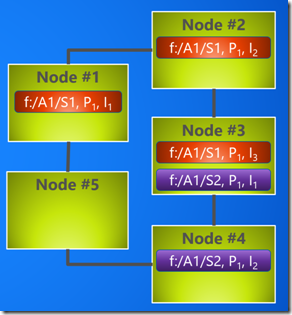
我们继续创建另一个Named Service: “fabric:/A1/S2”, Partitions count为2, Instances/Replicas count为2。 (2x2=4)
Partition 1, Instance 1: fabric:/A1/S2, P1, I1
Partition 1, Instance 2: fabric:/A1/S2, P1, I2
Partition 2, Instance 1: fabric:/A1/S2, P2, I1
Partition 2, Instance 2: fabric:/A1/S2, P2, I2
Service Fabric 会首先将Partition1 Instance1部署在 Node3上, 然后再将 Partition1 Instance2 放置在Node4上。
(Service Fabric 可以确保不同的 instances/replicas被放置部署在不同的 Nodes上)
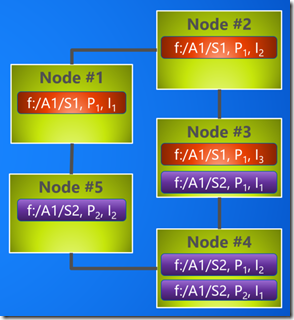
然后继续将 Partition2 Instance2 放置在Node5, Partition2 Instance1 放置在 Node4.
你会注意到 Partition1 Instance2 和 Partition2 Instance1 都在同一个 Node4上。这样是没有问题的,因为当 Node4出现故障时, 我们在Cluster中仍然拥有 Partition1 的一个Instance1和 Partition2的 Instance2。
Node4 is a single point of failure but for two instances of different Partitions, 我们永远不会让一个Partition的两个Instance出现在同一个Node上。
到此为止,Service Fabric就完成了S1 和S2的部署。
Service Fabric基本概念:Partition/Replicas示例的更多相关文章
- Service Fabric基本概念: Node, Application, Service, Partition/Replicas
作者:张鼎松 (Dingsong Zhang) @ Microsoft 在上一节中,为大家简明扼要的介绍了微软针对现代分布式系统在Azure上实现的相关服务组件.紧接上文内容,本节将为大家介绍Azur ...
- 拥抱Service Fabric —— 目录
理解分布式 经典分布式系统设计 云时代分布式系统演进 Service Fabric基础概念 Node, Application, Service, Partition/Replicas Partiti ...
- 微服务框架之微软Service Fabric
常见的微服务架构用到的软件&组件: docker(成熟应用) spring boot % spring cloud(技术趋势) Service Fabric(属于后起之秀 背后是微软云的驱动) ...
- 转:微服务框架之微软Service Fabric
常见的微服务架构用到的软件&组件: docker(成熟应用) spring boot % spring cloud(技术趋势) Service Fabric(属于后起之秀 背后是微软云的驱动) ...
- Service Fabric —— Stateful Service 概念
作者:潘罡 (Van Pan) @ Microsoft 上节中我们谈到了Service Fabric最底层的两个概念,一个是针对硬件层面而言的Node Type和Node.另一个是Applicatio ...
- Service Fabric —— Actor / Stateless Service 概念
作者:潘罡 (Van Pan) @ Microsoft 上一节我们谈到了Stateful Service.在Service Fabric中,Stateful Service是理解Micro Servi ...
- service fabric docker 安装
1. 镜像拉取 docker pull microsoft/service-fabric-onebox 2. 配置docker(daemon.json) { "ipv6": tru ...
- 【Azure微服务 Service Fabric 】使用az命令创建Service Fabric集群
问题描述 在使用Service Fabric的快速入门文档: 将 Windows 容器部署到 Service Fabric. 其中在创建Service Fabric时候,示例代码中使用的是PowerS ...
- How to deploy JAVA Application on Azure Service Fabric
At this moment, Azure Service Fabric does not support JAVA application natively (but it's on the sup ...
随机推荐
- LeetCode 455. Assign Cookies (C++)
题目: Assume you are an awesome parent and want to give your children some cookies. But, you should gi ...
- teamwork 2
1.访问上学期项目团队,学习他们的得失. 上学期学长们有一个项目是学霸系统,在看过了学长们的相关博客后,我们可以感受到学长们确实花费了不少心思,也看到了许多值得我们学习的地方. 首先,学长们在项目开始 ...
- 个人作业-Week 1
1)快速看完整部教材,列出你仍然不懂的5到10个问题,发布在你的个人博客上. Q1:"Scrum Master不是一个官,而是一个没有行政权力的沟通者,就像微软的PM那样.他/她同时还要在团 ...
- 20172321『Java程序设计』课程 结对编程练习_四则运算第二周阶段总结
20172321『Java程序设计』课程 结对编程练习_四则运算第二周阶段总结 结对伙伴 学号 :20172324 姓名 :曾程 伙伴第一周博客地址: 对结对伙伴的评价:一个很优秀的同学,在这次项目中 ...
- Bag类课后作业
20162316 Bag课后作业 下面小标题都是码云链接 实现代码 import java.util.Arrays; public class Bag implements BagInterface ...
- 四则运算2及PSP0设计项目计划
时间比较紧,我简单写写我的设计思路: 题目在四则运算1的基础上控制产生题目的数量,这个可以用变量控制:打印方式也可选用变量控制,程序的关键是括号的生成.我们可以将整个四则运算式看成()+()的模型,然 ...
- 我的寒假C(C++)学习计划
前言 要补缺加强C语言的想法由来已久,上学期因为种种原因,某些知识点学习得不是很理想,而且,许多地方也有加强的必要,所以这次布置的随笔可谓是来得恰到好处. 学习材料 C Primer Plus 师爷的 ...
- roject ..\appcompat_v7 is missing. Needed by eclipse 转AS项目时遇到的问题
参考的 http://www.cnblogs.com/vanezkw/p/4182917.html 去转换项目, 在第一步的时候就遇到问题 ,提示 missing 而那个又是兼容包 解决方法:项目右键 ...
- Git初用心得
第一次使用git,因为之前操作系统的实验需要,在虚拟机中使用过lniux系统,所以对这种用指令输入而不是图形化的程序感觉不是很陌生.感觉git还是很人性化的,git gui就是图形界面,操作起来也不复 ...
- 【CSAPP笔记】4. 汇编语言——基础知识
程序的机器级表示 计算机能读懂是机器代码(machine code)-- 用字节序列编码的低级操作 -- 也就是0和1.编译器基于编程语言的规则.目标机器的指令集和操作系统的规则,经过一系列阶段产生机 ...