keras 修仙笔记二(ResNet算法例子)
对于牛逼的程序员,人家都喜欢叫他大神;因为大神很牛逼,人家需要一个小时完成的技术问题,他就20分钟就搞定。Keras框架是一个高度集成的框架,学好它,就犹如掌握一个法宝,可以呼风唤雨。所以学keras 犹如在修仙,呵呵。请原谅我无厘头的逻辑。
ResNet
关于ResNet算法,在归纳卷积算法中有提到了,可以去看看。
1, ResNet 要解决的问题
ResNet要解决的问题是在求损失函数最小值时,梯度下降太快了,无法捕捉到最优解。
解决的方法是在求激活函数值 A值的时候
a^[l+1] =g(z^[l+1] +?)
〖?可以是a〗^([l-1]) 也可以是a^([l])等等
这样就能避免梯度下降过快
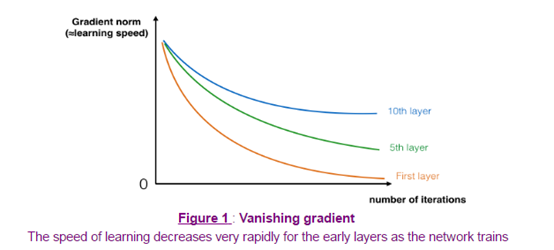
以上图是不同层数的模型的下降曲线
2, 构建自己的ResNet模型
在resnet网络中,identity block的跳跃可能有1个或者2(conv2D+batchnorm+Relu)个,下面是两个可选图:
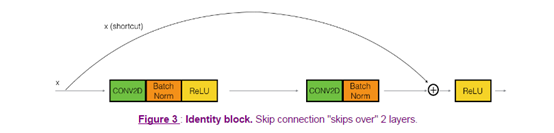
或者:
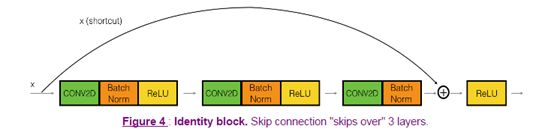
import numpy as np
import tensorflow as tf
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from resnets_utils import *
from keras.initializers import glorot_uniform
import scipy.misc
from matplotlib.pyplot import imshow
%matplotlib inline import keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
红色字体是重点关注的函数,很多在上节就已经说明,这里是BatchNormalization函数是为了规范化通道参数的,都必须给予命名:bn_name_base+’2?’
Activation 函数就不用命名了 2.1 创建标识块 identify block
def identity_block(X, f, filters, stage, block):
"""
##参数说明
## X:输入的维度 (m, n_H_prev, n_W_prev, n_C_prev)
## f:整数,中间conv2D的维度
##filters 过滤核的维度
## block 用于命名网络中的层
###返回值: 维度为(n_H, n_W, n_C) ###返回值: 维度为(n_H, n_W, n_C)
""" ##定义偏差
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch' ##过滤核
F1, F2, F3 = filters ##保存输入的值
X_shortcut = X # #第一层卷积
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X) ### START CODE HERE ### # Second component of main path (≈3 lines)
X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X) # Third component of main path (≈2 lines)
X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name = bn_name_base + '2c')(X) ###添加shortcut操作的激化
X = layers.add([X, X_shortcut])
X = Activation('relu')(X) ### END CODE HERE ### return X
小测:
tf.reset_default_graph() with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = identity_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
结果:
out[ 0.94822985 0. 1.16101444 2.747859 0. 1.36677003]
2.2 卷积块 convolutional_block
卷积块主要是为了适配=g(+?)例子中?的维度跟的维度不匹配的现象,具体是在shortcut增加一个卷积,使其维度能都适配,而且是没有经过activation激活过的,如图:
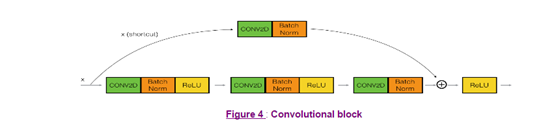
这样就可以通过卷积核的维度达到我们想到的维度减少非线性的函数操作。
def convolutional_block(X, f, filters, stage, block, s = 2):
"""
参数跟identity_block是一样的,就多了一个
s=2 表示卷积的步长
""" # defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch' # Retrieve Filters
F1, F2, F3 = filters # Save the input value
X_shortcut = X ##### MAIN PATH #####
# First component of main path
X = Conv2D(F1, (1, 1), strides = (s,s), name = conv_name_base + '2a', padding='valid', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X) ### START CODE HERE ### # Second component of main path (≈3 lines)
X = Conv2D(F2, (f, f), strides = (1, 1), name = conv_name_base + '2b',padding='same', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X) # Third component of main path (≈2 lines)
X = Conv2D(F3, (1, 1), strides = (1, 1), name = conv_name_base + '2c',padding='valid', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X) ##### SHORTCUT PATH #### (≈2 lines)
X_shortcut = Conv2D(F3, (1, 1), strides = (s, s), name = conv_name_base + '',padding='valid', kernel_initializer = glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis = 3, name = bn_name_base + '')(X_shortcut) # Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)
X = layers.add([X, X_shortcut])
X = Activation('relu')(X) ### END CODE HERE ### return X
小测:
tf.reset_defalut_graph() with tf.Session() as test:
np.random.seed(1)
A_prev=tf.placeholder(“float”,[3,4,4,6])
X=np.random.randn(3,4,4,6)
A=convolutional_block(A_prev,f=2,filters=[2,4,6],stage=1,block=’a’)
test.run(tf.global_variable_initializer())
out.test.run([A],feed_dict={A_prev:X,K.learning_phase():0})
print(“out=”+str(out[0][1][1][0]))
结果:
结果: out = [ 0.09018463 1.23489773 0.46822017 0.0367176 0. 0.65516603]
2.3 构建完整的例子
接下来我们根据
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER构建一个完整的resnet网络

def ResNet50(input_shape = (64, 64, 3), classes = 6):
"""
Implementation of the popular ResNet50 the following architecture:
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER Arguments:
input_shape -- shape of the images of the dataset
classes -- integer, number of classes Returns:
model -- a Model() instance in Keras
""" # Define the input as a tensor with shape input_shape
X_input = Input(input_shape) # Zero-Padding
X = ZeroPadding2D((3, 3))(X_input) # Stage 1
X = Conv2D(64, (7, 7), strides = (2, 2), name = 'conv1', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = 'bn_conv1')(X)
X = Activation('relu')(X)
X = MaxPooling2D((3, 3), strides=(2, 2))(X) # Stage 2
X = convolutional_block(X, f = 3, filters = [64, 64, 256], stage = 2, block='a', s = 1)
X = identity_block(X, 3, [64, 64, 256], stage=2, block='b')
X = identity_block(X, 3, [64, 64, 256], stage=2, block='c') ### START CODE HERE ### # Stage 3 (≈4 lines)
# The convolutional block uses three set of filters of size [128,128,512], "f" is 3, "s" is 2 and the block is "a".
# The 3 identity blocks use three set of filters of size [128,128,512], "f" is 3 and the blocks are "b", "c" and "d".
X = convolutional_block(X, f = 3, filters=[128,128,512], stage = 3, block='a', s = 2)
X = identity_block(X, f = 3, filters=[128,128,512], stage= 3, block='b')
X = identity_block(X, f = 3, filters=[128,128,512], stage= 3, block='c')
X = identity_block(X, f = 3, filters=[128,128,512], stage= 3, block='d') # Stage 4 (≈6 lines)
# The convolutional block uses three set of filters of size [256, 256, 1024], "f" is 3, "s" is 2 and the block is "a".
# The 5 identity blocks use three set of filters of size [256, 256, 1024], "f" is 3 and the blocks are "b", "c", "d", "e" and "f".
X = convolutional_block(X, f = 3, filters=[256, 256, 1024], block='a', stage=4, s = 2)
X = identity_block(X, f = 3, filters=[256, 256, 1024], block='b', stage=4)
X = identity_block(X, f = 3, filters=[256, 256, 1024], block='c', stage=4)
X = identity_block(X, f = 3, filters=[256, 256, 1024], block='d', stage=4)
X = identity_block(X, f = 3, filters=[256, 256, 1024], block='e', stage=4)
X = identity_block(X, f = 3, filters=[256, 256, 1024], block='f', stage=4) # Stage 5 (≈3 lines)
# The convolutional block uses three set of filters of size [512, 512, 2048], "f" is 3, "s" is 2 and the block is "a".
# The 2 identity blocks use three set of filters of size [256, 256, 2048], "f" is 3 and the blocks are "b" and "c".
X = convolutional_block(X, f = 3, filters=[512, 512, 2048], stage=5, block='a', s = 2) # filters should be [256, 256, 2048], but it fail to be graded. Use [512, 512, 2048] to pass the grading
X = identity_block(X, f = 3, filters=[256, 256, 2048], stage=5, block='b')
X = identity_block(X, f = 3, filters=[256, 256, 2048], stage=5, block='c') # AVGPOOL (≈1 line). Use "X = AveragePooling2D(...)(X)"
# The 2D Average Pooling uses a window of shape (2,2) and its name is "avg_pool".平均值池化
X = AveragePooling2D(pool_size=(2,2))(X) ### END CODE HERE ### # output layer
X = Flatten()(X)
X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X) # Create model
model = Model(inputs = X_input, outputs = X, name='ResNet50') return model
2.4 执行模型
1)加载模型
model = ResNet50(input_shape = (64, 64, 3), classes = 6)
2)编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
3)加载数据,训练模型
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset() # Normalize image vectors
X_train = X_train_orig/255.
X_test = X_test_orig/255. # Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
model.fit(X_train, Y_train, epochs = 20, batch_size = 32)
4)测试模型
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
输出结果:
120/120 [==============================] - 9s 72ms/step
Loss = 0.729047638178
Test Accuracy = 0.891666666667
=========================================================
总结:这个例子到底位置,训练结果可能不是很满意,可以进一步加大测试集或者加大网络来达到优化的。
参考
中文keras手册:http://keras-cn.readthedocs.io/en/latest/layers/core_layer/
吴恩达网易课堂教程
keras 修仙笔记二(ResNet算法例子)的更多相关文章
- [Java 泥水匠] Java Components 之二:算法篇之项目实践中的位运算符(有你不懂的哦)
作者:泥沙砖瓦浆木匠网站:http://blog.csdn.net/jeffli1993个人签名:打算起手不凡写出鸿篇巨作的人,往往坚持不了完成第一章节. 交流QQ群:[编程之美 365234583] ...
- python基础(9)--递归、二叉算法、多维数组、正则表达式
1.递归 在函数内部,可以调其他函数,如果一个函数在内部调用它本身,这个函数就是递归函数.递归算法对解决一大类问题是十分有效的,它往往使算法的描述简洁而且易于裂解 递归算法解决问题的特点: 1)递归是 ...
- 二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC
评价指标是针对同样的数据,输入不同的算法,或者输入相同的算法但参数不同而给出这个算法或者参数好坏的定量指标. 以下为了方便讲解,都以二分类问题为前提进行介绍,其实多分类问题下这些概念都可以得到推广. ...
- hihocoder#1098 : 最小生成树二·Kruscal算法
#1098 : 最小生成树二·Kruscal算法 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 随着小Hi拥有城市数目的增加,在之间所使用的Prim算法已经无法继续使用 ...
- Hihocoder #1098 : 最小生成树二·Kruskal算法 ( *【模板】 )
#1098 : 最小生成树二·Kruscal算法 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 随着小Hi拥有城市数目的增加,在之间所使用的Prim算法已经无法继续使用 ...
- 垃圾回收GC:.Net自己主动内存管理 上(二)内存算法
垃圾回收GC:.Net自己主动内存管理 上(二)内存算法 垃圾回收GC:.Net自己主动内存管理 上(一)内存分配 垃圾回收GC:.Net自己主动内存管理 上(二)内存算法 垃圾回收GC:.Net自己 ...
- 分布式共识算法 (二) Paxos算法
系列目录 分布式共识算法 (一) 背景 分布式共识算法 (二) Paxos算法 分布式共识算法 (三) Raft算法 分布式共识算法 (四) BTF算法 一.背景 1.1 命名 Paxos,最早是Le ...
- 【笔记】二分类算法解决多分类问题之OvO与OvR
OvO与OvR 前文书道,逻辑回归只能解决二分类问题,不过,可以对其进行改进,使其同样可以用于多分类问题,其改造方式可以对多种算法(几乎全部二分类算法)进行改造,其有两种,简写为OvO与OvR OvR ...
- keras 修仙笔记一
对于牛逼的程序员,人家都喜欢叫他大神:因为大神很牛逼,人家需要一个小时完成的技术问题,他就20分钟就搞定.Keras框架是一个高度集成的框架,学好它,就犹如掌握一个法宝,可以呼风唤雨.所以学keras ...
随机推荐
- python常见释疑(有别于报错)(不定时更新)
文:铁乐与猫 01.在cmd运行py脚本后,直接回到了提示符,没有任何输出,看起来像是并没有运行一样. 答:你的感觉很可能是对的,但脚本很可能己经正常运行,只是你的代码里面很可能没有给出print提示 ...
- September 10th 2017 Week 37th Sunday
Dream most deep place, only then the smile is not tired. 梦的最深处,只有微笑不累. Everyday I expect I can go to ...
- Mongo.exe 无法定位程序输入点terminate于动态链接库 *.dll的解决办法
Win7 或者Winserver 上安装新版的Mongo后,总是提示如上问题,可使用如下方法解决: 一是系统更新到SP1,并安装了KB2999226这个更新包(重要): 二是安装安装 Visual C ...
- Golang channel 用法简介
channel 是 golang 里相当有趣的一个功能,大部分时候 channel 都是和 goroutine 一起配合使用.本文主要介绍 channel 的一些有趣的用法. 通道(channel), ...
- 【CF163E 】e-Government
题目 两个\(log\)的树状数组套树剖? 我们对于给出的\(n\)个模式串建立\(AC\)自动机,之后对于每一个询问串直接丢上去匹配 如果这里是暴力的话,我们直接一路跳\(fail\)累加作为结束位 ...
- Java和Python安装和编译器使用
java 一.安装jdk时第二次选择安装目录时,这是在安装jre,可以直接取消. 二.配置三个环境变量(在WIN7下) 右键我的电脑>属性>高级系统设置>环境变量>系统变量. ...
- Windows10中以管理员身份打开命令提示符
WIN+X+A (要关闭替换) 从任务栏启动 从开始菜单 从资源管理器 连贯即(alt+f+s+a)
- 造成MySQL全表扫描的原因
全表扫描是数据库搜寻表的每一条记录的过程,直到所有符合给定条件的记录返回为止.通常在数据库中,对无索引的表进行查询一般称为全表扫描:然而有时候我们即便添加了索引,但当我们的SQL语句写的不合理的时候也 ...
- mybatis提取<where><if>共用代码
mybatis项目dao层中很多sql语句都会拥有某些相同的查询条件,以<where><if test=""></if></where&g ...
- 自定义单选框radio样式
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...