python-docx操作word文件(*.docx)
基础操作
from docx import Document
from docx.shared import Inches
# 创建空文档
document = Document()
# 添加标题,设置级别level,0为Title,1或省略为Heading 1,0<=level<=9
document.add_heading('Document Title', 0)
# 添加段落,参数为text=''和style=None
p = document.add_paragraph('A plain paragraph having some ')
# 添加run对象,参数为text=None和style=None,
# run对象有bold(加粗)和italic(斜体)这两个属性
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote')
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'first item in ordered list', style='List Number'
)
# 添加图片
document.add_picture('monty-truth.png', width=Inches(1.25))
# 添加表格
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
对象关系
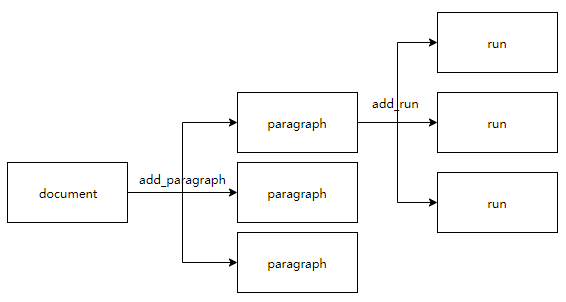
document.add_paragraph()之后,默认paragraph的内容到第一个run中。
添加样式
中文字体微软雅黑,西文字体Times New Roman
import docx
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.oxml.ns import qn
from docx.shared import Cm, Pt
document = Document()
# 设置一个空白样式
style = document.styles['Normal']
# 设置西文字体
style.font.name = 'Times New Roman'
# 设置中文字体
style.element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑')
首行缩进
# 获取段落样式
paragraph_format = style.paragraph_format
# 首行缩进0.74厘米,即2个字符
paragraph_format.first_line_indent = Cm(0.74)
单独设置标题样式
# 设置标题
title_ = document.add_heading(level=0)
# 标题居中
title_.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 添加标题内容
title_run = title_.add_run(title)
# 设置标题字体大小
title_run.font.size = Pt(14)
# 设置标题西文字体
title_run.font.name = 'Times New Roman'
# 设置标题中文字体
title_run.element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑')
设置超链接
def add_hyperlink(paragraph, url, text, color, underline):
"""
A function that places a hyperlink within a paragraph object.
:param paragraph: The paragraph we are adding the hyperlink to.
:param url: A string containing the required url
:param text: The text displayed for the url
:return: The hyperlink object
"""
# This gets access to the document.xml.rels file and gets a new relation id value
part = paragraph.part
r_id = part.relate_to(url, docx.opc.constants.RELATIONSHIP_TYPE.HYPERLINK, is_external=True)
# Create the w:hyperlink tag and add needed values
hyperlink = docx.oxml.shared.OxmlElement('w:hyperlink')
hyperlink.set(docx.oxml.shared.qn('r:id'), r_id, )
# Create a w:r element
new_run = docx.oxml.shared.OxmlElement('w:r')
# Create a new w:rPr element
rPr = docx.oxml.shared.OxmlElement('w:rPr')
# Add color if it is given
if not color is None:
c = docx.oxml.shared.OxmlElement('w:color')
c.set(docx.oxml.shared.qn('w:val'), color)
rPr.append(c)
# Remove underlining if it is requested
if not underline:
u = docx.oxml.shared.OxmlElement('w:u')
u.set(docx.oxml.shared.qn('w:val'), 'none')
rPr.append(u)
# Join all the xml elements together add add the required text to the w:r element
new_run.append(rPr)
new_run.text = text
hyperlink.append(new_run)
paragraph._p.append(hyperlink)
return hyperlink
document = docx.Document()
p = document.add_paragraph()
#add a hyperlink with the normal formatting (blue underline)
hyperlink = add_hyperlink(p, 'http://www.google.com', 'Google', None, True)
#add a hyperlink with a custom color and no underline
hyperlink = add_hyperlink(p, 'http://www.google.com', 'Google', 'FF8822', False)
document.save('demo.docx')
上面的函数是对整段内容直接添加链接,日常使用的时候,超链接多为关键词,或<a>标签的格式,用paragraph和run这两个对象的关系来解决。
比如有文本内容如下,将其中的<a>标签换为超链接:
"""I am trying to add an hyperlink in a MS Word document using docx module for <a href="python.org">Python</a>. Just do it."""
# 判断字段是否为链接
def is_text_link(text):
for i in ['http', '://', 'www.', '.com', '.org', '.cn', '.xyz', '.htm']:
if i in text:
return True
else:
return False
# 对段落中的链接加上超链接
def add_text_link(document, text):
paragraph = document.add_paragraph()
# 根据<a>标签拆分文本内容
text = re.split(r'<a href="|">|</a>',text)
keyword = None
for i in range(len(text)):
# 对非链接和非关键词的内容,通过run直接加入段落中
if not is_text_link(text[i]):
if text[i] != keyword:
paragraph.add_run(text[i])
# 对链接和关键词,使用add_hyperlink插入超链接
elif i + 1<len(text):
url=text[i]
keyword=text[i + 1]
add_hyperlink(paragraph, url, keyword, None, True)
参考文档
- https://python-docx.readthedocs.io/en/latest/index.html
- https://github.com/python-openxml/python-docx/issues/74
- http://www.warmeng.com/2018/12/02/auto_report/
python-docx操作word文件(*.docx)的更多相关文章
- DocX操作word生成报表
1.DocX简介 1.1 简介 DocX是一个在不需要安装word的情况下对word进行操作的开源轻量级.net组件,是由爱尔兰的一个叫Cathal Coffey的博士生开发出来的.DocX使得操作w ...
- 借助python工具从word文件中抽取相关表的定义,最后组装建表语句-非常好
借助python工具从word文件中抽取表的定义,最后组装建表语句-非常好 --如有转载请以超链接的方式注明原文章出处,谢谢大家.请尊重每一位乐于分享的原创者 1.python脚本 ## -*- co ...
- python中操作csv文件
python中操作csv文件 读取csv improt csv f = csv.reader(open("文件路径","r")) for i in f: pri ...
- C#中使用Spire.docx操作Word文档
使用docx一段时间之后,一些地方还是不方便,然后就尝试寻找一种更加简便的方法. 之前有尝试过使用Npoi操作word表格,但是太烦人了,随后放弃,然后发现免费版本的spire不错,并且在莫种程度上比 ...
- C#使用Docx操作word文档
C#使用Docx编写word表格 最近接手了一个小Demo,要求使用Docx,将Xml文件中的数据转换为word文档,组织数据形成表格. 写了已经一周,网络上的知识太零碎,就想自己先统计整理出来,方便 ...
- C# : 操作Word文件的API - (将C# source中的xml注释转换成word文档)
这篇博客将要讨论的是关于: 如何从C#的source以及注释, 生成一份Word格式的关于各个类,函数以及成员变量的说明文档. 他的大背景如下...... 最近的一个项目使用C#, 分N个模块, 在项 ...
- DSO Framer Control Object 操作word文件
<1>DSO Framer Control Object 实现加载word文件的不可编辑 axFramerControl1.Open(OldPath); this.axFramerCont ...
- .net操作word lib DocX
http://cathalscorner.blogspot.hk/2010/06/cathal-why-did-you-create-docx.html using (DocX document = ...
- Python多进程操作同一个文件,文件锁问题
最近工作当中做了一个项目,这个项目主要是操作文件的. 在操作耗时操作的时候,我们一般采用多线程或者多进程.在开发中,如果多个线程需要对文件进行读写操作,就需要用到线程锁或者是文件锁. 使用fcntl ...
随机推荐
- 浅谈java动态代理
- python中的字符串编码问题——4.unicode编解码(以实际工作中遇到的韩文编码为例)
韩文unicode编解码 问题是这样,工作中遇到有韩文数据出现乱码,说是unicode码. 类似这样: id name 323 52186863 149 63637538 314 65516863 ...
- 使用Axure设计中,大型的后台系统原型总结
使用Axure设计中,大型的后台系统原型总结 2018年4月16日luodonggan 在产品原型设计中,经常会涉及到后台系统原型的设计,如何设计出更规范标准的后台系统原型,是很多产品同行们都会遇到的 ...
- 使用 Azure CLI 管理 Azure 虚拟网络和 Linux 虚拟机
Azure 虚拟机使用 Azure 网络进行内部和外部网络通信. 本教程将指导读者部署两个虚拟机,并为这些 VM 配置 Azure 网络. 本教程中的示例假设 VM 将要托管包含数据库后端的 Web ...
- 【Oracle】存储过程写法小例子
1.存储过程的基本语法: CREATE OR REPLACE PROCEDURE 存储过程名(param1 in type,param2 out type) IS 变量1 类型(值范围); 变量2 类 ...
- PHP中抽象方法、抽象类和接口的用法
在类中,没有方法体的方法就是抽象方法. abstract 可见性 function 方法名称(参数1,.....); // 如果没有显示地指定可见性,则默认为public 如: public ...
- Android开发经验02:Android 项目开发流程
Android开发完整流程: 一.用户需求分析 用户需求分析占据整个APP开发流程中最重要的一个环节.一款APP开发的成功与否很大程度都决定于此.这里所说的用户需求分析指的是基于用户的要求所进行的 ...
- JSTORM 问题排查
## 运行时topology的task列表中报"task is dead"错误有几个原因可能导致出现这个错误: 1. task心跳超时,导致nimbus主动kill这个task所在 ...
- HtmlImageGenerator字体乱码问题解决、html2image放linux上乱码问题解决
使用html2image-0.9.jar生成图片. 在本地window系统正常,放到服务器linux系统时候中文乱码问题.英文可以,中文乱码应该就是字体问题了. 一.首先需要在linux安装字体,si ...
- linux系统下安装两个或多个tomcat
编辑环境变量:vi /etc/profile 加入以下代码(tomcat路径要配置自己实际的tomcat安装目录) ##########first tomcat########### CATALINA ...