Jsoup代码示例、解析网页+提取文本
使用Jsoup解析HTML
那么我们就必须用到HttpClient先获取到html
同样我们引入HttpClient相关jar包
以及commonIO的jar包
我们把httpClient的基本代码写上,然后解析网页 得到文档对象
我们获取title和制定id的文档对象
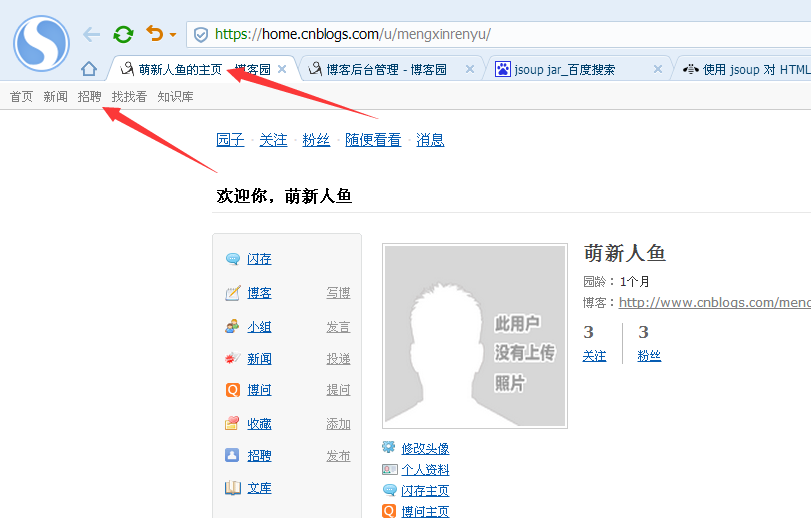
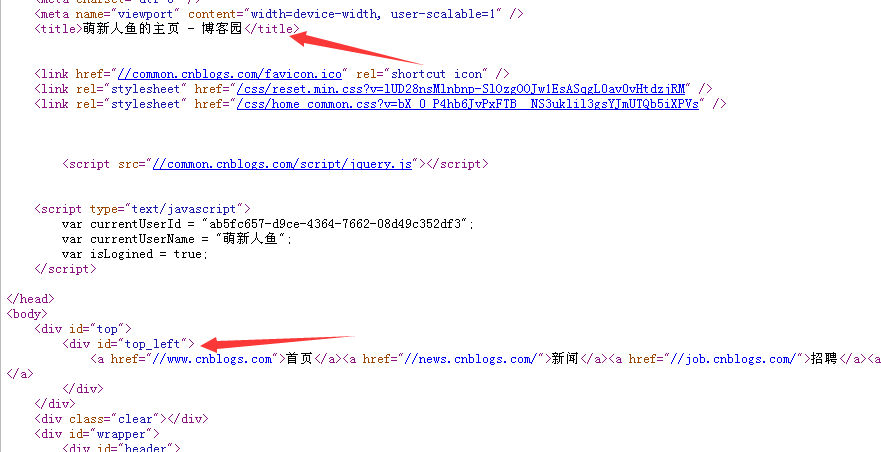
代码实例:
package com.zhi.jsoup1; import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://home.cnblogs.com/u/mengxinrenyu/"); //2、创建实例 httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0"); CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close(); Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title); element=doc.getElementById("top_left"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
由于网页我是登陆以后的,所以会出现以下错误
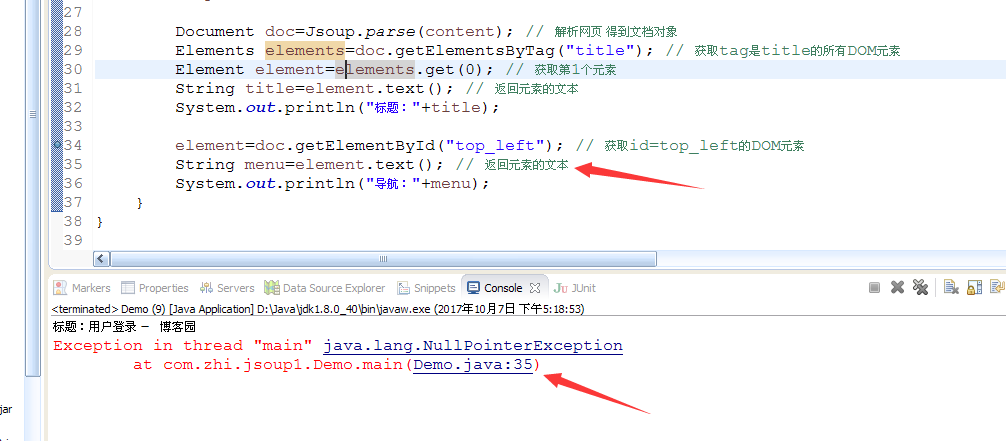
因为请求的是某个登陆账户下的网页,所以网页会提示登录。从没没有相应id的元素,返回NPE。
我们换一个新闻页面试一下

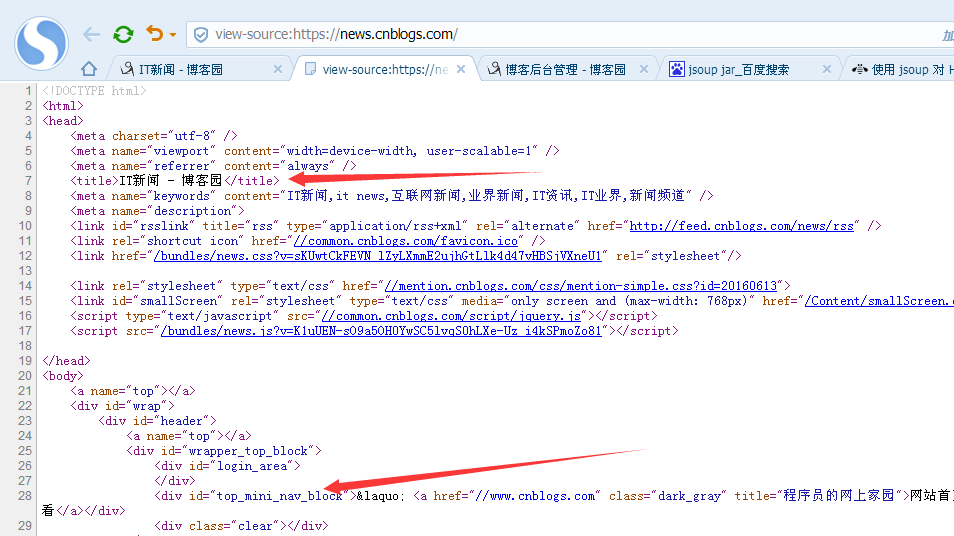
代码示例:
public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://news.cnblogs.com/"); //2、创建实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0");
CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close();
Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title);
element=doc.getElementById("top_mini_nav_block"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
运行如图:
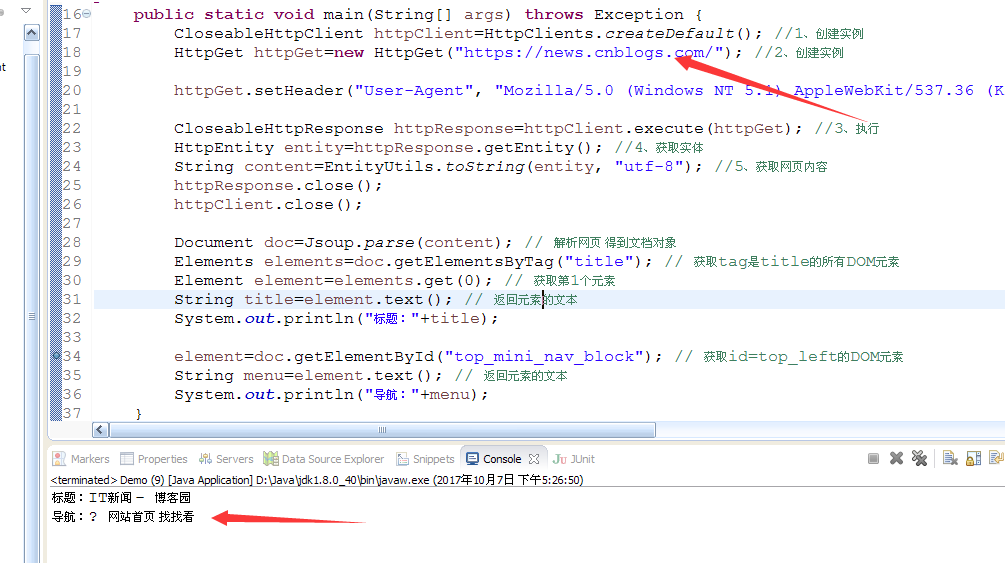
Jsoup代码示例、解析网页+提取文本的更多相关文章
- 使用java开源工具httpClient及jsoup抓取解析网页数据
今天做项目的时候遇到这样一个需求,需要在网页上展示今日黄历信息,数据格式如下 公历时间:2016年04月11日 星期一 农历时间:猴年三月初五 天干地支:丙申年 壬辰月 癸亥日 宜:求子 祈福 开光 ...
- 使用Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)(转)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- 【python】使用HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies
一.从HTML文档中提取链接 模块HTMLParser,该模块使我们能够根据HTML文档中的标签来简洁.高效地解析HTML文档. 处理HTML文档的时候,我们常常需要从其中提取出所有的链接.使用HTM ...
- Jsoup解析网页源码时常用的Element(s)类
Jsoup解析网页源码时常用的Element(s)类 一.简介 该类是Node的直接子类,同样实现了可克隆接口.类声明:public class Element extends Node 它表示由一个 ...
- Jsoup解析网页html
Jsoup解析网页html 解析网页demo: 利用Jsoup获取截图中的数据信息: html代码片段: <!-- 当前基金档案\计算\定投\开户 start --> <div cl ...
- [译]使用BeautifulSoup和Python从网页中提取文本
如果您要花时间浏览网页,您可能遇到的一项任务就是从HTML中删除可见的文本内容. 如果您使用的是Python,我们可以使用BeautifulSoup来完成此任务. 设置提取 首先,我们需要获取一些HT ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...
- Jsoup提取文本时保留标签
使用Jsoup来对html进行处理比较方便,你可能会用它来提取文本或清理html标签.如果你想提取文本时保留标签,可以使用Jsoup.clean方法,参数为html及标签白名单: Jsoup.clea ...
随机推荐
- String 和 new String()的区别
String 和 new String()的区别 For Example String str1 = "ABC" String str2 = new String("AB ...
- 解决:”ssh-keygen 不是内部或外部命令“ 的问题
相信大家在 码云生成/添加SSH公钥的过程中遇到一个比较常见的问题, 在cmd,命令行输入 ssh-keygen -t rsa -C "xxxxx@xxxxx.com" ; xxx ...
- JS 数组的常用方法归纳之不改变原数组和其他
不改变原数组的方法 concat() 连接两个或多个数组,不改变现有数组,返回新数组,添加的是数组中的元素 join(",") 把数组中的所有元素放入一个字符串,通过‘,’分隔符进 ...
- Flask搭建简单的get请求
用virtualenv venv搭建python虚拟环境.然后执行. #!/usr/bin/env pythonfrom flask import Flask, render_template, re ...
- Win10不能远程其他远程计算机的解决办法
Win10不能远程其他远程计算机的解决办法 转自: https://blog.csdn.net/qq_38197830/article/details/69488236 首先打开控制面板——> ...
- <每日一题> Day1:CodeForces.1140D.MinimumTriangulation(思维题)
题目链接 参考代码: #include <iostream> using namespace std; int main() { ; int n; cin >> n; ; i ...
- RandomAccessFile类使用说明
RandomAccessFile类是Java Io体系中功能最为丰富的文件访问类,它提供了众多的文件访问方法.RandomAccessFile类支持“随机访问”方式,这里的“随机”是指程序可以直接跳到 ...
- [集合Set]HashSet、LinkedHashSet TreeSet
Set Set是不包含重复元素的集合.更正式地,集合不包含一对元素e1和e2,使得e1.equals(e2),并且最多一个空元素. 无索引,不可以重复,无序(存取不一致) Set接口除了继承自Coll ...
- exec 命令
source source命令即点(.)命令. 在bash下输入man source,找到source命令解释处,可以看到解释”Read and execute commands from filen ...
- ASP.NET MVC @html帮助类
原文:https://www.cnblogs.com/caofangsheng/p/10462494.html HTML Helpers是用来创建HTML标签进而创建HTML控件的.HTML Help ...