Jsoup代码示例、解析网页+提取文本
使用Jsoup解析HTML
那么我们就必须用到HttpClient先获取到html
同样我们引入HttpClient相关jar包
以及commonIO的jar包
我们把httpClient的基本代码写上,然后解析网页 得到文档对象
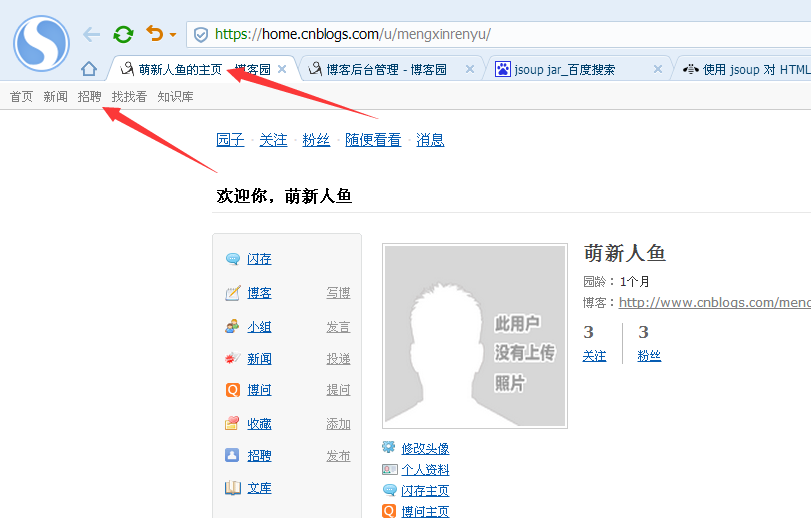
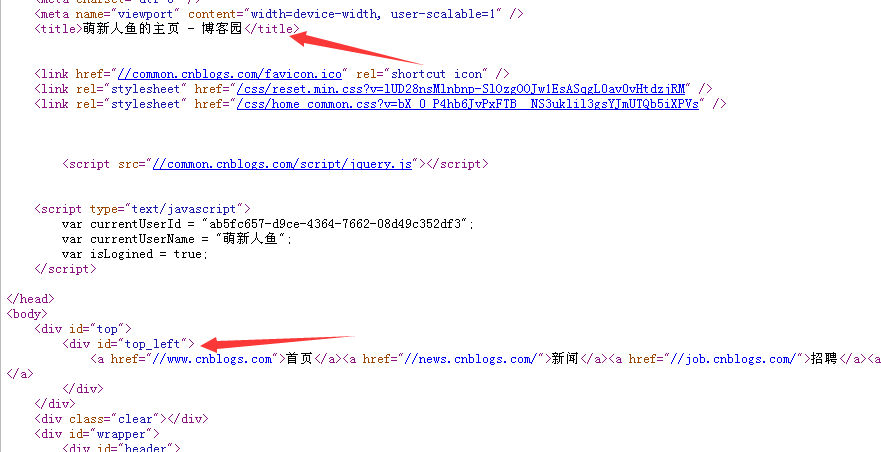
我们获取title和制定id的文档对象
代码实例:
package com.zhi.jsoup1; import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://home.cnblogs.com/u/mengxinrenyu/"); //2、创建实例 httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0"); CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close(); Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title); element=doc.getElementById("top_left"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
由于网页我是登陆以后的,所以会出现以下错误
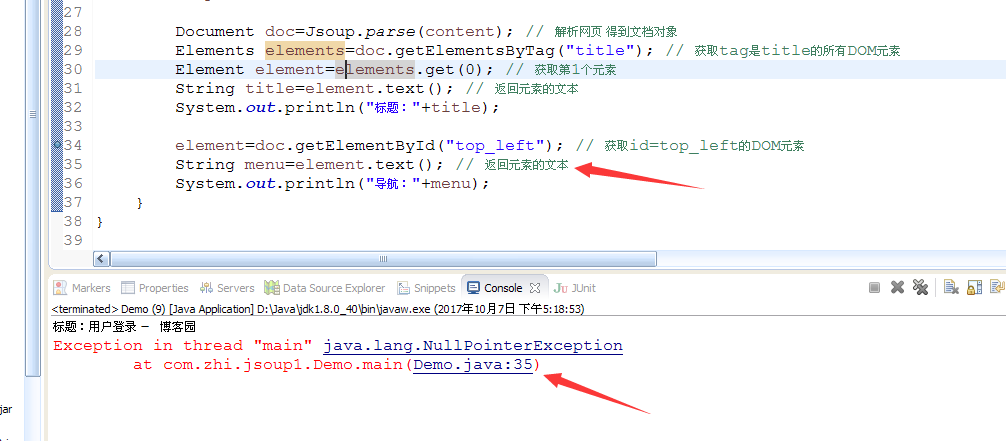
因为请求的是某个登陆账户下的网页,所以网页会提示登录。从没没有相应id的元素,返回NPE。
我们换一个新闻页面试一下

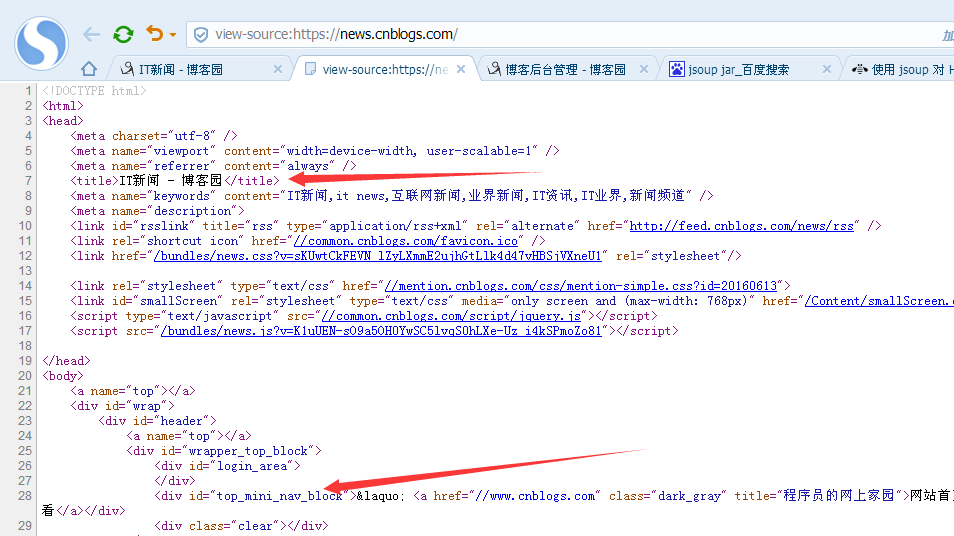
代码示例:
public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://news.cnblogs.com/"); //2、创建实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0");
CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close();
Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title);
element=doc.getElementById("top_mini_nav_block"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
运行如图:
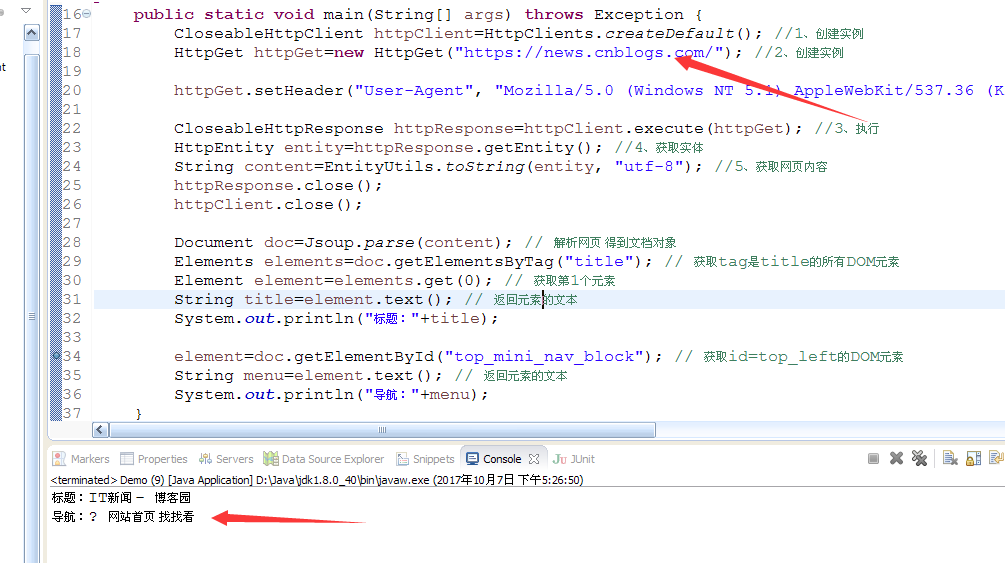
Jsoup代码示例、解析网页+提取文本的更多相关文章
- 使用java开源工具httpClient及jsoup抓取解析网页数据
今天做项目的时候遇到这样一个需求,需要在网页上展示今日黄历信息,数据格式如下 公历时间:2016年04月11日 星期一 农历时间:猴年三月初五 天干地支:丙申年 壬辰月 癸亥日 宜:求子 祈福 开光 ...
- 使用Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)(转)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- 【python】使用HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies
一.从HTML文档中提取链接 模块HTMLParser,该模块使我们能够根据HTML文档中的标签来简洁.高效地解析HTML文档. 处理HTML文档的时候,我们常常需要从其中提取出所有的链接.使用HTM ...
- Jsoup解析网页源码时常用的Element(s)类
Jsoup解析网页源码时常用的Element(s)类 一.简介 该类是Node的直接子类,同样实现了可克隆接口.类声明:public class Element extends Node 它表示由一个 ...
- Jsoup解析网页html
Jsoup解析网页html 解析网页demo: 利用Jsoup获取截图中的数据信息: html代码片段: <!-- 当前基金档案\计算\定投\开户 start --> <div cl ...
- [译]使用BeautifulSoup和Python从网页中提取文本
如果您要花时间浏览网页,您可能遇到的一项任务就是从HTML中删除可见的文本内容. 如果您使用的是Python,我们可以使用BeautifulSoup来完成此任务. 设置提取 首先,我们需要获取一些HT ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...
- Jsoup提取文本时保留标签
使用Jsoup来对html进行处理比较方便,你可能会用它来提取文本或清理html标签.如果你想提取文本时保留标签,可以使用Jsoup.clean方法,参数为html及标签白名单: Jsoup.clea ...
随机推荐
- Junit 3.8源码分析
JUnit背景介绍 JUnit是由Erich Gamma和Kent Beck 编写的一个回归测试框架(regression testing framework).Junit测试是程序员测试,即所谓的白 ...
- oracle--本地网络配置tnsnames.ora和监听器listener.ora
文件tnsnames.ora 是给orcl客户端使用 配置本地网络服务:(客户端) 第一种使用暴力方式直接操作: 修改:C:\app\Administrator\product\11.2.0\dbho ...
- 安装paramiko的方法
打开cmd命令行 输入 cd /d C:\Python27\Scripts 输入 pip install paramiko pip install pika -i https://pypi.doub ...
- 创建带标签页的MDI WinForms应用程序
http://www.cnblogs.com/island/archive/2008/12/02/mditab.html 创建MDI应用程序 先创建”Windows窗体应用程序”解决方案Tabable ...
- 如何利用Chrome进行跨域调试
为什么要跨域调试: 拿嵌入式web开发说,代码都是跑在板子上,我一个优雅的前端开发要每次改完代码都打包到板子上,用板子的地址打开,这是人做的事??? 怎么跨域调试: 1.升级Chrome为最新版本 2 ...
- node开发一个接口详细步骤
最近在做后台系统改版,由于目前接口还没出来,就自己用nodejs写了个简单的接口. 我这里用的是nodejs+mysql的 这里不讲nodejs和mysql的安装.这些基础略过. 首先创建文件夹.cd ...
- 超详细的DOM操作(增删改查)
操作DOM的核心就是增删改查 原文地址:https://jianshu.com/p/b0aa846f4dcc 目录 一.节点创建型API 1.1 createElement 1.2 createTex ...
- 380-Xilinx Kintex UltraScale FPGA KCU1500 Acceleration Development Kit
Xilinx Kintex UltraScale FPGA KCU1500 Acceleration Development Kit Product Description The Kintex® U ...
- Jupyter配置工作路径
在修改之前,C:\Users\Administrator\ .jupyter 目录下面只有一个“migrated”文件. 打开命令窗口(运行->cmd),进入python的Script目录下输入 ...
- Car的旅行路线(Floyd+模拟)
题目地址 贼鸡儿猥琐的一道题 好在数据不毒瘤,而且Floyd就OK了. 这道题的难点在于 建图,也很考验模拟能力,需要十分的有耐心. 建图 题目中告诉了我们一个矩形的三个点 我们在平面直角坐标系中随便 ...