es之Source字段和store字段
PUT /website/blog/
{
"title" : "elasticsearchshi是是什么",
"author" : "zhangsan",
"titleScore" : 66.666
}
在检索出数据之后,我们观察有一个_source这样的字段,
【注意】_source字段在我们检索时非常重要;
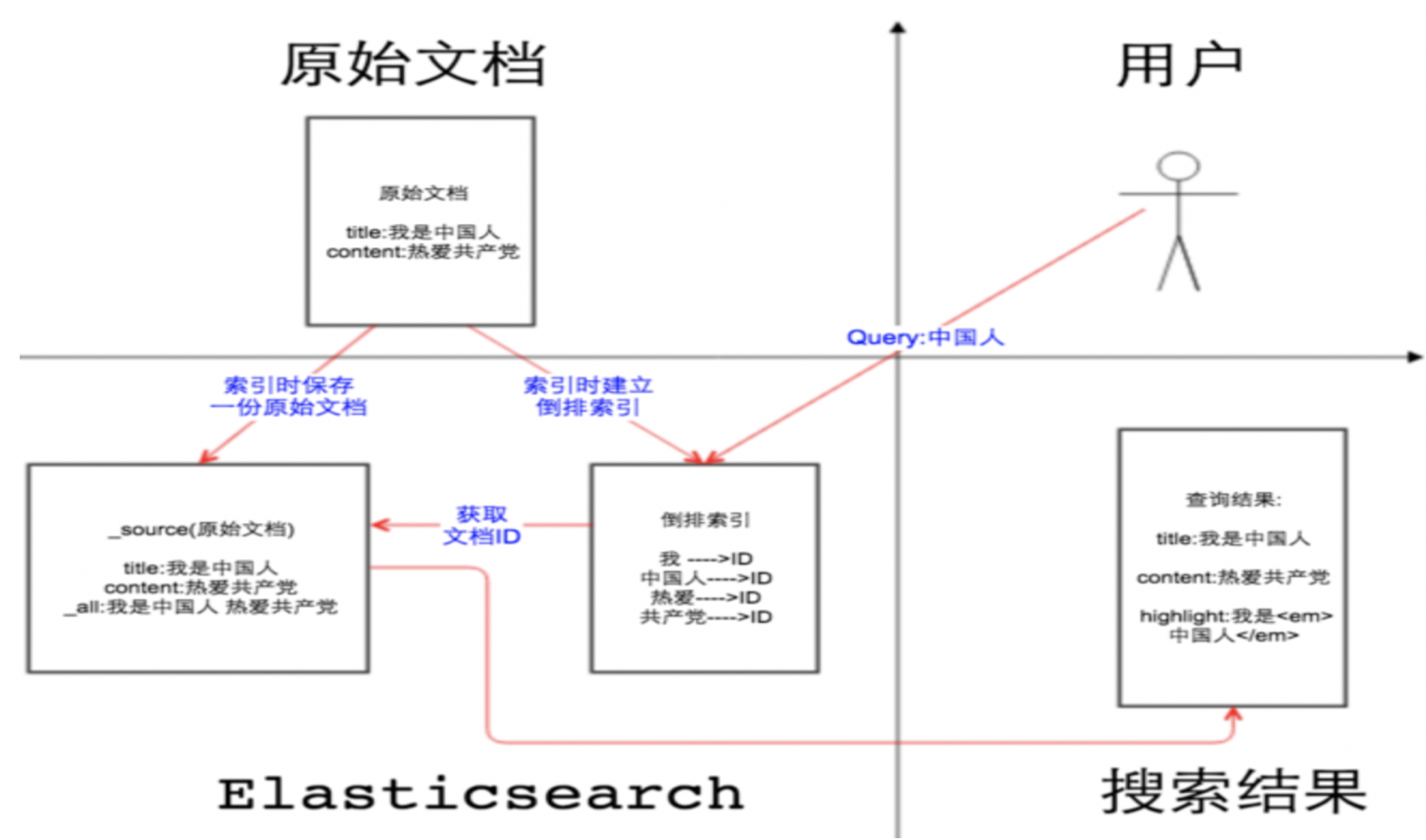
Es除了将数据保存在倒排索引中,另外还有一分原始文档
原始文档就是存储在_source中的;
其实我们在elasticsearch中搜索文档,查看文档的内容就是_source中的内容
我们可以在设置mapping的过程中将source字段开启或者关闭:
PUT weisite
{
"mappings":{
"article":{
"_source": {"enabled": true},
"properties":{
"id":{"type": "text", "store": true },
"title":{"type": "text","store": true},
"readCounts":{"type": "integer","store": true},
"times": {"type": "date", "index": "false"}
}
}
}
}
那么source字段有什么作用
| ID _source | 倒排索引 | ID 原始文档 |
|---|---|---|
| 1 {‘我爱中国’} | 我爱[1,2,3] 中国[1] | 1 我爱中国 |
| 2 {‘我爱游戏’} | 游戏[2] | 2 我爱游戏 |
| 3 {‘我爱游戏’} | 爱[1,2,3] | 3 我啥都爱 |
1、如果我们关闭source字段,也就是enable:false,那么在检索过程中会根据关键字比如”游戏”去倒排索引【记录了词项和文档之间的对应关系】中查询文档的ID,但是source字段的enable:false,那么原始文档中没有这些内容,就只能回显文档的ID,字段内容是找不到的
2、如果我们开启source字段,也就是enable:true,那么在检索过程过程中,客户端只需要解析存储的source JSON串,不要通过倒排索引表去检索,仅需要一次IO,就可以返回整个文档的结果
【注意】:
source字段默认是存储的, 什么情况下不用保留source字段?如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,最后返回文档id,查看文档内容会再次到mysql或者hbase中取数据
把大字段的内容存在Elasticsearch中只会增大索引,这一点文档数量越大结果越明显,如果一条文档节省几KB,放大到亿万级的量结果也是非常可观的。
如果想要关闭_source字段,在mapping中的设置如下:
PUT weisite
{
"mappings":{
"article":{
"_source": {"enabled": false},
"properties":{
"id":{"type": "text", "store": true },
"title":{"type": "text","store": true},
"readCounts":{"type": "integer","store": true},
"times": {"type": "date", "index": "false"}
}
}
}
}
GET /weisite/article/1
GET /weisite/article/_search
{
"query": {
"match_phrase": {
"title": "this"
}
}
}
如果只想存储几个字段的原始值,那么在_source属性下还有两个字段:include和exclude:
PUT weisite
{
"mappings":{
"article":{
"_source": {
"includes": [
"title"
],
"excludes": [
"content"
]
},
"properties":{
"id":{"type": "text", "store": true },
"title":{"type": "text","store": true},
"readCounts":{"type": "integer","store": true},
"times": {"type": "date", "index": true},
"content" : {"type" : "text" , "index": true}
}
}
}
}
还有一个store属性:
Store**属性为true的时候会将指定的字段写入索引**(然后查询的时候使用倒排索引去查询,相比_source多一次IO),默认是false的;
其次是,如果想让检索出的字段进行高亮显示,那么(store和source要至少保留一个)
es之Source字段和store字段的更多相关文章
- openerp学习笔记 计算字段、关联字段(7.0中非计算字段、关联字段只读时无法修改保存的问题暂未解决)
计算字段.关联字段,对象修改时自动变更保存(当 store=True 时),当 store=False 时,默认不支持过滤和分组7.0中非计算字段.关联字段只读时无法修改保存的问题暂未解决 示例代码: ...
- row_number()over(partition by 字段 order by 字段)ID,修改重复行的字段值。
案例分析: 现在要查询一个表单里面的运费结果,但是他还有分录,为了显示分录,必须把表头显示出来,问题是,他要查询运费的合计, 但是这样就会导致重复行也加进去了,这样显然数据不准,为此,可以把重复的行设 ...
- access数据库用sql语句添加字段,修改字段,删除字段
用 Create Table 建立一个表 Table1 ,主键是自动编号字段,另一个字段是长度是 10 的文本字段. 代码如下:CREATE TABLE Table1 (Id COUNTER CONS ...
- Oracle 查询库中所有表名、字段名、字段名说明,查询表的数据条数、表名、中文表名、
查询所有表名:select t.table_name from user_tables t;查询所有字段名:select t.column_name from user_col_comments t; ...
- MySQL添加字段和删除字段
MySQL添加字段应该如何实现呢?这是很多刚刚接触MySQL数据库的新人都提到过的问题,下面就为您介绍MySQL添加字段和删除字段的方法,希望对您能有所启迪. MySQL添加字段: alter tab ...
- MySQL添加字段和修改字段的方法
添加表字段 alter table table1 add transactor varchar(10) not Null; alter table table1 add id int unsign ...
- MySql增加字段、删除字段、修改字段
MySql增加字段.删除字段.修改字段名称.修改字段类型 1.增加一个字段 alter table user add COLUMN new1 VARCHAR(20) DEFAULT NULL; / ...
- oracle,如何查看视图结构,获得视图中的字段名称、字段类型、字段长度等。
需要获得一个视图中的字段名称.字段类型.字段长度等信息,该如何编写sql语句.通过select * from user_views可以获得给定用户下所有的视图名称了,但是没找到如何获取视图结构的解决方 ...
- SQL SERVER统计服务器所有的数据库(数据库文件)、表(表行数)、字段(各字段)等详细信息
原文:SQL SERVER统计服务器所有的数据库(数据库文件).表(表行数).字段(各字段)等详细信息 USE STAT GO SET NOCOUNT ON IF EXISTS(SELECT 1 FR ...
随机推荐
- oracle表名中带@什么意思
例如:select * from dim.dim_area_no@to_dw @后是实例名或数据源,一个简单例子,服务器上创建了2个数据库实例,名称分别为HR.BOSS, 如果你用PL/SQL DEV ...
- [转帖]Oracle 查询各表空间使用情况--完善篇
Oracle 查询各表空间使用情况--完善篇 链接:http://blog.itpub.net/28602568/viewspace-1770577/ 标题: Oracle 查询各表空间使用情况--完 ...
- Thinkphp3.2 Redis缓存session
Thinkphpsession缓存没有redis类库 Redis.class.php放在Library/Think/Session/Driver/下: <?php /** * +-------- ...
- S-阶乘除法
输入两个正整数 n, m,输出 n!/m!,其中阶乘定义为 n!= 1*2*3*...*n (n>=1). 比如,若 n=6, m=3,则n!/m!=6!/3!=720/6=120. 是不是很简 ...
- logstash启动时找不到自定义的JAVA_HOME环境变量
logstash java 版本问题 配置logstash收集应用日志时出现报错,说是找不到JAVA_HOME环境变量,但是明明已经设置了 logstash要求java 1.8以上,查看生产环境: [ ...
- PHP支付宝手机网站支付功能
1.开通支付宝商家中心里面的手机网站支付 2.再去开放平台-开发者中心-创建移动支付的应用-获取到APPID 3.接着去文档中心下载DEMO 其实demo很简单.如果第一次看的话会存在看不懂的状态. ...
- python基础知识的入门介绍
一.什么是编程语言 任何词语都是一种高度的概括和总结,所以找关键字.如下: (1)1.什么是"语言":一个人与另一个人沟通的介质 2人将自己的思维逻辑和想法通过计算机能过识别的语言 ...
- egret 发布ios记录
根据官方文档http://developer.egret.com/cn/github/egret-docs/Native/native/hybrid/hybrid/index.html 将现有的项目发 ...
- VMware虚拟机NAT模式无法上外网
VMware虚拟机NAT模式无法上外网排错思路 1,确保三种模式只有一种在连接 2,确保ip配置正确 配置的子网跟DHCP必须是同一网段 3,确保网关配置正确 网关不管怎么配,一定不要配192.168 ...
- 03python面向对象编程3
案例学习 # notebook.pyimport datetime # Store the next available id for all new notes last_id = 0 class ...