开发-日常工具:TFS(Team Foundation Server)
| ylbtech-开发-日常工具:TFS(Team Foundation Server) |
TFS(Team Foundation Server)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
| 1.返回顶部 |
- 外文名:Team Foundation Server
- 简 称:TFS
- 属 性:分布式文件系统
目录
- 1 特性
- 2 总体结构
- ▪ NameServer
- ▪ DataServer
- 3 平滑扩容
- 4 存储机制
- 5 容错机制
- ▪ 集群容错
- ▪ NameServer容错
- ▪ DataServer容错
| 2.返回顶部 |
特性
总体结构
NameServer
DataServer
平滑扩容
当有服务器故障或者下线退出时(单个集群内的不同网段机器不能同时退出),不影响TFS的服务。此时!NameServer会检测到备份数减少的Block,对这些Block重新进行数据复制。
存储机制
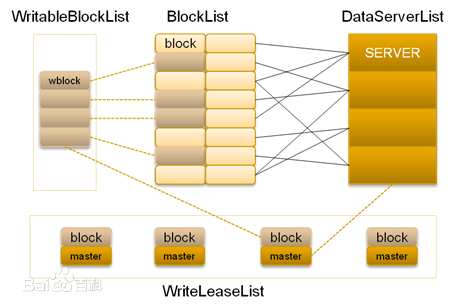
在DataServer端,每个Block可能会有多个实际的物理文件组成:一个主Physical Block文件,N个扩展Physical Block文件和一个与该Block对应的索引文件。Block中的每个小文件会用一个block内唯一的fileid来标识。!DataServer会在启动的时候把自身所拥有的Block和对应的Index加载进来。
容错机制
集群容错
NameServer容错
另外NameServer和DataServer之间也会有定时的heartbeat,DataServer会把自己拥有的Block发送给!NameServer。NameServer会根据这些信息重建DataServer和Block的关系。
DataServer容错
并发机制
现有TFS并不支持并发写一个文件。一个文件只会有一个用户在写。这在TFS的设计里面对应着是一个block同时只能有一个写或者更新操作。
文件名结构
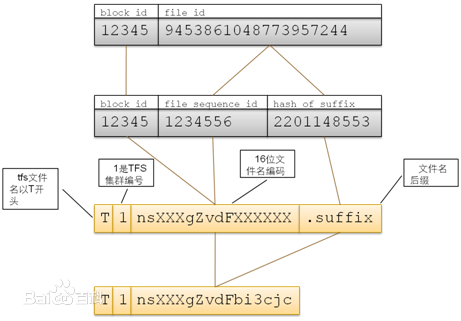
TFS客户程序在读文件的时候通过将文件名转换为BlockID和FileID信息,然后可以在!NameServer取得该块所在!DataServer信息(如果客户端有该Block与!DataServere的缓存,则直接从缓存中取),然后与!DataServer进行读取操作。
| 3.返回顶部 |
| 4.返回顶部 |
| 5.返回顶部 |
| 6.返回顶部 |
 |
作者:ylbtech 出处:http://ylbtech.cnblogs.com/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 |
开发-日常工具:TFS(Team Foundation Server)的更多相关文章
- TFS(Team Foundation Server)介绍和入门
在本文的两个部分中,我将介绍Team Foundation Server的一些核心特征,重点介绍在本产品的日常应用中是怎样将这些特性结合在一起使用的. 作为一名软件开发者,在我的职业生涯中,我常常会用 ...
- TFS(Team Foundation Server)简介和新手入门
在两部分的文章.我会介绍Team Foundation Server一些核心功能,着重于产品的日常应用是如何将这些功能结合使用. 作为一个软件开发.在我的职业生涯,.我常常用于支持软件开发过程中大量的 ...
- TFS(Team Foundation Server)敏捷使用教程(四):工作项跟踪(1)
工作项跟踪(1) 可跟踪性是软件过程的重要能力,TFS主要是以工作项来实现过程的可跟踪性.曾有人问:"你们实际项目里的工作项是怎么样的?能不能让我们看看?"我也一直很好奇别的公司T ...
- TFS (Team Foundation Server) 2013集成Maven构建
Team Foundation Server原生就支持跨平台的构建,包括Ant和Maven两种构建方式.通过配置构建服务器,连接TFS源代码库,可以实现持续集成构建,自动检测代码库健康状况,进而实现自 ...
- TFS(Team Foundation Server) 权限设置记录
环境: TFS2012 + win7 1.安装好TFS 2.创建系统用户组: TFSAdmins.TFSDevs.TFSUsers 分别为TFS管理人员组.TFS开发人员组.TFS普通用户组. 如下图 ...
- 初探Team Foundation Server (TFS) 2015 REST API
REST是一种简洁方便的Web服务,通过基于http协议的远程通信,可以为多种客户端程序提供远程服务,大幅提高了服务器系统的可扩展性. 微软宣布从Team Foundation Server 从201 ...
- Visual Studio 6 (VC6)连接Team Foundation Server (TFS 2018),实现源代码的版本管理
1. 概述 Visual Studio 6(VB6, VC6, Foxpro-)是微软公司在1998年推出的一款基于Windows平台的软件开发工具,也是微软推出.NET开发框架之前的最后一个IDE工 ...
- PLSQL(PL/SQL)集成Team Foundation Server (TFS),实现数据库代码的版本管理
PL/SQL是面向Oralcle数据库的集成开发环境,是众多Oracle数据库开发人员的主要工具.由于PL/SQL(百度百科)不仅是一种SQL语言,更是一种过程编程语言,在项目实施过程中,会积累大量除 ...
- 在Sublime中集成Team Foundation Server (TFS),实现版本管理
Sublime是一款具有代码高亮.语法提示.自动完成且反应快速的编辑器软件,由于它开发的技术架构.丰富的插件,和轻盈而快速的编程响应,Sublime广受程序员的爱好.在C, C++, Javascri ...
随机推荐
- JS 的 Document对象
Document 对象是是window对象的一个属性,因此可以将document对象作为一个全局对象来访问. 当浏览器载入 HTML 文档, 它就会成为 Document 对象. Document对象 ...
- 利用ARouter实现组件间通信,解决子模块调用主模块问题
如果你还没使用过ARouter请你按照这篇下面博客尝试使用下然后再往下看组件通信的内容(不然的话可能会懵逼)Android Studio接入ARouter以及简单使用 如果你使用过ARouter请继续 ...
- 使用CXF开发WebService程序的总结(三):创建webservice客户端
1.创建一个maven子工程 ws_client,继承父工程 1.1 修改父工程pom配置 <modules> <module>ws_server</module> ...
- inetd - 因特网“超级服务”
总览 inetd - [ -d ] [ -q 队列长度 ] [ 配置文件名 ] 描述 inetd通常在系统启动时由/etc/rc.local引导.inetd会监听指定internet端口是否有连接要求 ...
- [转载]Ethernet,Half-Duplex/Full-Duplex,CSMA
原文地址:Ethernet,Half-Duplex/Full-Duplex,CSMA/CD,Auto-Negotiation作者:心田麦浪 CSMA/CD(Carrier Sense Multiple ...
- linux 生成密钥和公钥,实现免密登录
1. 在相应的用户根目录下生成密钥公钥,输入如下命令: ssh-keygen -t rsa 2. 直接三次回车:会生成两个文件:id_rsa / id_rsa.pub,分别为密钥和公钥 3. 打开公 ...
- 【洛谷P3413】萌数
题目大意:求区间 [l,r] 内萌数的个数,其中萌数定义为数位中存在长度至少为 2 的回文子串的数字. 题解:l, r 都是 1000 位级别的数字,显然是一道数位 dp 的题目,暴力直接去世. 发现 ...
- ZROI 19.08.02 杂题选讲
给出\(n\)个数,用最少的\(2^k\)或\(-2^{k}\),使得能拼出所有数,输出方案.\(n,|a_i|\leq 10^5\). 显然一个绝对值最多选一次.这个性质非常强. 如果所有都是偶数, ...
- VMware安装Ghost版Win10 失败的解决方法
第一个失败点,是分区之后,重启,提示alt+ctrl+del要求重启,然后就是无限提示,解决方案:在重启读条的时候,按Esc,或者F2调整系统启动优先级读取位置,设置为CD的那个,就可以进入到安装系统 ...
- Redis实战(十七)Redis各个版本新特性
序言 Redis1.0 Redis2.0 Redis3.0 Redis4.0 Redis5.0 资料