SQL的多表查询(Navicat)
-- 部门表
CREATE TABLE dept (
id INT PRIMARY KEY PRIMARY KEY, -- 部门id
dname VARCHAR(50), -- 部门名称
loc VARCHAR(50) -- 部门所在地
);
-- 添加4个部门
INSERT INTO dept(id,dname,loc) VALUES
(10,'教研部','北京'),
(20,'学工部','上海'),
(30,'销售部','广州'),
(40,'财务部','深圳');
-- 职务表,职务名称,职务描述
CREATE TABLE job (
id INT PRIMARY KEY,
jname VARCHAR(20),
description VARCHAR(50)
);
-- 添加4个职务
INSERT INTO job (id, jname, description) VALUES
(1, '董事长', '管理整个公司,接单'),
(2, '经理', '管理部门员工'),
(3, '销售员', '向客人推销产品'),
(4, '文员', '使用办公软件');
-- 员工表
CREATE TABLE emp (
id INT PRIMARY KEY, -- 员工id
ename VARCHAR(50), -- 员工姓名
job_id INT, -- 职务id
mgr INT , -- 上级领导
joindate DATE, -- 入职日期
salary DECIMAL(7,2), -- 工资
bonus DECIMAL(7,2), -- 奖金
dept_id INT, -- 所在部门编号
CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id),
CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id)
);
-- 添加员工
INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES
(1001,'孙悟空',4,1004,'2000-12-17','8000.00',NULL,20),
(1002,'卢俊义',3,1006,'2001-02-20','16000.00','3000.00',30),
(1003,'林冲',3,1006,'2001-02-22','12500.00','5000.00',30),
(1004,'唐僧',2,1009,'2001-04-02','29750.00',NULL,20),
(1005,'李逵',4,1006,'2001-09-28','12500.00','14000.00',30),
(1006,'宋江',2,1009,'2001-05-01','28500.00',NULL,30),
(1007,'刘备',2,1009,'2001-09-01','24500.00',NULL,10),
(1008,'猪八戒',4,1004,'2007-04-19','30000.00',NULL,20),
(1009,'罗贯中',1,NULL,'2001-11-17','50000.00',NULL,10),
(1010,'吴用',3,1006,'2001-09-08','15000.00','0.00',30),
(1011,'沙僧',4,1004,'2007-05-23','11000.00',NULL,20),
(1012,'李逵',4,1006,'2001-12-03','9500.00',NULL,30),
(1013,'小白龙',4,1004,'2001-12-03','30000.00',NULL,20),
(1014,'关羽',4,1007,'2002-01-23','13000.00',NULL,10);
-- 工资等级表
CREATE TABLE salarygrade (
grade INT PRIMARY KEY, -- 级别
losalary INT, -- 最低工资
hisalary INT -- 最高工资
);
-- 添加5个工资等级
INSERT INTO salarygrade(grade,losalary,hisalary) VALUES
(1,7000,12000),
(2,12010,14000),
(3,14010,20000),
(4,20010,30000),
(5,30010,99990);
ER结构:
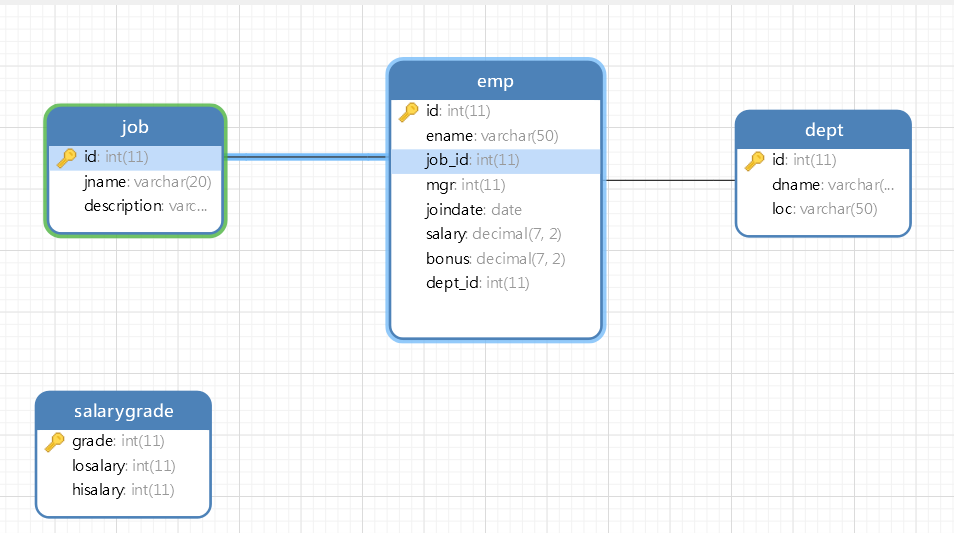

-- 需求:
-- 1.查询所有员工信息。查询员工编号,员工姓名,工资,职务名称,职务描述
/
分析:
1).
员工编号,员工姓名,工资,emp
职务名称,职务描述 job
2).条件:
emp.job_id = job.id
/
SELECT
t1.id,-- 员工编号
t1.ename,-- 员工姓名
t1.salary,-- 工资
t2.jname,-- 职务名称
t2.description -- 职务描述
FROM
emp t1,
job t2
WHERE
t1.job_id = t2.id;
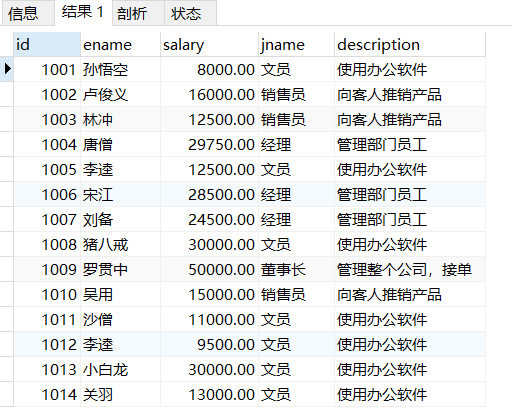
-- 2.查询员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置
/
分析:
1).
员工编号,员工姓名,工资 emp
职务名称,职务描述 job
部门名称,部门位置 dept
2). 条件:
emp.job_id = job.id AND emp.dept_id = dept.id
/
SELECT
t1.id,-- 员工编号
t1.ename,-- 员工姓名
t1.salary,-- 工资
t2.jname,-- 职务名称
t2.description,-- 职务描述
t3.dname,-- 部门名称
t3.loc -- 部门位置
FROM
emp t1,
job t2,
dept t3
WHERE
t1.job_id = t2.id
AND t1.dept_id = t3.id;
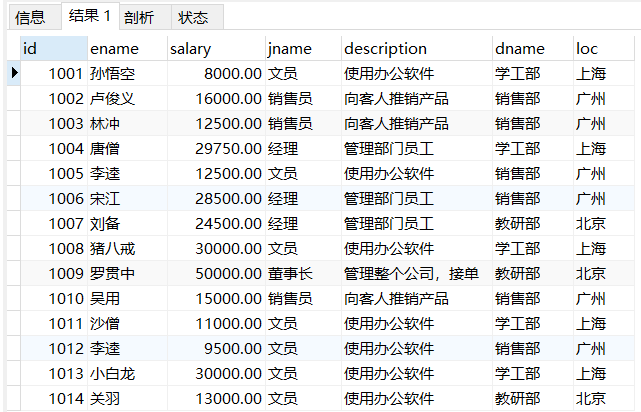
-- 3.查询员工姓名,工资,工资等级
/
分析:
1).
员工姓名,工资 emp
工资等级 salarygrade
2).条件:
emp.salary >= salarygrade.losalary AND emp.salary <= salarygrade.hisalary
或者
emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalary
/
SELECT
t1.ename,
t1.salary,
t2.grade
FROM
emp t1,
salarygrade t2
WHERE
t1.salary BETWEEN t2.losalary
AND t2.hisalary;

-- 4.查询员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级
/
分析:
1.
员工姓名,工资 emp
职务名称,职务描述 job
部门名称,部门位置,dept
工资等级 salarygrade
2. 条件:
emp.job_id = job.id and emp.dept_id = dept.id and emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalary
/
SELECT
t1.ename,
t1.salary,
t2.jname,
t2.description,
t3.dname,
t3.loc,
t4.grade
FROM
emp t1,
job t2,
dept t3,
salarygrade t4
WHERE
t1.job_id = t2.id -- 加上面写的条件
AND t1.dept_id = t3.id -- 条件之间用 AND连接
AND t1.salary BETWEEN t4.losalary
AND t4.hisalary; -- 最低和最高之间,表可以直接拿来用

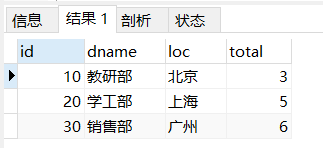
-- 5.查询出部门编号、部门名称、部门位置、部门人数(这个并没有直接给出)
/
分析:
1.
部门编号、部门名称、部门位置 dept
所在部门编号 emp(通过这个来统计人数,作为分组的依据)
2.使用分组查询。按照emp.dept_id完成分组,查询count(id)
3.使用子查询将第2步的查询结果和dept表进行关联查询
/
SELECT
t1.id,
t1.dname,
t1.loc,
t2.total
FROM
dept t1,
( SELECT dept_id, COUNT( id ) total FROM emp GROUP BY dept_id ) t2 -- 中间的子查询是第2步的查询结果
WHERE
t1.id = t2.dept_id;
-- 6.查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询
/*
分析:
1.
姓名 emp
直接上级的姓名 emp(emp表的id 和 mgr 是自关联)
2.条件:
emp.id = emp.mgr
3.
查询左表的所有数据,和 交集数据(使用左外连接查询)
*/
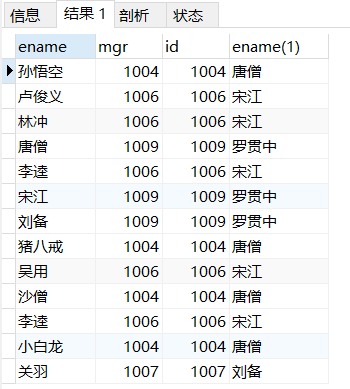
SELECT
t1.ename,
t1.mgr,
t2.id,
t2.ename
FROM
emp t1,
emp t2 -- 自关联其实是两张表的关联,但是emp是一张表,我们通过给emp起别名t1,t2把emp当成两张表操作
SELECT
t1.ename,
t1.mgr,
t2.id,
t2.ename
FROM
emp t1
LEFT JOIN emp t2 ON t1.mgr = t2.id;-- 左外连接查询,意思是把左边(emp t2)的所有数据都输出,和右边(t1.mgr = t2.id)与左边(emp t2)交集数据输出。

SQL的多表查询(Navicat)的更多相关文章
- 数据库SQL的多表查询
数据库 SQL 的多表查询:eg: table1: employees, table2: departments,table3: salary_grades; 一:内连接: 1):等值连接: 把表em ...
- 基于ACCESS和ASP的SQL多个表查询与计算统计代码(一)
近期在写几个关于"Project - Subitem - Task"的管理系统,说是系统还是有点夸大了,基本就是一个多表查询调用和insert.update的数据库操作.仅仅是出现 ...
- MySQL多表查询,Navicat使用,pymysql模块,sql注入问题
一.多表查询 #建表 create table dep( id int, name varchar(20) ); create table emp( id int primary key auto_i ...
- day03 mysql外键 表的三种关系 单表查询 navicat
day03 mysql navicat 一.完整性约束之 外键 foreign key 一个表(关联表: 是从表)设置了外键字段的值, 对应的是另一个表的一条记录(被关联表: 是主 ...
- mysql,SQL标准,多表查询中内连接,外连接,自然连接等详解之查询结果集的笛卡尔积的演化
先附上数据. CREATE TABLE `course` ( `cno` ) NOT NULL, `cname` ) CHARACTER SET utf8 NOT NULL, `ctime` ) NO ...
- oracle 基础SQL语句 多表查询 子查询 分页查询 合并查询 分组查询 group by having order by
select语句学习 . 创建表 create table user(user varchar2(20), id int); . 查看执行某条命令花费的时间 set timing on: . 查看表的 ...
- SQL总结 连表查询
连接查询包括合并.内连接.外连接和交叉连接,如果涉及多表查询,了解这些连接的特点很重要. 只有真正了解它们之间的区别,才能正确使用. 1.Union UNION 操作符用于合并两个或多个 SELECT ...
- sql语句-单表查询
一:单表查询 CREATE TABLE `Score`( `s_id` ), `c_id` ), `s_score` ), PRIMARY KEY(`s_id`,`c_id`) ); ); ); ); ...
- SQL Fundamentals || 多表查询(内连接,外连接(LEFT|RIGHT|FULL OUTER JOIN),自身关联,ON,USING,集合运算UNION)
SQL Fundamentals || Oracle SQL语言 一.多表查询基本语法 在进行多表连接查询的时候,由于数据库内部的处理机制,会产生一些“无用”的数据,而这些数据就称为笛卡尔积. 多表查 ...
- 【SQL】多表查询
多表查询,即查询可以从两个或多个表中获取数据.在Oracle中,有两种类型的连接格式:ANSI SQL连接格式和Oracle特有的连接格式.Oracle建议采用符合ANSI标准的连接格式. 1.内连接 ...
随机推荐
- js实用小函数收集
格式化金额 var val='212312.235423' var rex = /\d{1,3}(?=(\d{3})+$)/g; val.replace(/^(-?)(\d+)((\.\d+)?) ...
- oracle11g rename user导致物化视图失效的处理
在上一篇文章中,已经点到了数据库改名时,引起该schema下物化视图会失效的问题.从表面上看,该物化视图是删也删不掉,那当然就无法重建了.以下是实验过程: Oracle Database 11g En ...
- Future模式的简单实现
/** * 数据接口 */ public interface Data { public String getResult(); } /** * 最终需要使用的数据模型 */ public class ...
- php7类型约束的意义
在PHP7之前,函数和类方法不需要声明变量类型,任何数据都可以被传递和返回,导致几乎大部分的调用操作都要判断返回的数据类型是否合格. 为了解决这个问题,PHP7引入了类型声明. 目前有两类变量可以声明 ...
- POJ 3468 A Simple Problem with Integers(线段树区间修改及查询)
Description You have N integers, A1, A2, ... , AN. You need to deal with two kinds of operations. On ...
- BN和正则化一起使用的后果
就是因为 batch norm 过后, weight 影响没那么重了,所以 l2 weight decay 的效果就不明显了. 证明了L2正则化与归一化相结合时没有正则化效应.相反,正则化会影响权重的 ...
- System.exit(0)和System.exit(1)区别(转)
转:http://www.cnblogs.com/xwdreamer/archive/2011/01/07/2297045.html 1.参考文献 http://hi.baidu.com/accpzh ...
- HTML5: HTML5 Geolocation(地理定位)
ylbtech-HTML5: HTML5 Geolocation(地理定位) 1.返回顶部 1. HTML5 Geolocation(地理定位) HTML5 Geolocation(地理定位)用于定位 ...
- 用scp实现多服务器文件分发
需要安装expect环境 yum install expect -y vi ip.txt #主机地址池 192.168.1.1 192.168.1.2 192.168.3.3 #如果是同一网段也可以不 ...
- 用iptables实现代理上网
环境:内网:eth1:192.168.2.0/24外网:eth0:10.17.0.111用iptables实现NATSNAT:改变数据包的源地址.防火墙会使用外部地址,替换数据包的本地网络地址.这样使 ...