CNN实战篇-手把手教你利用开源数据进行图像识别(基于keras搭建)
我一直强调做深度学习,最好是结合实际的数据上手,参照理论,对知识的掌握才会更加全面。先了解原理,然后找一匹数据来验证,这样会不断加深对理论的理解。
欢迎留言与交流!
数据来源: cifar10 (其他相关的图片的开源数据集下载见 : https://yq.aliyun.com/articles/576274) 文末有全部代码
PS:神经网络系列多用于图像,文字的生成,解析,识别。因此需要掌握充足的开源数据集来验证所学的算法理论。
首先下载好数据后解压。数据的样子如下: data_batch1-5是训练集数据,test_batch是验证集, batches.meta是10个标签的含义

接下来分两个大步骤:
一是数据处理,使其符合模型的输入接口。
二是模型搭建,为了训练出准确有效的模型。
- 数据处理部分:
在python环境下导入需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from keras import backend as K
K.set_image_dim_ordering('tf')
from keras.applications.imagenet_utils import preprocess_input, decode_predictions
from keras.preprocessing import image
之后我们先导入并观察数据,处理成keras 搭建的模型可使用的格式。
导入代码:
# 定义读取方法
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict # 读取CIFAR10数据
cifar={}
# 合并5个训练集
for i in range(5):
cifar1=unpickle('data_batch_'+str(i+1))
if i==0:
cifar[b'data']=cifar1[b'data']
cifar[b'labels']=cifar1[b'labels']
else:
cifar[b'data']=np.vstack([cifar1[b'data'],cifar[b'data']])
cifar[b'labels']=np.hstack([cifar1[b'labels'],cifar[b'labels']])
# label的含义 写在 batches.meta文件里
target_name=unpickle('batches.meta')
cifar[b'label_names']=target_name[b'label_names'] # 测试集读取
cifar_test=unpickle('test_batch')
cifar_test[b'labels']=np.array(cifar_test[b'labels'])
合并之后,我们观察一下数据:
发现是rgb三通道数据拉伸成一维的像素了,即原来为32x32x3的rgb图像,变成了3072个行像素。
如下图:

那么接下来要做的就是还原数据,并看一下打好标签的10类对应的图片长什么样子
# 定义数据格式 将原三通道的一维数据还原至三通道的二维图片格式
blank_image= np.zeros((len(cifar[b'data']),32,32,3), np.uint8) #定义一个rpb图的集合
blank_image2= np.zeros((len(cifar[b'data']),32,32), np.uint8) #定义一个灰度图的集合 稍后写入
for i in range(len(cifar[b'data'])):
blank_image[i] = np.zeros((32,32,3), np.uint8)
blank_image[i][:,:,0]=cifar[b'data'][i][0:1024].reshape(32,32) #前1024个像素还原为32x32并写入到rgb的第一个red通道.
blank_image[i][:,:,1]=cifar[b'data'][i][1024:1024*2].reshape(32,32) #中间1024个像素还原为32x32并写入到rgb的第二个green通道.
blank_image[i][:,:,2]=cifar[b'data'][i][1024*2:1024*3].reshape(32,32) #后1024个像素还原为32x32并写入到rgb的第三个blue通道.
cifar[b'data']=blank_image
cifar[b'data2']=blank_image2
至此测试集还原完毕,可以看到测试集cifar[b'data']变成:
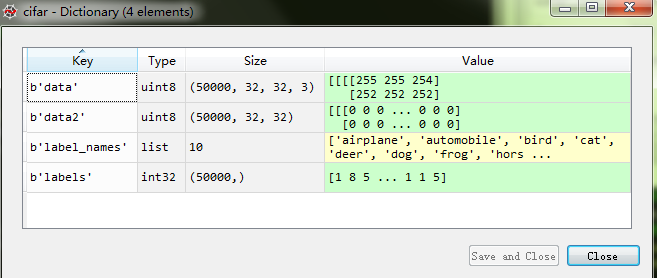
接着同理处理一下验证集,不做详述了:
# 测试集图片数据还原
blank_image= np.zeros((len(cifar_test[b'data']),32,32,3), np.uint8)
blank_image2= np.zeros((len(cifar_test[b'data']),32,32), np.uint8) #定义一个灰度图的集合 稍后写入
for i in range(len(cifar_test[b'data'])):
blank_image[i] = np.zeros((32,32,3), np.uint8)
blank_image[i][:,:,0]=cifar_test[b'data'][i][0:1024].reshape(32,32)
blank_image[i][:,:,1]=cifar_test[b'data'][i][1024:1024*2].reshape(32,32)
blank_image[i][:,:,2]=cifar_test[b'data'][i][1024*2:1024*3].reshape(32,32) # data2处理成黑白 data处理为彩色
cifar_test[b'data']=blank_image
cifar_test[b'data2']=blank_image2
我们选10个种类 各画一张图观察一下:
# 画图关闭
target_list=pd.Series(cifar[b'labels']).drop_duplicates() # labels去重
target_list=target_list.sort_values() # labels排序
target_list=list(target_list.index) # 提取后即为10个标签对应的测试集的位置,找出这些位置的图画出来即可
target_figure=cifar[b'data'][target_list]; for i in range(10):
plt.subplot(2,5,1+i)
plt.imshow(target_figure[i]),plt.axis('off')
数据集的10个label图:

现在到了数据处理的最后一步,定义测试集和训练集,并归一化:
# 训练数据集定义,训练集,测试集归一化
x_train=cifar[b'data'] # 训练集数据
y_train=cifar[b'labels'] # 训练集标签
x_test=cifar_test[b'data'] # 验证集标签
y_test=cifar_test[b'labels'] # 验证集标签 x_train=x_train.reshape(-1,32,32,3) # 训练集格式确保为32x32的rgb三通道格式
x_test=x_test.reshape(-1,32,32,3) # 验证集同理
class_names=cifar[b'label_names']; x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train=x_train/255 #将像素的0到255 归一化至0-1
x_test=x_test/255
至此数据处理部分完毕,等待模型建立后调用即可。
- 模型建立部分:
# 由经典卷积神经模型 VGG16 简化而来
model = tf.keras.models.Sequential([ #此处可简化,但须均维持keras格式或者tf格式\ tf.keras.layers.Conv2D(32,
kernel_size=(3, 3),
padding='same',
activation='relu',
input_shape=(32,32,3)
), #第一层卷积 卷积核为3x3 tf.keras.layers.Conv2D(32,
kernel_size=(3,3),
activation='relu',
padding='same',
data_format='channels_last',
), #第二层卷积 卷积核为3x3 tf.keras.layers.MaxPooling2D(pool_size=(2, 2)), # 池化 缩小
tf.keras.layers.Dropout(0.25), # 防止过拟合 tf.keras.layers.Conv2D(64,
kernel_size=(3, 3),
padding='same',
activation='relu',
input_shape=(32,32,1)
), tf.keras.layers.Conv2D(64,
kernel_size=(3,3),
activation='relu',
padding='same',
data_format='channels_last',
), tf.keras.layers.MaxPooling2D(pool_size=(2, 2)), # 池化缩小
tf.keras.layers.Dropout(0.25), # 防止过拟合 tf.keras.layers.Flatten(), # 将所有特征展平为一维 tf.keras.layers.Dense(512,activation='relu'), # 与一个512节点全链接,激活条件 relu
tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(10,activation=tf.nn.softmax) # 分类专用激活函数 softmax
])
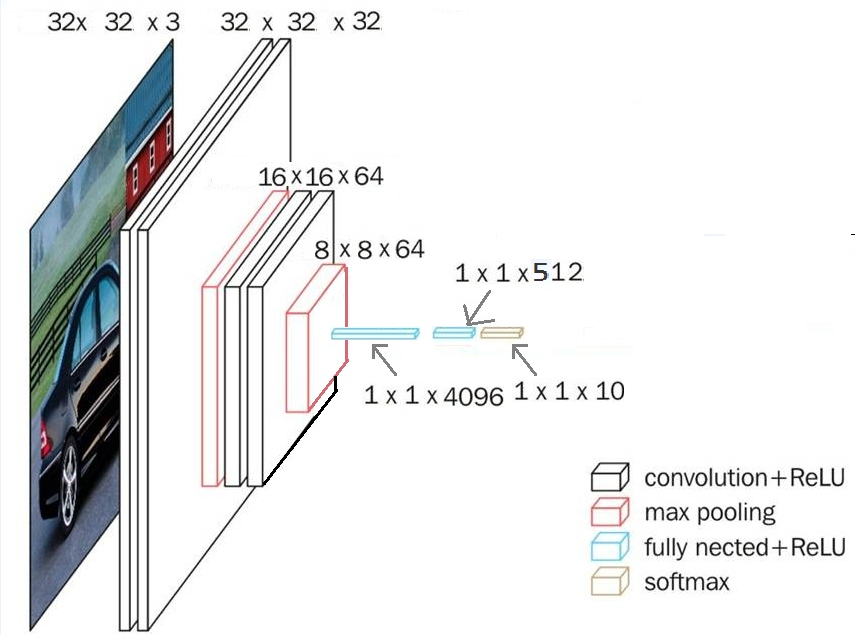
CNN框架解析: 按照步骤来--->
1. 输入rgb图片32x32x3:(一共有50000个,一个一个来)
2. 经过第一次卷积变成了 32x32x32,
(第一步卷积说明: 按照我们参数的设置建立了32个神经元,每个神经元由一个3x3x3的卷积核,也就是32个不同的卷积核卷积后形成了32个不同的特征,因此卷积后将32x32x3大小的图特征维度变成了32。其中每一个神经元有3x3x3+1(bias)个权重。 )
3. 经过第二次卷积变成了 32x32x32,
4. 再经过2x2的步长为2的池化(最大池化法),缩小一倍。
5. 经过第三次卷积变成了 32x32x64,
6. 经过第四次卷积变成了 32x32x64,
7. 再经过2x2的步长为2的池化,缩小一倍
8. 随后拉伸为一维和一个512节点进行全连接,
9. 再与一个10个节点全连接)
这一部分对应下图:
模型搭建好以后就要开始使用它,即模型编译与开始训练:
# 模型编译
model.compile(optimizer='adam',# keras.optimizers.Adadelta()
loss='sparse_categorical_crossentropy',
metrics=['accuracy']) # 模型加载训练集 callbacks=tensorboard 监控
model.fit(x_train, y_train,batch_size=32, epochs=10,verbose=1, validation_data=(x_test, y_test),
callbacks=[keras.callbacks.TensorBoard(log_dir='./tmp/keras_log',write_images=1, histogram_freq=1),
]) #verbos 输出日志 keras.callbacks.EarlyStopping(patience=10, monitor='val_acc') # epochs 数据集所有样本跑过一遍的次数 搭配 batch_size多少个一组进行训练 调整权重
model.evaluate(x_test, y_test,verbose=0)
这一部分的核心是需要了解 优化器,loss函数的不同种类和适用范围。即 model.compile中
optimizer 和 loss 的定义 待训练完毕后 可以加载tensorboard观察模型和训练过程:
# tensorboard 加载监控
import webbrowser
url='http://a1414l039:6006'
webbrowser.open(url, new=0, autoraise=True)
import os
cmd='cd /d '+os.getcwd()+'\\tmp && tensorboard --logdir keras_log'
os.system(cmd)
keras.backend.clear_session()#必要-用以解决重复调用时会话应结束
跑10轮后正确率在验证集和训练集基本维持在78%以上了。
如果需要提高精确度可以适当将全连接层的节点数放大,比如512换成1000.
如果图片大于32x32的话,根据情况拓展卷积的深度。
整体代码附上:
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 27 14:29:54 2019 @author: wenzhe.tian
""" import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from keras import backend as K
K.set_image_dim_ordering('tf')
from keras.applications.imagenet_utils import preprocess_input, decode_predictions
from keras.preprocessing import image # 定义读取方法
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict # 读取CIFAR10数据
cifar={}
# 合并给5个训练集
for i in range(5):
cifar1=unpickle('data_batch_'+str(i+1))
if i==0:
cifar[b'data']=cifar1[b'data']
cifar[b'labels']=cifar1[b'labels']
else:
cifar[b'data']=np.vstack([cifar1[b'data'],cifar[b'data']])
cifar[b'labels']=np.hstack([cifar1[b'labels'],cifar[b'labels']])
# label的含义 写在 batches.meta文件里
target_name=unpickle('batches.meta')
cifar[b'label_names']=target_name[b'label_names'] # 测试集读取
cifar_test=unpickle('test_batch')
cifar_test[b'labels']=np.array(cifar_test[b'labels']) # 定义数据格式 将原三通道的一维数据还原至三通道的二维图片格式
blank_image= np.zeros((len(cifar[b'data']),32,32,3), np.uint8) #定义一个rpb图的集合
blank_image2= np.zeros((len(cifar[b'data']),32,32), np.uint8) #定义一个灰度图的集合 稍后写入
for i in range(len(cifar[b'data'])):
blank_image[i] = np.zeros((32,32,3), np.uint8)
blank_image[i][:,:,0]=cifar[b'data'][i][0:1024].reshape(32,32) #前1024个像素还原为32x32并写入到rgb的第一个red通道.
blank_image[i][:,:,1]=cifar[b'data'][i][1024:1024*2].reshape(32,32) #中间1024个像素还原为32x32并写入到rgb的第二个green通道.
blank_image[i][:,:,2]=cifar[b'data'][i][1024*2:1024*3].reshape(32,32) #后1024个像素还原为32x32并写入到rgb的第三个blue通道.
cifar[b'data']=blank_image
cifar[b'data2']=blank_image2 # 测试集图片数据还原
blank_image= np.zeros((len(cifar_test[b'data']),32,32,3), np.uint8)
blank_image2= np.zeros((len(cifar_test[b'data']),32,32), np.uint8) #定义一个灰度图的集合 稍后写入
for i in range(len(cifar_test[b'data'])):
blank_image[i] = np.zeros((32,32,3), np.uint8)
blank_image[i][:,:,0]=cifar_test[b'data'][i][0:1024].reshape(32,32)
blank_image[i][:,:,1]=cifar_test[b'data'][i][1024:1024*2].reshape(32,32)
blank_image[i][:,:,2]=cifar_test[b'data'][i][1024*2:1024*3].reshape(32,32) # data2处理成黑白 data处理为彩色
cifar_test[b'data']=blank_image
cifar_test[b'data2']=blank_image2 # 画图关闭
#target_list=pd.Series(cifar[b'labels']).drop_duplicates() # labels去重
#target_list=target_list.sort_values() # labels排序
#target_list=list(target_list.index) # 提取后即为10个标签对应的测试集的位置,找出这些位置的图画出来即可
#target_figure=cifar[b'data'][target_list];
#
#for i in range(10):
# plt.subplot(2,5,1+i)
# plt.imshow(target_figure[i]),plt.axis('off') # 转化为灰度预测
def rgb2gray(rgb):
r, g, b = rgb[:,:,0], rgb[:,:,1], rgb[:,:,2]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray for i in range(len(cifar_test[b'data'])):
temp=rgb2gray(cifar_test[b'data'][i])
cifar_test[b'data2'][i]=temp for i in range(len(cifar[b'data'])):
temp=rgb2gray(cifar[b'data'][i])
cifar[b'data2'][i]=temp # 训练数据集定义,训练集,测试集归一化
x_train=cifar[b'data'] # 训练集数据
y_train=cifar[b'labels'] # 训练集标签
x_test=cifar_test[b'data'] # 验证集标签
y_test=cifar_test[b'labels'] # 验证集标签 x_train=x_train.reshape(-1,32,32,3) # 训练集格式确保为32x32的rgb三通道格式
x_test=x_test.reshape(-1,32,32,3) # 验证集同理
class_names=cifar[b'label_names']; x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train=x_train/255 #将像素的0到255 归一化至0-1
x_test=x_test/255 # 由经典卷积神经模型 VGG16 简化而来
model = tf.keras.models.Sequential([ #此处可简化,但须均维持keras格式或者tf格式\ tf.keras.layers.Conv2D(32,
kernel_size=(3, 3),
padding='same',
activation='relu',
input_shape=(32,32,3)
), #第一层卷积 卷积核为3x3 tf.keras.layers.Conv2D(32,
kernel_size=(3,3),
activation='relu',
padding='same',
data_format='channels_last',
), #第二层卷积 卷积核为3x3 tf.keras.layers.MaxPooling2D(pool_size=(2, 2)), # 池化 缩小
tf.keras.layers.Dropout(0.25), # 防止过拟合 tf.keras.layers.Conv2D(64,
kernel_size=(3, 3),
padding='same',
activation='relu',
input_shape=(32,32,1)
), tf.keras.layers.Conv2D(64,
kernel_size=(3,3),
activation='relu',
padding='same',
data_format='channels_last',
), tf.keras.layers.MaxPooling2D(pool_size=(2, 2)), # 池化缩小
tf.keras.layers.Dropout(0.25), # 防止过拟合 tf.keras.layers.Flatten(), # 将所有特征展平为一维 tf.keras.layers.Dense(512,activation='relu'), # 与一个512节点全链接,激活条件 relu
tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(10,activation=tf.nn.softmax) # 分类专用激活函数 softmax
]) # 模型编译
model.compile(optimizer='adam',# keras.optimizers.Adadelta()
loss='sparse_categorical_crossentropy',#tf.keras.losses.categorical_crossentropy会造成单一种类标签
metrics=['accuracy']) # 模型加载训练集 callbacks=tensorboard 监控
model.fit(x_train, y_train,batch_size=32, epochs=10,verbose=1, validation_data=(x_test, y_test),
callbacks=[keras.callbacks.TensorBoard(log_dir='./tmp/keras_log',write_images=1, histogram_freq=1),
]) #verbos 输出日志 keras.callbacks.EarlyStopping(patience=10, monitor='val_acc') # epochs 数据集所有样本跑过一遍的次数 搭配 batch_size多少个一组进行训练 调整权重
model.evaluate(x_test, y_test,verbose=0) # tensorboard 加载监控
import webbrowser
url='http://a1414l039:6006'
webbrowser.open(url, new=0, autoraise=True)
import os
cmd='cd /d '+os.getcwd()+'\\tmp && tensorboard --logdir keras_log'
os.system(cmd) # 经过图像处理后的手机图片预测结果
#plt.figure(figsize=(10,10))
#for i in range(6):
# plt.subplot(3,2,i+1)
# plt.xticks([])
# plt.yticks([])
# plt.grid(False)
# plt.imshow(temp_test_ori[i], cmap=plt.cm.binary)
# plt.xlabel(answer[i]) '''
保存模型 加载权重
''' # Returns a short sequential model
keras.backend.clear_session()#必要-用以解决重复调用时会话应结束
CNN实战篇-手把手教你利用开源数据进行图像识别(基于keras搭建)的更多相关文章
- 新书上线:《Spring Boot+Spring Cloud+Vue+Element项目实战:手把手教你开发权限管理系统》,欢迎大家买回去垫椅子垫桌脚
新书上线 大家好,笔者的新书<Spring Boot+Spring Cloud+Vue+Element项目实战:手把手教你开发权限管理系统>已上线,此书内容充实.材质优良,乃家中必备垫桌脚 ...
- Flutter实战:手把手教你写Flutter Plugin
前言 如果你对移动端有所关注,那么你一定会听说过Flutter.得益于Google,Flutter一经推出便得受到了广泛关注.很多开发者跃跃欲试,国内部分大厂,诸如美团.闲鱼等团队已经开始了Flutt ...
- 手把手教你开发BLE数据透传应用程序
如何开发BLE数据透传应用程序?什么是BLE service和characteristic?如何开发自己的service和characteristic?如何区分ATT和GATT?有没有什么工具可以对B ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- 【转】手把手教你利用Jenkins持续集成iOS项目
前言 众所周知,现在App的竞争已经到了用户体验为王,质量为上的白热化阶段.用户们都是很挑剔的.如果一个公司的推广团队好不容易砸了重金推广了一个APP,好不容易有了一些用户,由于一次线上的bug导致一 ...
- 手把手教你利用Jenkins持续集成iOS项目
前言 众所周知,现在App的竞争已经到了用户体验为王,质量为上的白热化阶段.用户们都是很挑剔的.如果一个公司的推广团队好不容易砸了重金推广了一个APP,好不容易有了一些用户,由于一次线上的bug导致一 ...
- 洗礼灵魂,修炼python(86)--全栈项目实战篇(12)—— 利用socket实现文件传输/并发式聊天
由于本篇博文的项目都很简单,所以本次开个特例,本次解析两个项目,但是都很简单的 项目一:用socket实现文件传输 本项目很简单,作为小项目的预热的,前面刚学完socket,这里马上又利用socket ...
- 手把手教你利用微软的Bot Framework,LUIS,QnA Maker做一个简单的对话机器人
最近由于要参加微软亚洲研究院的夏令营,需要利用微软的服务搭建一个对话Bot,以便对俱乐部的情况进行介绍,所以现学了几天,搭建了一个简单的对话Bot,期间参考了大量的资料,尤其是下面的这篇博客: htt ...
- [swift实战入门]手把手教你编写2048(一)
苹果设备越来越普及,拿着个手机就想捣鼓点啥,于是乎就有了这个系列,会一步一步教大家学习swift编程,学会自己做一个自己的app,github地址:https://github.com/scarlet ...
随机推荐
- Android中@id与@+id区别和sharedUserId属性详解
Android中的组件需要用一个int类型的值来表示,这个值也就是组件标签中的id属性值. id属性只能接受资源类型的值,也就是必须以@开头的值,例如,@id/abc.@+id/xyz等. 如果在@后 ...
- 趣谈linux操作系统笔记-从BIOS到bootloader
BIOS 在主板上,有一个东西叫ROM(Read Only Memory,只读存储器).这和咱们平常说的内存RAM(Read Access Memory,随机存取存储器)不同. 而 ROM 是只读的, ...
- CICD - 持续集成与持续交付
持续集成与持续交付是软件开发和交付中的实践.我们项目中一直在践行持续集成(CI:Continuous Integration):持续交付(CD:Continuous Delivery)未能达到理想状态 ...
- WPF VLC客户端和SDK的简单应用
VLC_SDK编程指南 VLC 是一款自由.开源的跨平台多媒体播放器及框架,可播放大多数多媒体文件,以及 DVD.音频 CD.VCD 及各类流媒体协议.它可以支持目前市面上大多数的视频解码,除了Rea ...
- jdbc 对sqlite的基本操作
1.向数据库中创建表 public void addTable( String dbpath) { //创建表单的sql语句 String createtablesql= " CREATE ...
- Linux监控命令之==>lsof
一.命令说明 lsof 命令的原始功能是列出打开的文件的进程,但LINUX 下,所有的设备都是以文件的行式存在的,所以,lsof 的功能很强大. 二.参数说明 -a :列出打开文件存在的进程 -c&l ...
- 占位图片placehold.it生成
(1)默认:http://www.placehold.it/350x200/cccccc/969696.jpg/&text=loading.. (2)格式:http://www.placeho ...
- python3.5 元组
1.创建元祖 tup1 = ('jenkins','mysql') print(tup1) ssh://root@192.168.0.204:22/usr/bin/python -u /home/pr ...
- java:Springmvc框架3(Validator)
1.springmvcValidator: web.xml: <?xml version="1.0" encoding="UTF-8"?> < ...
- java:LeakFilling(JS,JQ)
1.<a href="javascript:void(0)" onclick="dele();"> a标签不使用链接的时候,必须加javascrip ...