logstash之Filter插件
Logstash之所以强悍的主要原因是filter插件;通过过滤器的各种组合可以得到我们想要的结构化数据
1:grok正则表达式
grok**正则表达式是logstash非常重要的一个环节**;可以通过grok非常方便的将数据拆分和索引
语法格式:
(?<name>pattern)
?<name>表示要取出里面的值,pattern就是正则表达式
例子:收集控制台输入,然后将时间采集出来
input {stdin{}}
filter {
grok {
match => {
"message" => "(?<date>\d+\.\d+)\s+"
}
}
}
output {stdout{codec => rubydebug}}

2:定制化字段,取出想要的字段
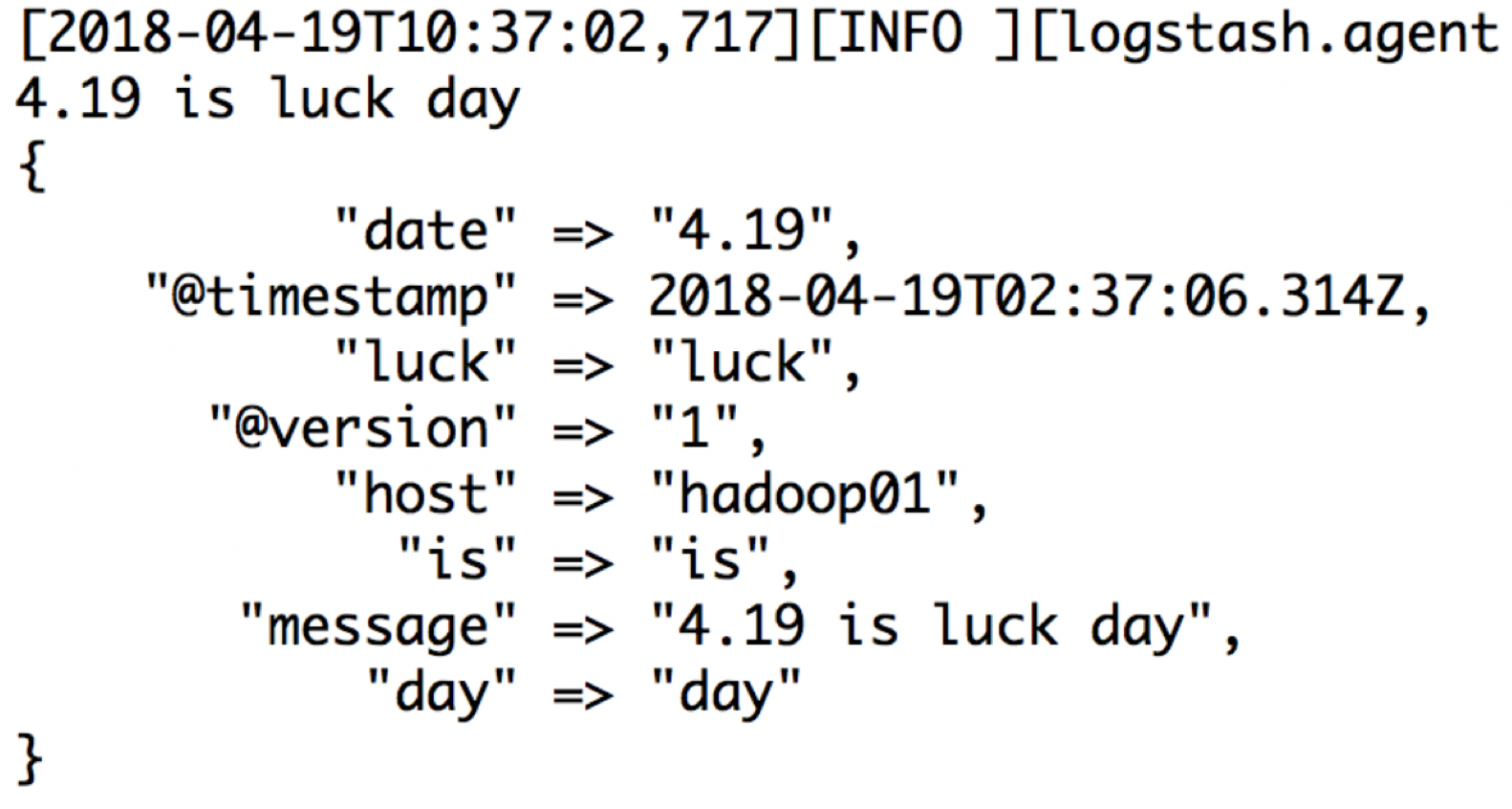
还是按照上面的例子:4.19 is luck day 然后取出每一个字段
input {stdin{}}
filter {
grok {
match => {
"message" => "(?<date>\d+\.\d+)\s+(?<is>\w+)\s+(?<luck>\w+)\s+(?<day>\w+)"
}
}
}
output {stdout{codec => rubydebug}}
3:patterns正则表达式库
默认grok调用的是:/logstash-5.5.2/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns 这个目录下的正则
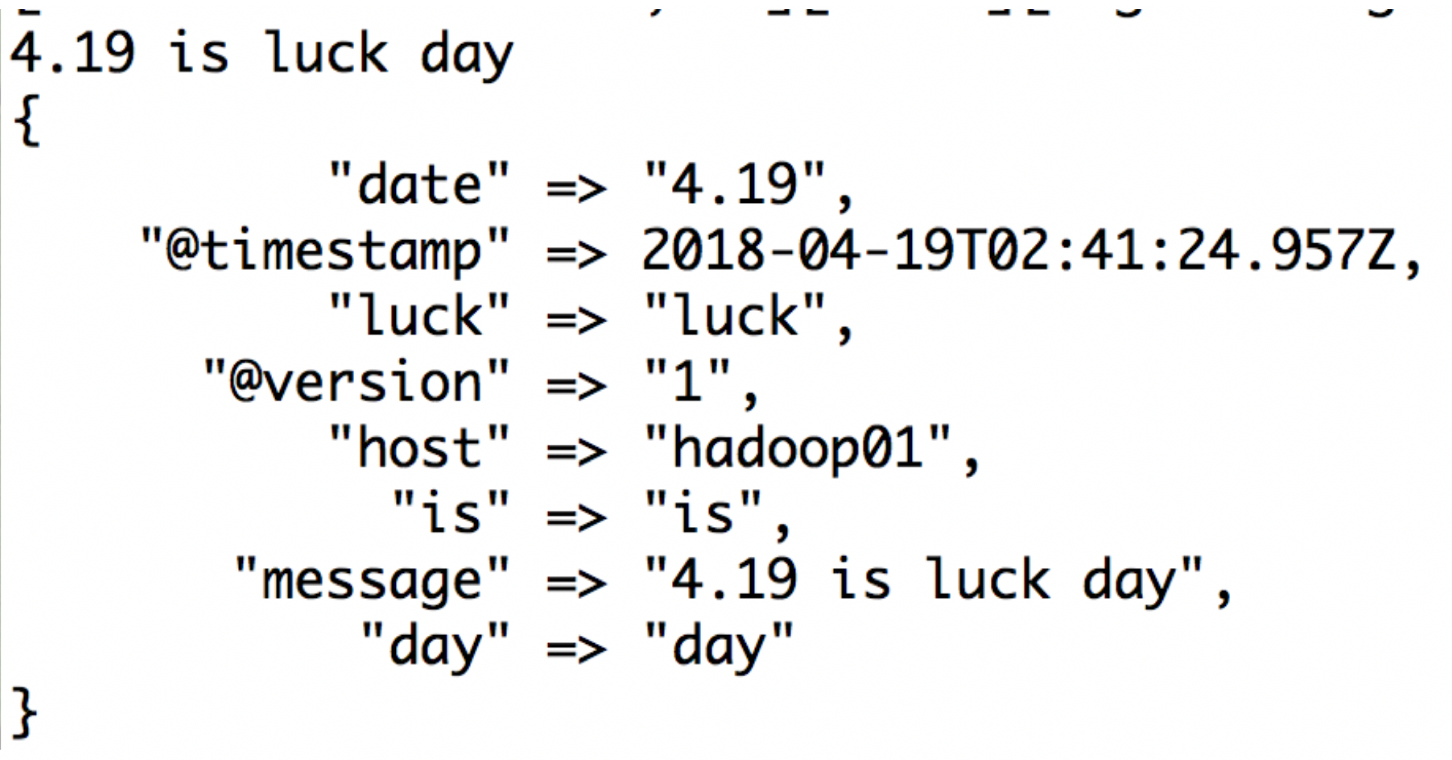
上面的例子,可以这样写:
input {stdin{}}
filter {
grok {
match => {
"message" => "%{NUMBER:date:float} %{WORD:is} %{WORD:luck} %{WORD:day}"
}
}
}
output {stdout{codec => rubydebug}}
结果截图:
4:grok将非结构化数据进行结构化
Nginx打印出的日志一般格式是:
192.168.77.1 - - [10/May/2018:12:12:40 +0800] "GET /plugins/ml/ml.svg HTTP/1.1" 304 0 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36" "-"
nginx这种日志是非格式化的,通常,我们获取到日志后,还要使用mapreduce或者spark做一下清洗操作,就是将非格式化日志编程格式化日志;
在清洗的时候,如果日志的数据量比较大,那么也是需要花费一定的时间的;
所以可以使用logstash的grok功能,将nginx的非格式化数据采集成格式化数据:
安装grok插件: bin/logstash-plugin install logstash-filter-grok
input {stdin{}}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} - - \[%{HTTPDATE:time_local}\] \"(?:%{WORD:request} %{NOTSPACE:request}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}"
}
}
}
output {stdout{codec => rubydebug}}
【注意:】不同的nginx日志格式,应该对应不同的正则
启动:
bin/logstash -f /home/angel/logstash-5.5.2/logstash_conf/filter_4.conf
在控制台输入日志:
192.168.77.1 - - [10/May/2018:12:12:40 +0800] "GET /plugins/ml/ml.svg HTTP/1.1" 304 0 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36" "-"
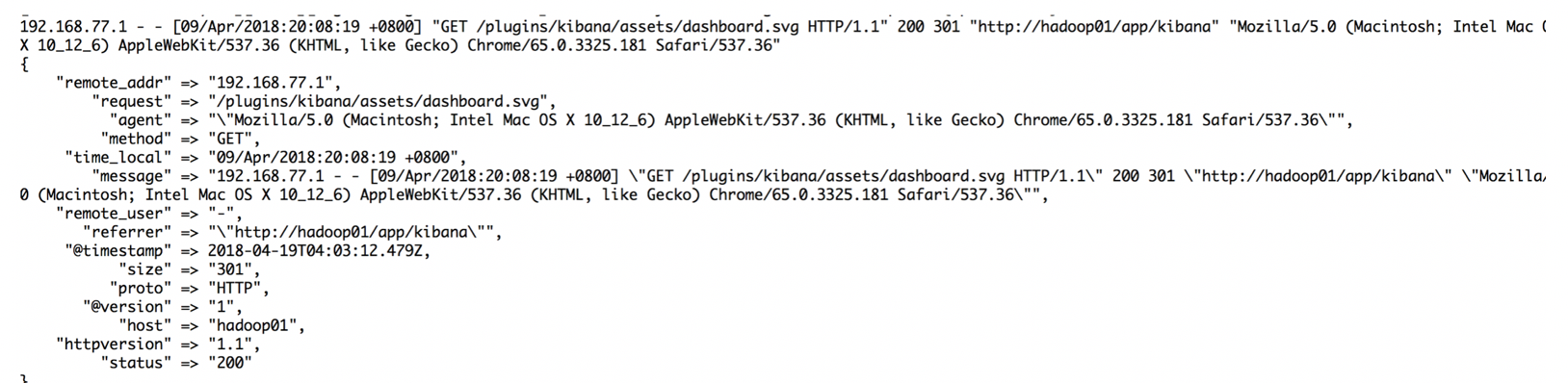
5:geoip查询
上面了解到logstash可以将nginx的非格式化日志进行格式化,那么在nginx的日志中有IP;往往会根据ip定位当前的地理位置,Logstash默认是安装了logstash-filter-geoip插件的
然后在kibana上以高德地图做展示
vim /conf/template/geoip.conf
input {stdin{}}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} - - \[%{HTTPDATE:time_local}\] \"(%{WORD:request} %{NOTSPACE:request}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}"
}
}
geoip{
source => "clientip". #设置解析的ip字段
target => “geoip”. #将解析的geoip保存在一个字段内
}
}
output {stdout{codec => rubydebug}}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/geoip.conf
向控制台输入nginx日志:
119.151.192.24 - - [10/May/2018:12:12:40 +0800] "GET /plugins/ml/ml.svg HTTP/1.1" 304 0 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36" "-"
截图展示:
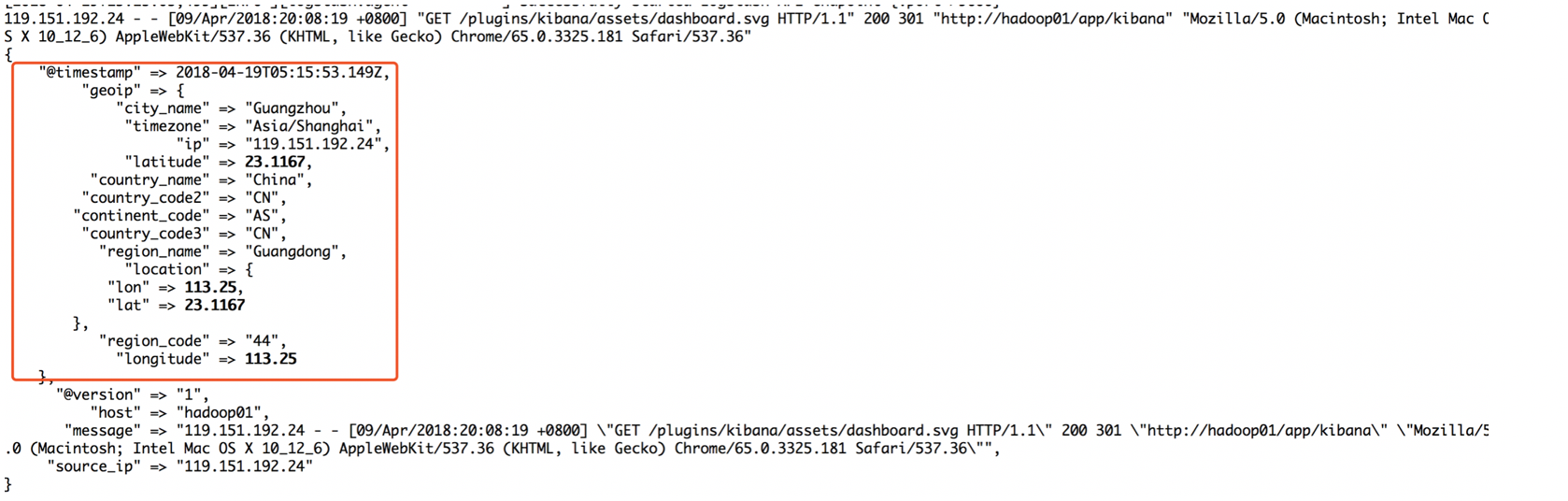
但是有一些国家城市可能会改名字,为了更准确的定位ip的经纬度,可以下载GeoLite2-City.mmdb的ip-经纬度库
下载地址:http://geolite.maxmind.com/download/geoip/database/GeoLite2-City.mmdb.gz(课程内提供)
然后在编写的时候,指定下载的ip-经纬度库,同时,我们会发现返回的信息太多了,有很多不是我们想要的,那么也可以指定哪些是自己想要的:
input {stdin{}}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} - - \[%{HTTPDATE:time_local}\] \"(?:%{WORD:request} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}"
}
}
geoip{
source => "clientip"
database => "/home/angel/logstash-5.5.2/conf/GeoLite2-City.mmdb"
target => "geoip"
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
fields => ["country_name", "region_name", "city_name", "latitude", "longitude"]
# remove_field => [ "[geoip][longitude]", "[geoip][latitude]" ]
}
}
output {stdout{codec => rubydebug}}
6:Key-value拆分
在采集的日志中,往往出现类似于这样的URL:
https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_6858188417104403771%22%7D&n_type=0&p_from=1
类似这种url,字段的信息是按照&拼接而成的,所以需要把这些url进行拆分
vim k_v_split.conf
input {
stdin {
}
}
filter {
kv {
prefix => "key_"
source => "message"
field_split => "&"
value_split => "="
}
}
output {
stdout{codec=>rubydebug}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/k_v_split.conf
向控制台输入:
https://www.baidu.com/s?wd=哈哈,这就是测试&a=1&b=2&c=3&d=4&e=5
结果截图:

logstash之Filter插件的更多相关文章
- Logstash的filter插件介绍
一 官网说明 过滤器插件对事件执行中介处理.通常根据事件的特征有条件地应用过滤器. 以下过滤器插件在下面可用. Plugin Description Github repository aggrega ...
- logstash实战filter插件之grok(收集apache日志)
有些日志(比如apache)不像nginx那样支持json可以使用grok插件 grok利用正则表达式就行匹配拆分 预定义的位置在 /opt/logstash/vendor/bundle/jruby/ ...
- Logstash filter 插件之 grok
本文简单介绍一下 Logstash 的过滤插件 grok. Grok 的主要功能 Grok 是 Logstash 最重要的插件.它可以解析任意文本并把它结构化.因此 Grok 是将非结构化的日志数据解 ...
- logstash的output插件
logstash 的output插件 nginx,logstash和redis在同一台机子上 yum -y install redis,vim /etc/redis.conf 设置bind 0.0.0 ...
- 五十八.Kibana使用 、 Logstash配置扩展插件
1.导入数据 批量导入数据并查看 1.1 导入数据 1) 使用POST方式批量导入数据,数据格式为json,url 编码使用data-binary导入含有index配置的json文件 ]# ...
- 【记录】logstash 的filter 使用
概述 logstash 之所以强大和流行,与其丰富的过滤器插件是分不开的 过滤器提供的并不单单是过滤的功能,还可以对进入过滤器的原始数据进行复杂的逻辑处理,甚至添加独特的新事件到后续流程中 强大的文本 ...
- logstash 过滤filter
logstash过滤器插件filter详解及实例 1.logstash过滤器插件filter 1.1.grok正则捕获 grok是一个十分强大的logstash filter插件,他可以通过正则解 ...
- 使用logstash的grok插件解析springboot日志
使用logstash的grok插件解析springboot日志 一.背景 二.解决思路 三.前置知识 四.实现步骤 1.准备测试数据 2.编写`grok`表达式 3.编写 logstash pipel ...
- logstash的filter之grok
logstash的filter之grokLogstash中的filter可以支持对数据进行解析过滤. grok:支持120多种内置的表达式,有一些简单常用的内容就可以使用内置的表达式进行解析 http ...
随机推荐
- linux项目运行环境搭建
# 命令查看可修改分辨率 xrandr # 选择要修改的分辨率 xrandr -s 1360x768# 删除文件命令 rm -rf 文件名/ # XShell工具进行远程连接了 sudo apt ...
- P1550打井
这是USACO2008年的一道最小生成树题,感谢dzj老师那天教的图论. 要引渠让每一个村庄都可以接到水,然后从某一个村庄到另一个村庄修剪水道要花费w元,并且还要打井(至少一个)(而输入数据也包括了在 ...
- linux源码下载
概要:本文主要介绍ubuntu环境下,内核源码和命令源码的获取方式. 内核源码: 1.最简洁的方式,使用命令:apt-get source linux-$(uname -r).但配置的源服务器中不一定 ...
- Linux端口是否占用的方法
1.netstat或ss命令 netstat -anlp | grep 80 2.lsof命令 这个命令是查看进程占用哪些文件的 lsof -i:80 3.fuser命令 fuser命令和lsof正好 ...
- Day2_数字类型_字符串类型_列表类型
数字类型: 作用:年纪,等级,薪资,身份证号等: 10进制转为2进制,利用bin来执行. 10进制转为8进制,利用oct来执行. 10进制转为16进制,利用hex来执行. #整型age=10 prin ...
- 说说 MicroPython 的项目整体架构
今天来说说 MicroPython 的架构情况,如果有必要我会做一些源码分析的文章供大家参考. 先来认识一下 MicroPython 整体情况,可以从软件的角度上去看待,首先我们拿到 MicroPyt ...
- 用python 获取照片的Exif 信息(获取拍摄设备,时间,地点等信息)
第一步:先安装 pip install exifread 第二部:上代码 import exifread import requests class PhotoExifInfo(): def __in ...
- Linux学习--第十二天--服务、ps、top、pstree、kill、&、jobs、fg、vmstat、dmesg、free、uptime、uname、crontab、ls
服务分类 linux服务分为rpm包默认安装的服务和源码包安装的服务. rpm包默认安装的服务分为独立的服务和基于xinetd服务. 查询已安装的服务 rpm包安装的服务 chkconfig --li ...
- PAT Basic 1071 小赌怡情 (15 分)
常言道“小赌怡情”.这是一个很简单的小游戏:首先由计算机给出第一个整数:然后玩家下注赌第二个整数将会比第一个数大还是小:玩家下注 t 个筹码后,计算机给出第二个数.若玩家猜对了,则系统奖励玩家 t 个 ...
- TCP/IP的网络客户端和服务器端程序
服务器端的过程可以分为以下几个步骤: (1) 初始化套接字的版本信息WSAStartup (2)创建套接字 ,需要两个套接字及客户端和服务器端的套接字 (3)绑定服务器(bind),该函数用于绑定服 ...