爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码
先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制,例如你利用python写了个小爬虫,巴拉巴拉的一劲儿爬人家网页内容,各种下载图片啦,下载视频啥的,然后人家那肯定不让你搞了~,然后尴尬的一幕就出现了,什么呢....防火墙!禁止你在某一段时间登录....给你各种拉黑,那我们有没有什么办法,能特么的不让狗日的拉黑呢,so...我们可以来一些反爬虫的策略,一般来说,我们可以让爬虫爬去网页的内容尽可能的慢一些,或者封装自己的headers,也就是使用浏览器的headers来伪装自己,另外一种,我们可以通过"代理"来实现发爬虫策略,某些网站会对IP地址做限制,例如某个ip地址在一段时间内容访问网站太TMD的快了,要是我,我特么的也不让你玩对吧~,so...我们可以通过伪装ip从而实现继续爬呀爬呀爬,直到爬死小站点~~~渍渍渍!
好,叨逼完前戏了,咱们进入正题~,本次代码是基于scarpy1.4+python3.6.1的环境+pymysql来保存ip代理池的信息以及利用requests中的get方法以及proxies来实现代理功能,so...没TMD模块的,快去准备吧~
代码所需环境:
- python 3.6.1
- scrapy 1.4
- requests
- pymysql
代码分两部分,第一部分为爬取西刺的免费ip代理保存到数据库中,第二部分为从数据库中随机取免费的ip地址,并且判断该ip地址的可用性!!!!!
ok,先来第一部分的获取西刺免费ip代理的代码~
# _*_coding:utf-8_*_
import pymysql
import requests
from scrapy.selector import Selector __author__ = 'demon' conn = pymysql.connect(host='mysqls数据库的ip地址,换成你自己的!', user='登录MySQL的用户名', passwd='密码!', db='xc_proxy(MySQL的数据库名称)', charset='utf8')
cursor = conn.cursor() def crawl_ips():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.115 Safari/537.36"}
for i in range(1, 1001):
url = 'http://www.xicidaili.com/wt/{0}'.format(i)
req = requests.get(url=url, headers=headers)
selector = Selector(text=req.text)
all_trs = selector.xpath('//*[@id="ip_list"]//tr') ip_lists = []
for tr in all_trs[1:]:
speed_str = tr.xpath('td[7]/div/@title').extract()[0]
if speed_str:
speed = float(speed_str.split('秒')[0])
ip = tr.xpath('td[2]/text()').extract()[0]
port = tr.xpath('td[3]/text()').extract()[0]
proxy_type = tr.xpath('td[6]/text()').extract()[0].lower()
ip_lists.append((ip, port, speed, proxy_type)) for ip_info in ip_lists:
cursor.execute(
f"INSERT proxy_ip(ip,port,speed,proxy_type) VALUES('{ip_info[0]}','{ip_info[1]}',{ip_info[2]},"
f"'{ip_info[3]}') "
)
conn.commit()
上面的代码呀....卧槽,好懵逼 好懵逼,那他妈的各种xpath是毛线呀~~哈哈哈哈,自己去学习xpath的知识吧~~,这些玩意,我打字也说不明白,so...既然说不明白,那TMD干嘛浪费口水~,总之一句话,我们最后需要的ip代理是这种格式的{'http': 'http://113.105.146.77:8086'},这里面包含了协议ip地址以及端口号~,so...我们需要在页面中提取这些内容,当然,我还提取的速度,因为有些ip地址的速度太TMD慢了~拿来也并没有什么卵用!算了叨逼叨逼两句吧~,我们爬取前1000页中的免费ip地址~然后在代码中实现了获取当前的免费ip地址,端口,以及协议及速度~,然后把提取到的每页中的我们需要的信息到放到一个元祖中,循环每页中的列表,然后把和免费代理ip相关的信息放到数据库中~,so....说到数据库,怕有些人不知道数据库中字段的类型,放上创建数据库字段的代码吧~
创建数据库及创建存储免费ip代理的表~
- CREATE DATABASE xc_proxy CHARSET='utf8';
- CREATE TABLE proxy_ip (ip VARCHAR(30) NOT NULL PRIMARY KEY,port VARCAHR(5) NOT NULL,speed FLOAT NULL,proxy_type VARCAHR(10) NULL);
- GRANT ALL PRIVILEGES ON xc_proxy.* TO 'root'@'%' IDENTFIED BY '你要给root用户设置的登录密码';
- FLUSH PRIVILEGES;
proxy_ip表创建成功的信息
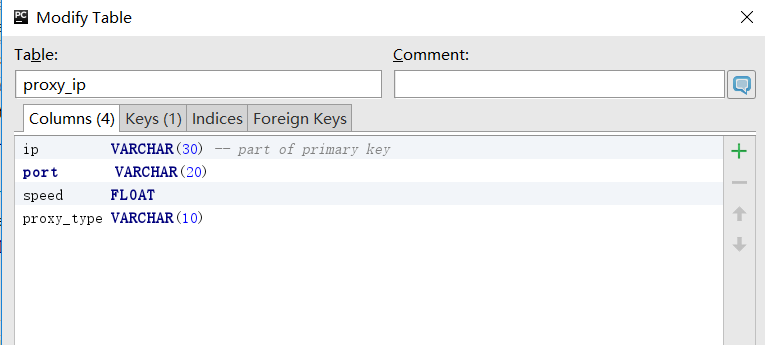
ok,上面就是第一步获取免费的ip地址并保存到数据中~,下面我们要做的就是从数据中随机取ip地址并进行ip地址的可用性测试~
duang duang duang~,第二部分!
class GetIP(object):
def delete(self,ip):
delete_sql = 'DELETE FROM proxy_ip WHERE ip="{0}"'.format(ip)
cursor.execute(delete_sql)
conn.commit()
return True
def valid_ip(self, ip, port, proxy_type):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.115 Safari/537.36"}
try:
proxies = {proxy_type: proxy_type + '://' + ip + ':' + port}
req = requests.get('http://ip.chinaz.com/getip.aspx', headers=headers, proxies=proxies, timeout=3)
except:
print('invalid ip and port')
self.delete(ip)
return False
else:
if 200 <= req.status_code < 300:
# print('{0} effective ip~'.format(proxies))
print(req.text)
return True
else:
print('invalid ip and port')
self.delete(ip)
return False
@property
def get_random_ip(self):
random_ip = 'SELECT proxy_type,ip, port FROM proxy_ip ORDER BY RAND() LIMIT 1;'
cursor.execute(random_ip)
proxy_type, ip, port = cursor.fetchone()
valid_ip = self.valid_ip(ip, port, proxy_type)
if valid_ip:
return {proxy_type: proxy_type + '://' + ip + ':' + port}
else:
return self.get_random_ip
if __name__ == '__main__':
proxy = GetIP()
print(proxy.get_random_ip)
简单的说一下~写了三个方法,分别对应的删除无效的免费ip信息,随机从数据库中取ip地址并做免费ip地址的可用性验证~,实例化类以后,我们调用类中的get_random_ip的方法,从数据中取随机的免费ip地址,并把获取到的ip地址通过拆包的方式分别复制给协议,IP以及端口,然后把这三个参数送给valid_ip方法做验证,如果验证成功,怎返回True,否者先从数据库中删除不能使用的免费ip地址并返回False,如果ip地址不能使用,则继续调用自己,直到ip地址可用未知,ok..就TMD这些东西,有了这些能用免费ip地址,你就可以拿它,嘿嘿嘿嘿~~~
存放的免费IP地址信息以及数据表结构

多说一句~~免费的ip代理相当的不稳定,如果需要稳定的,那就要充值信仰了,毕竟人民币玩家才是真爱!

爬取西刺ip代理池的更多相关文章
- 爬取西刺网代理ip,并把其存放mysql数据库
需求: 获取西刺网代理ip信息,包括ip地址.端口号.ip类型 西刺网:http://www.xicidaili.com/nn/ 那,如何解决这个问题? 分析页面结构和url设计得知: 数据都在本页面 ...
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- python+scrapy 爬取西刺代理ip(一)
转自:https://www.cnblogs.com/lyc642983907/p/10739577.html 第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrap ...
- Python四线程爬取西刺代理
import requests from bs4 import BeautifulSoup import lxml import telnetlib #验证代理的可用性 import pymysql. ...
- 爬取西刺网的免费IP
在写爬虫时,经常需要切换IP,所以很有必要自已在数据维护库中维护一个IP池,这样,就可以在需用的时候随机切换IP,我的方法是爬取西刺网的免费IP,存入数据库中,然后在scrapy 工程中加入tools ...
- 使用XPath爬取西刺代理
因为在Scrapy的使用过程中,提取页面信息使用XPath比较方便,遂成此文. 在b站上看了介绍XPath的:https://www.bilibili.com/video/av30320885?fro ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
随机推荐
- asp.net 在新的页面打开的问题。
在自己写的代码中,有些页面需要在新的页面中打开,基于页面的数据十分繁琐,一直没有找到方法.通过自己不断的测试,找到了一个方法. 后台页面中 for (int j = 0; j < listMod ...
- 新笔记tst
这是测试文章 来自为知笔记(Wiz)
- PhysicsBasedAnimation学习记录
一.前言 1.概述 Google I/O'17推出了许多新的特性,在动画这一块又有新的API供开发者使用,在动画API中引入了DynamicAnimation,开发者可以使用新的API创建更加动态化的 ...
- struts2教程&实例
1.第一个struts2项目 参考官方配置 http://struts.apache.org/getting-started/ github地址:https://github.com/unbeliev ...
- Ubuntu14.04桌面系统允许root登录
首先安装完系统后,在登录界面我们可以看到不允许root账户登录.以普通账户登录系统,打开终端.执行如下命令来设置root密码: sudo passwd root 然后执行命令修改如下配置文件: vi ...
- Linux常用命令及shell技巧
这里列出一些个人在工作中常使用的各种linux命令,每一个不详细讲参数,只写经常用的参数.希望快速获得在linux命令行工作的能力的朋友可以看看.本人一直觉的,不使用linux 图形界面,以xshel ...
- centos7下编译安装mysql
推荐: http://www.cnblogs.com/yunns/p/4877333.html
- (转)OGNL表达式介绍
OGNL是Object-Graph Navigation Language的缩写,它是一种功能强大的表达式语言(Expression Language,简称为EL),通过它简单一致的表达式语法,可以存 ...
- 大数据与Java的关系
随着2017年大数据各种应用的发展,大数据的价值得以充分的发挥,大数据已在企业.社会各个层面都成为重要的手段,数据已成为新的企业战略制高点,也是各个企业争夺的新焦点.那么我们一直在说着的大数据究竟是什 ...
- HDOJ2000-ASCII码排序
Problem Description 输入三个字符后,按各字符的ASCII码从小到大的顺序输出这三个字符. Input 输入数据有多组,每组占一行,有三个字符组成,之间无空格. Output ...