集群配置虚拟主机及部署Hadoop集群碰到的问题
配置集群方案
Ubuntu下的配置apache虚拟主机方案:
对其中的Master节点配置虚拟主机,可以通过Chrome浏览器访问目录。
安装虚拟主机之前,先安装Apache2
sudo apt-get install apache2
再安装php5
sudo apt-get install php5
然后,进入 /etc/apache2/sites-available文件夹,添加”*.conf”文件
往该文件里写入
<VirtualHost *:>
ServerName author.xxx.com
ServerAdmin author.xxx.com
DocumentRoot "/home/author"
<Directory "/home/author">
Options Indexes
AllowOverride all
Order allow,deny
IndexOptions Charset=UTF-
Allow from all
Require all granted
</Directory>
<ifModule dir_module>
DirectoryIndex index.html
</ifModule>
ErrorLog ${APACHE_LOG_DIR}/authors_errors.log
CustomLog ${APACHE_LOG_DIR}/authors_access.log combined
</VirtualHost>
这样的结果是,当Url中访问author.xxx.com时,是有文件夹的树状列表显示的。如果想关掉树状列表显示(为了安全),可以将
Options Indexes
IndexOptions Charset=UTF-
改成
Options FollowSymLinks
这边
paul_errors.log paul_access.log
都位于 /usr/log/apache2中,可以查看apache的日志,用root权限。
配置文件完成之后,则设置的配置文件运行以下命令:
sudo a2ensite xxx.conf
sudo /etc/init.d/apache2 restart
mac下的配置apache虚拟主机方案:
前面基本一致,除了重新启动配置文件不同:
sudo apachectl -v //查看apache版本
sudo apachectl -t //查看虚拟文件配置是否语法正确
sudo apachectl -k restart //重新启动Apache
hadoop部署集群碰到问题(版本为2.7及以上)
该搭建集群具体参数参考本主上一篇文章“机房4台服务器集群网络配置"
在Master上执行下列查看语句之后,出现如下错误
hdfs dfsadmin -report
Configured Capacity: ( B)
Present Capacity: ( B)
DFS Remaining: ( B)
DFS Used: ( B)
DFS Used%: NaN%
Under replicated blocks:
Blocks with corrupt replicas:
Missing blocks:
Missing blocks (with replication factor ):
所有值都为0,且得不到其他slave1,slave2,slave3的反馈消息。
解决方法:
mkdir /home/hadoop/usr/hadoop/conf
新建配置文件夹
文件夹下放入以下配置文件
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!--file system properties-->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.223.1:9000</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml(老版本下job,task配置)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.223.1:9001</value>
</property>
</configuration>
mapred-site.xml(使用hadoop2.2之后的配置)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml(Master下的配置文件)
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager.company.com</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib*/,
$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,
$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,
$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data/1/yarn/local,file:///data/2/yarn/local,file:///data/3/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data/1/yarn/logs,file:///data/2/yarn/logs,file:///data/3/yarn/logs</value>
</property>
<property>
<name>yarn.log.aggregation-enable</name>
<value>true</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://<namenode-host.company.com>:8020/var/log/hadoop-yarn/apps</value>
</property><!-- Site specific YARN configuration properties --></configuration>
为了配合yarn-site.xml中的配置,需要配置
- 创建 yarn.nodemanager.local-dirs 本地目录:
$ sudo mkdir -p /data//yarn/local /data//yarn/local /data//yarn/local /data//yarn/local
- 创建 yarn.nodemanager.log-dirs 本地目录:
$ sudo mkdir -p /data//yarn/logs /data//yarn/logs /data//yarn/logs /data//yarn/logs
将 yarn.nodemanager.local-dirs 目录的所有者配置为 hadoop 用户:
$ sudo chown -R hadoop:hadoop /data//yarn/local /data//yarn/local /data//yarn/local /data//yarn/local
将 yarn.nodemanager.log-dirs 目录的所有者配置为 hadoop 用户:
$ sudo chown -R hadoop:hadoop /data//yarn/logs /data//yarn/logs /data//yarn/logs /data//yarn/logs
yarn-site.xml在slave中的配置,用于与master节点通信,所以IP与端口号都是master节点的:
<?xml version="1.0"?>
<configuration>
<property>
<name>
yarn.nodemanager.aux-services
</name>
<value>
mapreduce_shuffle
</value>
</property>
<property>
<name>
yarn.nodemanager.auxservices.mapreduce.shuffle.class
</name>
<value>
org.apache.hadoop.mapred.ShuffleHandler
</value>
</property>
<property>
<name>
yarn.resourcemanager.address
</name>
<value>
192.168.223.1:8032
</value>
</property>
<property>
<name>
yarn.resourcemanager.scheduler.address
</name>
<value>
192.168.223.1:8030
</value>
</property>
<property>
<name>
yarn.resourcemanager.resource-tracker.address
</name>
<value>
192.168.223.1:8031
</value>
</property>
<property>
<name>
yarn.resourcemanager.hostname
</name>
<value>
192.168.223.1
</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
master
192.168.223.1
slaves(在master节点上的配置文件相应ip地方换上以下相应的ip)
192.168.223.2
192.168.223.3
192.168.223.4
slaves(在slave节点上的配置文件)
localhost
启动方法如下:
hadoop@master:/usr/hadoop$hadoop namenode -format
hadoop@master:/usr/hadoop$sbin/start-all.sh(如果已经启动,则先运行sbin/stop-all.sh)
查看方法(执行以下命令)
hadoop@master:/usr/hadoop$hdfs dfsadmin -report
得到如下结果,则表示安装正确
Configured Capacity: (4.51 TB)
Present Capacity: (4.27 TB)
DFS Remaining: (4.27 TB)
DFS Used: ( KB)
DFS Used%: 0.00%
Under replicated blocks:
Blocks with corrupt replicas:
Missing blocks:
Missing blocks (with replication factor ): -------------------------------------------------
Live datanodes (): Name: 192.168.223.3: (slave3)
Hostname: slave3
Decommission Status : Normal
Configured Capacity: (1.54 TB)
DFS Used: ( KB)
Non DFS Used: (82.39 GB)
DFS Remaining: (1.46 TB)
DFS Used%: 0.00%
DFS Remaining%: 94.79%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Sat Nov :: CST Name: 192.168.223.2: (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: (1.54 TB)
DFS Used: ( KB)
Non DFS Used: (82.40 GB)
DFS Remaining: (1.46 TB)
DFS Used%: 0.00%
DFS Remaining%: 94.79%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Sat Nov :: CST Name: 192.168.223.4: (slave4)
Hostname: slave4
Decommission Status : Normal
Configured Capacity: (1.42 TB)
DFS Used: ( KB)
Non DFS Used: (76.00 GB)
DFS Remaining: (1.35 TB)
DFS Used%: 0.00%
DFS Remaining%: 94.78%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Sat Nov :: CST
创建HDFS文件系统的命令
hadoop fs -mkdir -p /user/[current login user]
创建完HDFS文件系统用户之后,你就可以访问HDFS文件系统,具体对HDFS分布式文件系统的命令请参考以下网址
网页访问hadoop当前性能
http://10.1.8.200:50070/(这边的ip为外网访问master节点的ip,读者自己设置自己的ip)
如下图所示:
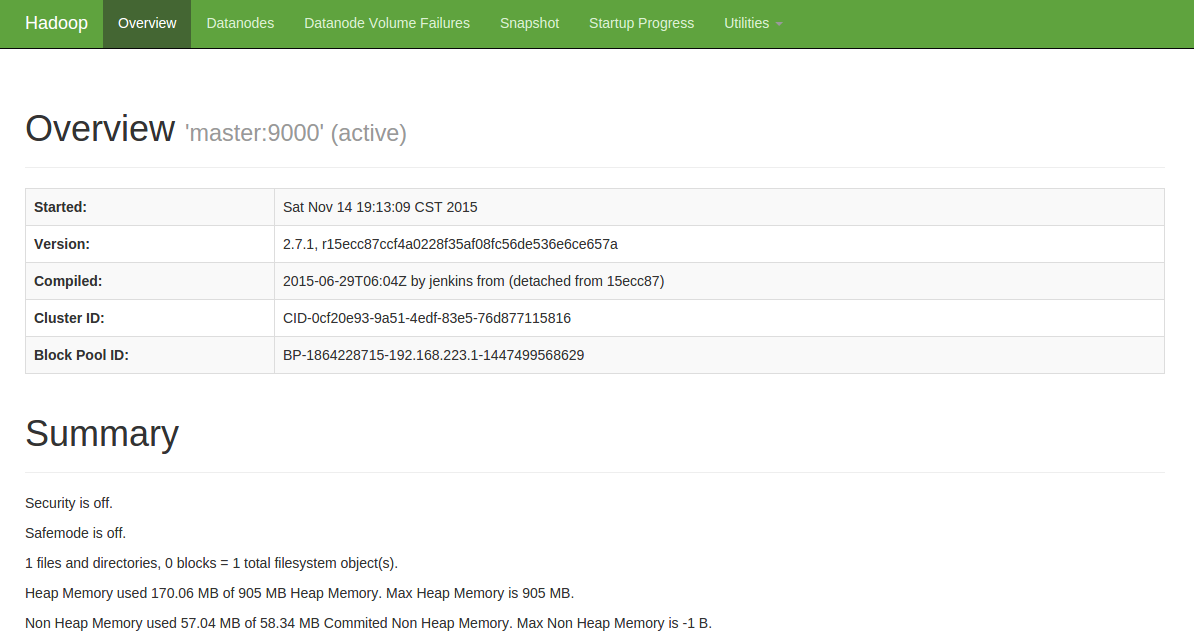
具体安装则参考网址
从 MapReduce 1 (MRv1) 迁移到 MapReduce 2 (MRv2, YARN)
集群配置虚拟主机及部署Hadoop集群碰到的问题的更多相关文章
- 批量部署Hadoop集群环境(1)
批量部署Hadoop集群环境(1) 1. 项目简介: 前言:云火的一塌糊涂,加上自大二就跟随一位教授做大数据项目,所以很早就产生了兴趣,随着知识的积累,虚拟机已经不能满足了,这次在服务器上以生产环境来 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- AMBARI部署HADOOP集群(4)
通过 Ambari 部署 hadoop 集群 1. 打开 http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin 2. 点击 “LAUNCH INS ...
- ambari部署Hadoop集群(2)
准备本地 repository 1. 下载下面的包 wget http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.7.3 ...
- 使用docker部署hadoop集群
最近要在公司里搭建一个hadoop测试集群,于是采用docker来快速部署hadoop集群. 0. 写在前面 网上也已经有很多教程了,但是其中都有不少坑,在此记录一下自己安装的过程. 目标:使用doc ...
- Docker部署Hadoop集群
Docker部署Hadoop集群 2016-09-27 杜亦舒 前几天写了文章"Hadoop 集群搭建"之后,一个朋友留言说希望介绍下如何使用Docker部署,这个建议很好,Doc ...
- 如何部署hadoop集群
假设我们有三台服务器,他们的角色我们做如下划分: 10.96.21.120 master 10.96.21.119 slave1 10.96.21.121 slave2 接下来我们按照这个配置来部署h ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
随机推荐
- java基本类型与Hadoop常见基本类型的对照
Long LongWritable Integer IntWritable Boolean BooleanWritable String Text 1.java类型转化为hadoop基本类型 调用ha ...
- postman安装使用教程---图文讲解
一.安装postman 1,安装包安装 官网下载地址:https://www.getpostman.com 选择好对应的版本下载,下载完后直接安装 2,插件包安装 可以在谷歌的应用商店里面找到,或者在 ...
- NOIP算法总结与复习
NOIP算法总结与复习 (看了看李总的蓝皮书,收获颇多,记下此文,以明志--) (一)数论 1.最大公约数,最小公倍数 2.筛法球素数 3.mod规律公式 4.排列组合数,错排 5.Catalan数 ...
- 第4章 同步控制 Synchronization ----死锁(DeadLock)
Jeffrey Richter 在他所主持的 Win32 Q&A 专栏(Microsoft Systems Journal,1996/07)中曾经提到过,Windows NT 和 Window ...
- ssh (免密码登录、开启服务)
ssh 无密码登录要使用公钥与私钥.linux下可以用用ssh-keygen生成公钥/私钥对,下面我以Unbutun为例.有机器A(192.168.1.155),B(192.168.1.181).现想 ...
- FastDFS 分布式文件系统的安装与使用
跟踪服务器:192.168.152.129 (centos1) 存储服务器:192.168.152.130 (centos2) 环境:CentOS 6.6 用户:root 数据目录:/fastdfs ...
- gulp使用1-入门指南
入门指南 1. 全局安装 gulp: $ npm install --global gulp 或使用cnpm 2. 作为项目的开发依赖(devDependencies)安装: $ npm instal ...
- 【转】Python中实现远程调用(RPC、RMI)简单例子
远程调用使得调用远程服务器的对象.方法的方式就和调用本地对象.方法的方式差不多,因为我们通过网络编程把这些都隐藏起来了.远程调用是分布式系统的基础. 远程调用一般分为两种,远程过程调用(RPC)和远程 ...
- WPF DataGrid Custommization using Style and Template
WPF DataGrid Custommization using Style and Template 代码下载:http://download.csdn.net/detail/wujicai/81 ...
- php 变量 循环关键词以及方法
<?php/* 多行注释 */常用数据类型int string double/float bool变量的定义$a = 123;$b = "123";$c = '456';$d ...