R语言数据分析利器data.table包 —— 数据框结构处理精讲
版权声明:本文为博主原创文章,转载请注明出处
R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快。包括两个方面,一方面是写的快,代码简洁,只要一行命令就可以完成诸多任务,另一方面是处理快,内部处理的步骤进行了程序上的优化,使用多线程,甚至很多函数是使用C写的,大大加快数据运行速度。因此,在对大数据处理上,使用data.table无疑具有极高的效率。这里我们主要讲的是它对数据框结构的快捷处理。
和data.frame的高度兼容
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
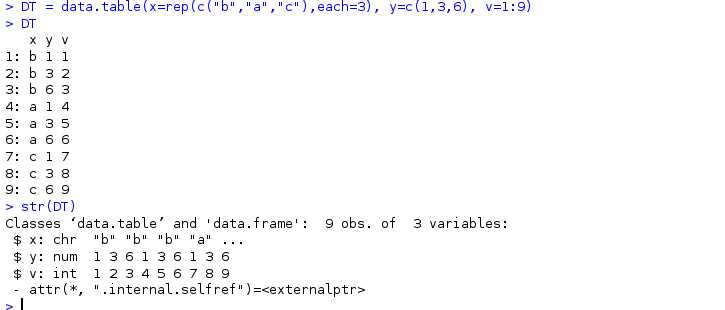
下面DT都是用这个data.table
可见它是属于data.table和data.frame类,并且取列,维数,都可以采用data.frame的方法。
DF = data.frame(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
DF
DT
identical(dim(DT), dim(DF)) # TRUE
identical(DF$a, DT$a) # TRUE
is.list(DF) # TRUE
is.list(DT) # TRUE
is.data.frame(DT) # TRUE
不过data.frame默认将非数字转化为因子;而data.table 会将非数字转化为字符

data.table数据框也可使用dplyr包的管道,这里不作阐述。
data.table常用的函数
as.data.table(x, keep.rownames=FALSE, ...) 将一个R对象转化为data.table,R可以时矢量,列表,data.frame等,keep.rownames决定是否保留行名或者列表名,默认FALSE,如果TRUE,将行名存在"rn"行中,keep.rownames="id",行名保存在"id"行中。
DF = data.frame(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9) #新建data.frame DF
DT=as.data.table(DF,keep.rownames=TRUE)

setDT(x, keep.rownames=FALSE, key=NULL, check.names=FALSE) 把一个R对象转化为data.table,比as.data.table快,因为以传地址的方式直接修改原对象,没有拷贝
copy(x) 深度拷贝一个data.table,x即data.table对象。data.table为了加快速度,会直接在对象地址修改,因此如果需要就要在修改前copy,直接修改的命令有:=添加一列,set系列命令比如下面提到的setattr,setnames,setorder等;当使用dt_names = names(DT)的时候,修改dt_names会修改原data.table的列名,如果不想被修改,这个时候应copy原data.table,也可以使用dt_names <- copy(names(DT))直接copy列名,这样不必copy整个data.table。
kDT=copy(DT) #kDT时DT的一个copy
**rowid(..., prefix=NULL) ** 产生unique的id,prefix参数在id前面加前缀
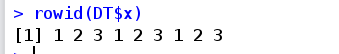
setattr 设置DT的属性,setattr(x,name,value) x时data.table,list或者data.frame,而name时属性名,value时属性值,setnames(x,old,new),设置x的列名,old是旧列名或者数字位置,new是新列名

setcolorder(x,neworder) 重新安排列的顺序,neworder字符矢量或者行数

set(DT,rownum,colnum,value)直接修改某个位置的值,rownum行号,colnum,列号,行号列号推荐使用整型,保证最快速度,方法是在数字后面加L,比如1L,value是需要赋予的值。比:=还快,通常和循环配合使用

至于这个操作究竟有多快,可以看一下(参照官方manual的命令),另外个人觉得最牛的三个函数是set(),fread,和fwrite

fread
fread(input, sep="auto", sep2="auto", nrows=-1L, header="auto", na.strings="NA", file,
stringsAsFactors=FALSE, verbose=getOption("datatable.verbose"), autostart=1L,
skip=0L, select=NULL, drop=NULL, colClasses=NULL,
integer64=getOption("datatable.integer64"),
# default: "integer64"
dec=if (sep!=".") "." else ",", col.names,
check.names=FALSE, encoding="unknown", quote="\"",
strip.white=TRUE, fill=FALSE, blank.lines.skip=FALSE, key=NULL,
showProgress=getOption("datatable.showProgress"), # default: TRUE
data.table=getOption("datatable.fread.datatable") # default: TRUE
)
input输入的文件,或者字符串(至少有一个"\n");
sep列之间的分隔符;
sep2,分隔符内再分隔的分隔符,功能还没有应用;
nrow,读取的行数,默认-l全部,nrow=0仅仅返回列名;
header第一行是否是列名;
na.strings,对NA的解释;
file文件路径,再确保没有执行shell命令时很有用,也可以在input参数输入;
stringsASFactors是否转化字符串为因子,
verbose,是否交互和报告运行时间;
autostart,机器可读这个区域任何行号,默认1L,如果这行是空,就读下一行;
skip跳过读取的行数,为1则从第二行开始读,设置了这个选项,就会自动忽略autostart选项,也可以是一个字符,skip="string",那么会从包含该字符的行开始读;
select,需要保留的列名或者列号,不要其它的;
drop,需要取掉的列名或者列号,要其它的;
colClasses,类字符矢量,用于罕见的覆盖而不是常规使用,只会使一列变为更高的类型,不能降低类型;
integer64,读如64位的整型数;
dec,小数分隔符,默认"."不然就是","
col.names,给列名,默认试用header或者探测到的,不然就是V+列号;
encoding,默认"unknown",其它可能"UTF-8"或者"Latin-1",不是用来重新编码的,而是允许处理的字符串在本机编码;
quote,默认""",如果以双引开头,fread强有力的处理里面的引号,如果失败了就会用其它尝试,如果设置quote="",默认引号不可用
strip.white,默认TRUE,删除结尾空白符,如果FALSE,只取掉header的结尾空白符;
fill,默认FALSE,如果TRUE,不等长的区域可以自动填上,利于文件顺利读入;
blank.lines.skip,默认FALSE,如果TRUE,跳过空白行
key,设置key,用一个或多个列名,会传递给setkey
showProgress,TRUE会显示脚本进程,R层次的C代码
data.table,TRUE返回data.table,FALSE返回data.frame
实例如下,1.8GB的数据读入94秒,可见读入文件速度非常快,

fwrite
fwrite(x, file = "", append = FALSE, quote = "auto",
sep = ",", sep2 = c("","|",""),
eol = if (.Platform$OS.type=="windows") "\r\n" else "\n",
na = "", dec = ".", row.names = FALSE, col.names = TRUE,
qmethod = c("double","escape"),
logicalAsInt = FALSE, dateTimeAs = c("ISO","squash","epoch","write.csv"),
buffMB = 8L, nThread = getDTthreads(),
showProgress = getOption("datatable.showProgress"),
verbose = getOption("datatable.verbose"))
x,具有相同长度的列表,比如data.frame和data.table等;
file,输出文件名,""意味着直接输出到操作台;
append,如果TRUE,在原文件的后面添加;
quote,如果"auto",因子和列名只有在他们需要的时候才会被加上双引号,例如该部分包括分隔符,或者以"\n"结尾的一行,或者双引号它自己,如果FALSE,那么区域不会加上双引号,如果TRUE,就像写入CSV文件一样,除了数字,其它都加上双引号;
sep,列之间的分隔符;
sep2,对于是list的一列,写出去时list成员间以sep2分隔,它们是处于一列之内,然后内部再用字符分开;
eol,行分隔符,默认Windows是"\r\n",其它的是"\n";
na,na值的表示,默认"";
dec,小数点的表示,默认".";
row.names,是否写出行名,因为data.table没有行名,所以默认FALSE;
col.names ,是否写出列名,默认TRUE,如果没有定义,并且append=TRUE和文件存在,那么就会默认使用FALSE;
qmethod,怎样处理双引号,"escape",类似于C风格,用反斜杠逃避双引,“double",默认,双引号成对;
logicalAsInt,逻辑值作为数字写出还是作为FALSE和TRUE写出;
dateTimeAS, 决定 Date/IDate,ITime和POSIXct的写出,"ISO"默认,-2016-09-12, 18:12:16和2016-09-12T18:12:16.999999Z;"squash",-20160912,181216和20160912181216999;"epoch",-17056,65536和1473703936;"write.csv",就像write.csv一样写入时间,仅仅对POSIXct有影响,as.character将digits.secs转化字符并通过R内部UTC转回本地时间。前面三个选项都是用新的特定C代码写的,较快
buffMB,每个核心给的缓冲大小,在1到1024之间,默认80MB
nThread,用的核心数。
showProgress,在工作台显示进程,当用file==""时,自动忽略此参数
verbose,是否交互和报告时间

data.table数据框结构处理语法
data.table[ i , j , by]
i 决定显示的行,可以是整型,可以是字符,可以是表达式,j 是对数据框进行求值,决定显示的列,by对数据进行指定分组,除了by ,也可以添加其它的一系列参数:
keyby,with,nomatch,mult,rollollends,which,.SDcols,on。
i 决定显示的行
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9) #新建data.table对象DT
DT[2] #取第二行
DT[2:3] #取第二到第三行
DT[order(x)] #将DT按照X列排序,简化操作,另外排序也可以setkey(DT,x),出来的DT就已经是按照x列排序的了。用haskey(DT)判断DT是否已经设置了key,可以设置多个列作为key
DT[y>2] # DT$y>2的行
DT[!2:4] #除了2到4行剩余的行
DT["a",on="x"] #on 参数,DT[D,on=c("x","y")]取DT上"x","y"列上与D上“x"、"y"的列相关联的行,与D进行merge。比如此例取出DT 中 X 列为"a"的行,和"a"进行merge。on参数的第一列必须是DT的第一列
DT[.("a"), on="x"] #和上面一样.()有类似与c()的作用
DT["a", on=.(x)] #和上面一样
DT[x=="a"] # 和上面一样,和使用on一样,都是使用二分查找法,所以它们速度比用data.frame的快。也可以用setkey之后的DT,输入DT["a"]或者DT["a",on=.(x)]如果有几个key的话推荐用on
DT[x!="b" | y!=3] #x列不等于"b"或者y列不等于3的行
DT[.("b", 3), on=.(x, v)] #取DT的x,v列上x="b",v=3的行
j 对数据框进行求值输出
j 参数对数据进行运算,比如sum,max,min,tail等基本函数,输出基本函数的计算结果,还可以用n输出第n列,.N(总列数,直接在j输入.N取最后一列),:=(直接在data.table上添加列,没有copy过程,所以快,有需要的话注意备份),.SD输出子集,.SD[n]输出子集的第n列,DT[,.(a = .(), b = .())] 输出一个a、b列的数据框,.()就是要输入的a、b列的内容,还可以将一系列处理放入大括号,如{tmp <- mean(y);.(a = a-tmp, b = b-tmp)}
DT[,y] #返回y列,矢量
DT[,.(y)] #返回y列,返回data.table
DT[, sum(y)] #对y列求和
DT[, .(sv=sum(v))] #对y列求和,输出sv列,列中的内容就是sum(v)
DT[, .(sum(y)), by=x] # 对x列进行分组后对各分组y列求总和
DT[, sum(y), keyby=x] #对x列进行分组后对各分组y列求和,并且结果按照x排序
DT[, sum(y), by=x][order(x)] #和上面一样,采取data.table的链接符合表达式
DT[v>1, sum(y), by=v] #对v列进行分组后,取各组中v>1的行出来,各组分别对定义的行中的y求和
DT[, .N, by=x] #用by对DT 用x分组后,取每个分组的总行数
DT[, .SD, .SDcols=x:y] #用.SDcols 定义SubDadaColums(子列数据),这里取出x到之间的列作为子集,然后.SD 输出所有子集
DT[2:5, cat(y, "\n")] #直接在j 用cat函数,输出2到5列的y值
DT[, plot(a,b), by=x] #直接在j用plot函数画图,对于每个x的分组画一张图
DT[, m:=mean(v), by=x] #对DT按x列分组,直接在DT上再添加一列m,m的内容是mean(v),直接修改并且不输出到屏幕上
DT[, m:=mean(v), by=x] [] #加[]将结果输出到屏幕上
DT[,c("m","n"):=list(mean(v),min(v)), by=x][] # 按x分组后同时添加m,n 两列,内容是分别是mean(v)和min(v),并且输出到屏幕
DT[, `:=`(m=mean(v),n=min(v)),by=x][] #内容和上面一样,另外的写法
DT[,.(seq = min(y):max(v)), by=x] #输出seq列,内容是min(a)到max(b)
DT[, c(.(y=max(y)), lapply(.SD, min)), by=x, .SDcols=y:v] #对DT取y:v之间的列,按x分组,输出max(y),对y到v之间的列每列求最小值输出。
by,on,with等参数
by 对数据进行分组

on DT[D,on=c("x","y")]取DT上"x","y"列上与D上"x","y”列相关联的行,并与D进行merge

DT[X, on="x"] #左联接
X[DT, on="x"] #右联接
DT[X, on="x", nomatch=0] #内联接,nomatch=0表示不返回不匹配的行,nomatch=NA表示以NA返回不匹配的值
with 默认是TRUE,列名能够当作变量使用,即x相当于DT$"x",当是FALSE时,列名仅仅作为字符串,可以用传统data.frame方法并且返回data.table,x[, cols, with=FALSE] 和x[, .SD, .SDcols=cols]一样


mult 当有i 中匹配到的有多行时,mult控制返回的行,"all"返回全部(默认),"first",返回第一行,"last"返回最后一行

roll 当i中全部行匹配只有某一行不匹配时,填充该行空白,+Inf(或者TRUE)用上一行的值填充,-Inf用下一行的值填充,输入某数字时,表示能够填充的距离,near用最近的行填充
rollends 填充首尾不匹配的行,TRUE填充,FALSE不填充,与roll一同使用


which TRUE返回匹配的行号,NA返回不匹配的行号,默认FALSE返回匹配的行
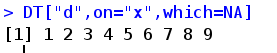
.SDcols 取特定的列,然后.SD就包括了页写选定的特定列,可以对这些子集应用函数处理

allow.cartesian FALSE防止结果超出nrow(x)+nrow(i)行,常常因为i中有重复的列而超出。这里的cartesian和传统上的cartesian不一样。
参考文献
data.table包manual:https://cran.r-project.org/web/packages/data.table/data.table.pdf
R语言数据分析利器data.table包 —— 数据框结构处理精讲的更多相关文章
- R语言数据分析利器data.table包—数据框结构处理精讲
R语言数据分析利器data.table包-数据框结构处理精讲 R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快.包括两个方面,一方面是写的快,代 ...
- R语言学习 第三篇:数据框
数据框(data.frame)是最常用的数据结构,用于存储二维表(即关系表)的数据,每一列存储的数据类型必须相同,不同数据列的数据类型可以相同,也可以不同,但是每列的行数(长度)必须相同.数据框的每列 ...
- R语言data.table包fread读取数据
R语言处理大规模数据速度不算快,通过安装其他包比如data.table可以提升读取处理速度. 案例,分别用read.csv和data.table包的fread函数读取一个1.67万行.230列的表格数 ...
- R︱高效数据操作——data.table包(实战心得、dplyr对比、key灵活用法、数据合并)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于业务中接触的数据量很大,于是不得不转战开始 ...
- R语言数据分析系列之五
R语言数据分析系列之五 -- by comaple.zhang 本节来讨论一下R语言的基本图形展示,先来看一张效果图吧. watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi ...
- R语言数据分析系列六
R语言数据分析系列六 -- by comaple.zhang 上一节讲了R语言作图,本节来讲讲当你拿到一个数据集的时候怎样下手分析,数据分析的第一步.探索性数据分析. 统计量,即统计学里面关注的数据集 ...
- R语言入门级实例——用igragh包分析社群
R语言入门级实例——用igragh包分析社群 引入—— 本文的主要目的是初步实现R的igraph包的基础功能,包括绘制关系网络图(social relationship).利用算法进行社群发现(com ...
- data.table包简介
data.table包主要特色是:设置keys.快速分组和滚得时序的快速合并.data.table主要通过二元检索法大大提高数据操作的效率,同时它也兼容适用于data.frame的向量检索法. req ...
- 使用 data.table 包操作数据
在第一节中,我们回顾了许多用于操作数据框的内置函数.然后,了解了 sqldf 扩展包,它使得简单的数据查询和统计变得更简便.然而,两种方法都有各自的局限性.使用内置函数可能既繁琐又缓慢,而相对于各式各 ...
随机推荐
- Linux 菜鸟学习笔记--系统分区
硬盘分区 常识 主分区:最多只能有4个 扩展分区:用于突破主分区最多4个的限制 *最多只能有1个 *主分区+扩展分区最多有4个 *不能写入数据,只能包含逻辑分区 逻辑分区 格式化:实际是写入文件系统, ...
- spring 注解配置
要在spring mvc中使用注解需要在*-servlet.xml文件中添加 <mvc:annotation-driver />配置 这个配置会创建DefaultAnnotationHan ...
- c#类,接口,结构,抽象类介绍 以及抽象和接口的比较
c#中的类是最常见的实际上就是对某种类型的对象定义变量和方法的原型. 结构是值类型,而类是引用类型. 1.与类不同,结构的实例化可以不使用 new 运算符.结构可以声明构造函数,但它们必须带参数. 2 ...
- 手动加支付宝遇到的错误--iOS
前言 之前调通了支付宝demo,开始往自己工程拖东西吧,我为什么觉得我可能把所以的问题都遇到了呢+_+,赶紧把问题记录下来 不然下次弄还费劲,加一句,要不真的用ping++吧
- js-tab选项卡
说道tab选项卡,顾名思义,就是切换不同内容分类,想必学过前端的都知道,tab有很多方法可以实现,最近刚跟师傅学了一种,感觉很简便,很实用哦. 一.先看一下结果 二.可以根据图来布局,首先上面标 ...
- android 下Protobuff框架性能测试结果
android 下Protobuff常用的框架有三个: protobuff自身, square出的wire , protostuff 由于protobuff会为每个属性生成大量不常用的方法,当程序比 ...
- C# 获取文件MD5与SHA1
之前刚开始学习编程的时候,总想着自己写一些小软件小工具. 而这个就是经典的文件MD5校验,顺便加上了一个SHA1. 在网络上下载一些东西时,会有作者提供MD5值. 它的作用就在于我们可以在下载该软件后 ...
- Java之路——名词解释(一)
一.开篇 许多人在初接触Java的时候,都会被各种Java的英文缩写名词给弄得头晕脑胀.看一个技术,内容里又会有一堆其他的技术名词,看了半天不知所云.尝试去查一下这些名词的解释,除了非常学术性的解释之 ...
- C# 6 与 .NET Core 1.0 高级编程 - 40 ASP.NET Core(下)
译文,个人原创,转载请注明出处(C# 6 与 .NET Core 1.0 高级编程 - 40 章 ASP.NET Core(下)),不对的地方欢迎指出与交流. 章节出自<Professiona ...
- 【转】Java 并发:Executors 和线程池
原文地址: http://baptiste-wicht.com/posts/2010/09/java-concurrency-part-7-executors-and-thread-pools.htm ...