MXNet之ps-lite及parameter server原理
MXNet之ps-lite及parameter server原理
ps-lite框架是DMLC组自行实现的parameter server通信框架,是DMLC其他项目的核心,例如其深度学习框架MXNET的分布式训练就依赖ps-lite的实现。
parameter server原理
在机器学习和深度学习领域,分布式的优化已经成了一种先决条件,因为单机已经解决不了目前快速增长的数据与参数带来的问题。现实中,训练数据的数量可能达到1TB到1PB之间,而训练过程中的参数可能会达到\(10^9\)到\(10^{12}\)。而往往这些模型的参数需要被所有的worker节点频繁的访问,这就会带来很多问题和挑战:
- 访问这些巨量的参数,需要大量的网络带宽支持;
- 很多机器学习算法都是连续型的,只有上一次迭代完成(各个worker都完成)之后,才能进行下一次迭代,这就导致了如果机器之间性能差距大(木桶理论),就会造成性能的极大损失;
- 在分布式中,容错能力是非常重要的。很多情况下,算法都是部署到云环境中的(这种环境下,机器是不可靠的,并且job也是有可能被抢占的)。
分布式系统中的同步与异步机制

图1 在同步的机制下,系统运行的时间是由最慢的worker节点与通信时间决定的
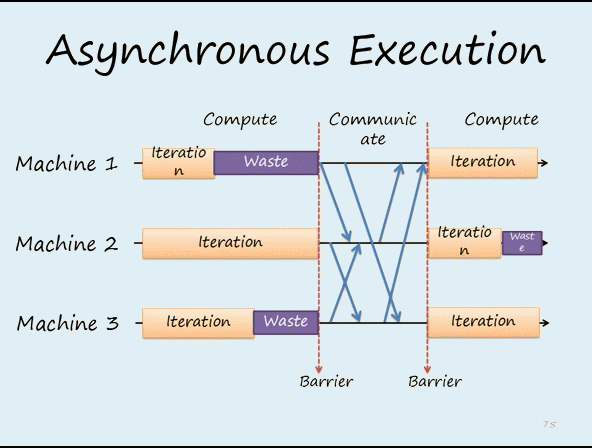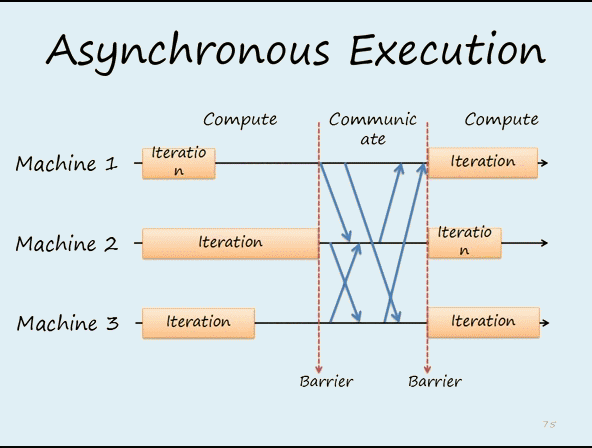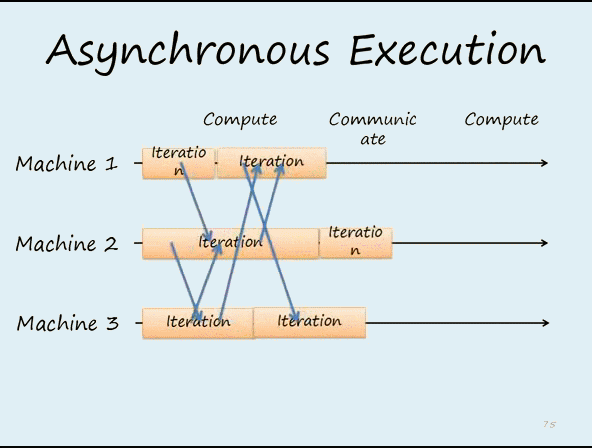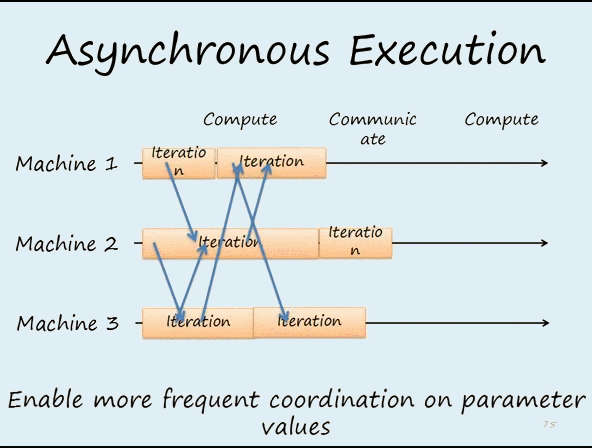
图2 在异步的机制下,每个worker不能等待其它workers完成再运行下一次迭代。这样可以提高效率,但从迭代次数的角度来看,会减慢收敛的速度。
parameter server架构
在parameter server中,每个 server 实际上都只负责分到的部分参数(servers共同维持一个全局的共享参数),而每个 work 也只分到部分数据和处理任务。
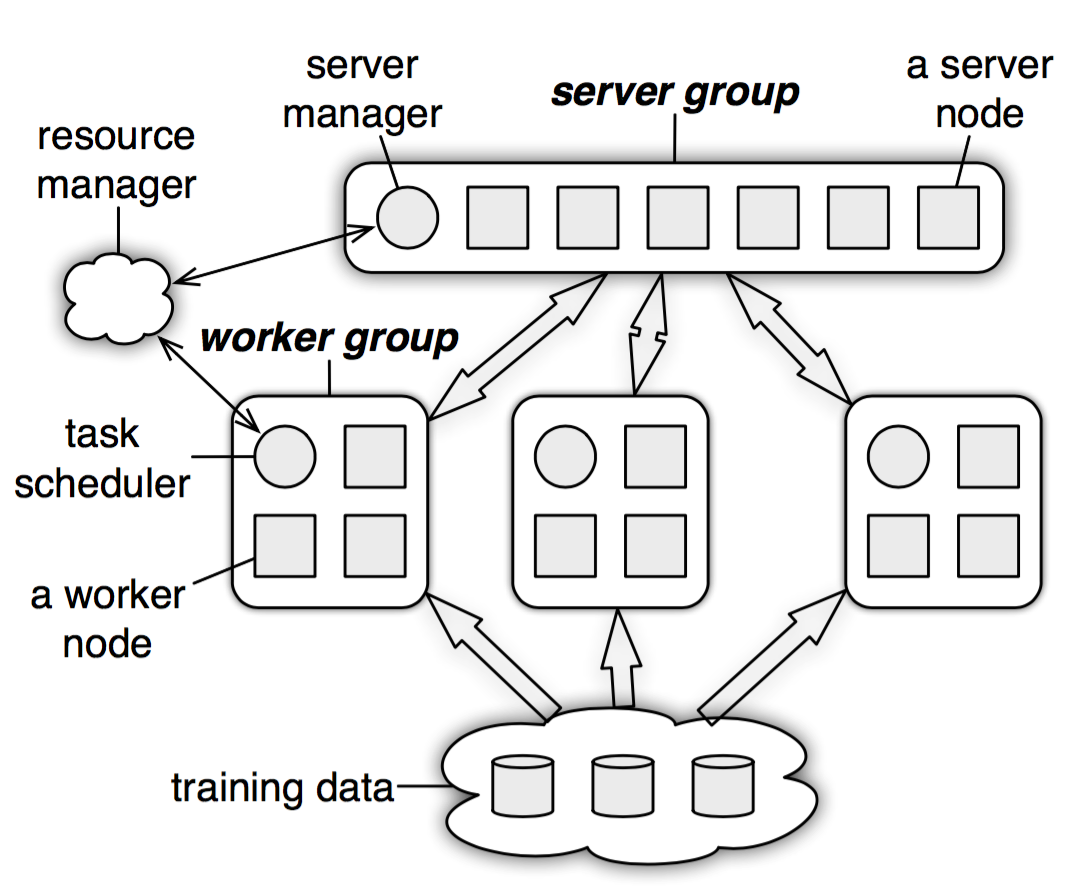
图3 parameter server的架构图,server 节点可以跟其他 server 节点通信,每个server负责自己分到的参数,server group 共同维持所有参数的更新。server manager node 负责维护一些元数据的一致性,比如各个节点的状态,参数的分配情况等;worker 节点之间没有通信,只跟自己对应的server进行通信。每个worker group有一个task scheduler,负责向worker分配任务,并且监控worker的运行情况。当有新的worker加入或者退出,task scheduler 负责重新分配任务。
PS架构包括计算资源与机器学习算法两个部分。其中计算资源分为两个部分,参数服务器节点和工作节点:
- 参数服务器节点用来存储参数
- 工作节点部分用来做算法的训练
机器学习算法也分成两个部分,即参数和训练:
- 参数部分即模型本身,有一致性的要求,参数服务器也可以是一个集群,对于大型的算法,比如DNN,CNN,参数上亿的时候,自然需要一个集群来存储这么多的参数,因而,参数服务器也是需要调度的。
- 训练部分自然是并行的,不然无法体现分布式机器学习的优势。因为参数服务器的存在,每个计算节点在拿到新的batch数据之后,都要从参数服务器上取下最新的参数,然后计算梯度,再将梯度更新回参数服务器。
这种设计有两种好处:
- 通过将机器学习系统的共同之处模块化,算法实现代码更加简洁。
- 作为一个系统级别共享平台优化方法,PS结构能够支持很多种算法。
从而,PS架构有五个特点:
- 高效的通信:异步通信不会拖慢计算
- 弹性一致:将模型一致这个条件放宽松,允许在算法收敛速度和系统性能之间做平衡。
- 扩展性强:增加节点无需重启网络
- 错误容忍:机器错误恢复时间短,Vector Clock容许网络错误
- 易用性: 全局共享的参数使用向量和矩阵表示,而这些又可以用高性能多线程库进行优化。
Push and Pull
在parameter server中,参数都是可以被表示成(key, value)的集合,比如一个最小化损失函数的问题,key就是feature ID,而value就是它的权值。对于稀疏参数,不存在的key,就可以认为是0。
把参数表示成k-v, 形式更自然, 易于理,更易于编程解。workers跟servers之间通过push与pull来通信的。worker通过push将计算好的梯度发送到server,然后通过pull从server更新参数。为了提高计算性能和带宽效率,parameter server允许用户使用Range Push跟Range Pull 操作。
Task:Synchronous and Asynchronous
Task也分为同步和异步,区别如下图所示:

图4 如果iter1需要在iter0 computation,push跟pull都完成后才能开始,那么就是Synchronous,反之就是Asynchronous。Asynchronous能够提高系统的效率(因为节省了很多等待的过程),但是,它可能会降低算法的收敛速率;
所以,系统性能跟算法收敛速率之间是存在一个平衡,你需要同时考虑:
- 算法对于参数非一致性的敏感度
- 训练数据特征之间的关联度
- 硬盘的存储容量
考虑到用户使用的时候会有不同的情况,parameter server 为用户提供了多种任务依赖方式:
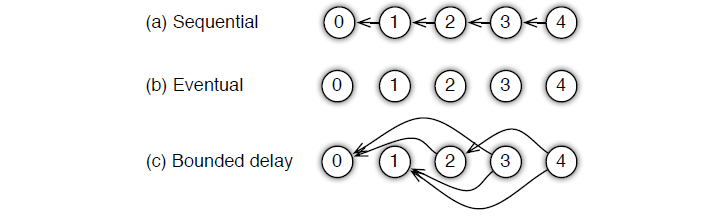
图5 三种不同的依赖方式
- Sequential:这里其实是 synchronous task,任务之间是有顺序的,只有上一个任务完成,才能开始下一个任务。
- Eventual: 跟sequential相反,所有任务之间没有顺序,各自独立完成自己的任务。
- Bounded Delay: 这是sequential 跟 eventual 之间的一个均衡,可以设置一个\(\tau\)作为最大的延时时间。也就是说,只有大于\(\tau\)之前的任务都被完成了,才能开始一个新的任务;极端的情况:
- \(\tau=0\),情况就是 Sequential;
- \(\tau=\infty\),情况就是 Eventual;
PS下的算法
算法1是没有经过优化的直接算法和它的流程图如下:

图6 算法1
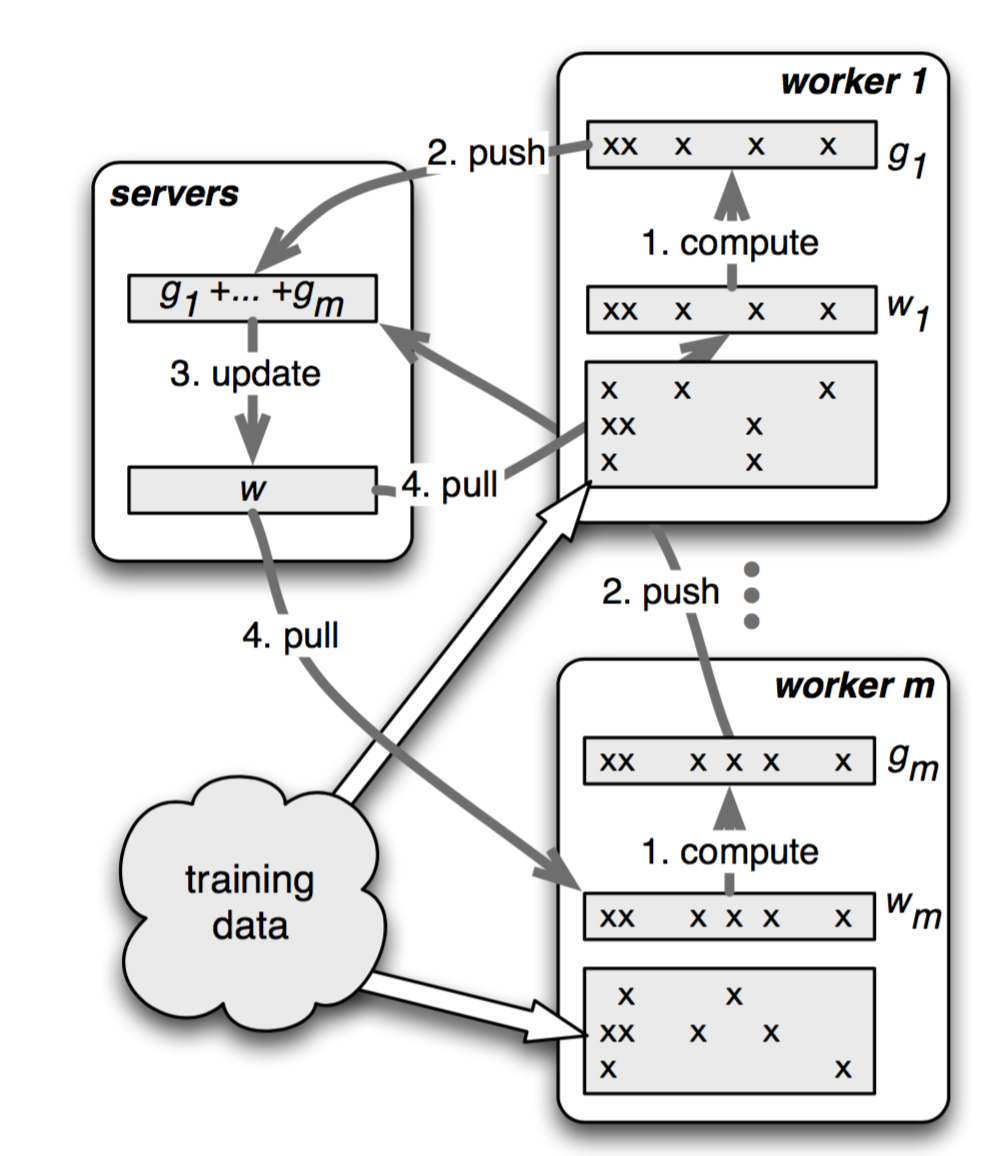
图7 算法1的流程

图8 优化算法1后的算法3。
算法3中的KKT Filter可以是用户自定义过滤:
对于机器学习优化问题比如梯度下降来说,并不是每次计算的梯度对于最终优化都是有价值的,用户可以通过自定义的规则过滤一些不必要的传送,再进一步压缩带宽消耗:
- 发送很小的梯度值是低效的:
因此可以自定义设置,只在梯度值较大的时候发送; - 更新接近最优情况的值是低效的:
因此,只在非最优的情况下发送,可通过KKT来判断;
ps-lite实现
上面说了parameter server的原理,现在来看下这个是怎么实现的。ps-lite是DMLC实现parameter server的一个程序,也是MXNet的核心组件之一。
ps-lite角色
ps-lite包含三种角色:Worker、Server、Scheduler。具体关系如下图:
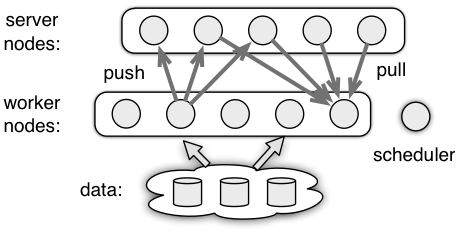
图9 三种角色的关系图
Worker节点负责计算参数,并发参数push到Server,同时从Serverpull参数回来。
Server节点负责管理Worker节点发送来的参数,并“合并”,之后供各个Worker使用。
Scheduler节点负责管理Worker节点和Server节点的状态,worker与server之间的连接是通过Scheduler的。
重要类
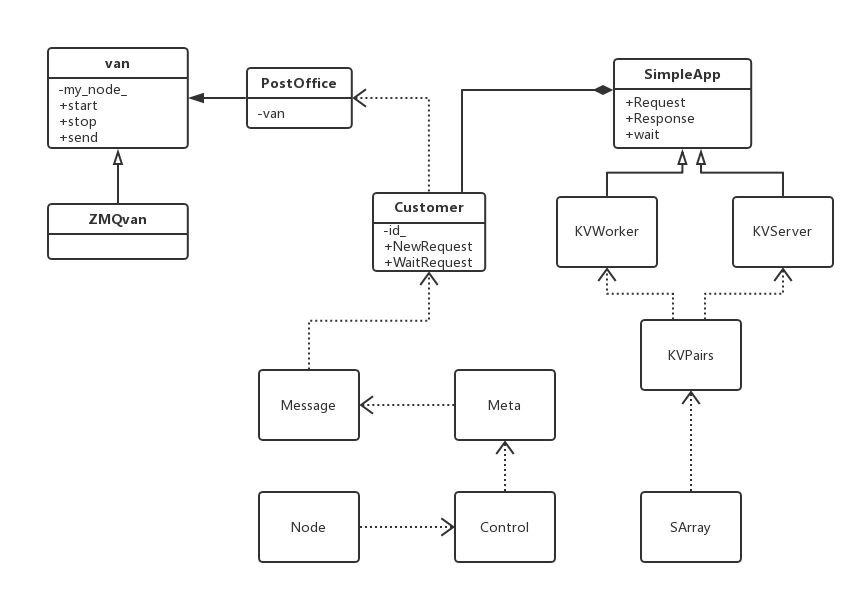
图10 重要类的关系图
Postoffice是全局管理类,单例模式创建。主要用来配置当前node的一些信息,例如当前node是哪种类型(server,worker,scheduler),nodeid是啥,以及worker/server 的rank 到 node id的转换。
Van是负责通信的类,是Postoffice的成员。Van中std::unordered_map<int, void*> senders_保存了node_id到连接的映射。Van只是定义了接口,具体实现是依赖ZMQ实现的ZMQVan,Van类负责建立起节点之间的互相连接(例如Worker与Scheduler之间的连接),并且开启本地的receiving thread用来监听收到的message。。
Customer用来通信,跟踪request和response。每一个连接对应一个Customer实例,连接对方的id和Customer实例的id相同。
SimpleApp是一个基类;提供了发送接收int型的head和string型的body消息,以及注册消息处理函数。它有2个派生类。
KVServer是SimpleApp的派生类,用来保存key-values数据。里面的Process()被注册到Customer对象中,当Customer对象的receiving thread接受到消息时,就调用Process()对数据进行处理。
KVWorker是SimpleApp的派生类,主要有Push()和Pull(),它们最后都会调用Send()函数,Send()对KVPairs进行切分,因为每个Server只保留一部分参数,因此切分后的SlicedKVpairs就会被发送给不同的Server。切分函数可以由用户自行重写,默认为DefaultSlicer,每个SlicedKVPairs被包装成Message对象,然后用van::send()发送。
KVPairs封装了Key-Value结构,还包含了一个长度选项。
SArray是Shared array,像智能指针一样共享数据,接口类似vector。
Node封装了节点的信息,例如角色、ip、端口、是否是恢复节点。
Control封装了控制信息,例如命令类型、目的节点、barrier_group的id、签名。
Meta封装了元数据,发送者、接受者、时间戳、请求还是相应等。
Message是要发送的信息,除了元数据外,还包括发送的数据。
运行脚本
为了更好地看到ps-lite的运行原理,我们先来看下它在本地运行的脚本:
#!/bin/bash
# set -x
if [ $# -lt 3 ]; then
echo "usage: $0 num_servers num_workers bin [args..]"
exit -1;
fi
export DMLC_NUM_SERVER=$1
shift
export DMLC_NUM_WORKER=$1
shift
bin=$1
shift
arg="$@"
# start the scheduler
export DMLC_PS_ROOT_URI='127.0.0.1'
export DMLC_PS_ROOT_PORT=8000
export DMLC_ROLE='scheduler'
${bin} ${arg} &
# start servers
export DMLC_ROLE='server'
for ((i=0; i<${DMLC_NUM_SERVER}; ++i)); do
export HEAPPROFILE=./S${i}
${bin} ${arg} &
done
# start workers
export DMLC_ROLE='worker'
for ((i=0; i<${DMLC_NUM_WORKER}; ++i)); do
export HEAPPROFILE=./W${i}
${bin} ${arg} &
done
wait
这个脚本主要做了两件事,第一件是为不同的角色设置环境变量,第二件是在本地运行多个不同的角色。所以说ps-lite是要多个不同的进程(程序)共同合作完成工作的,ps-lite采取的是用环境变量来设置角色的配置。
test_simple_app流程
test_simple_app.cc是一人很简单的app,其它复杂的流程原理这个程序差不多,所以我们就说说这个程序是怎么运行的。先来看下刚开始运行程序时,worker(W)\Server(S)\Scheduler(H)之间是怎么连接的,这里没有写Customer处理普通信息的流程。W\S\H代表上面脚本运行各个角色后在不同角色程序内的处理流程。
- W\S\H:初始化SimpleApp --> New Customer(绑定Process函数) --> Customer起一个Receiving线程
- W\S\H:初始化static PostOffice,全局都用同一个PostOffice --> Create(Van)用来做通信的发/发 --> 从环境变量中读入配置 --> 确定不同的角色。
- W\S\H:Start() --> Van::Start(), my_node_/Scheduler的初始化
- W\S:绑定port并连接到同一个Scheduler
- W\S:发送信息到指定ID
- W\S\h:在van中起一个Reciving的线程
- H:收到信息并回发
- W\S: 收到信息
- W\S\H:Finalize()
Customer处理普通信息流程如下:
- H:app->requst() --> 放这个请求入到tracker_中 --> send(msg) --> app->wait()[等待收回发的信息]
- W/S:收到信息后放到recv_queue_中
- W/S:Customer的Reciving收到信息 --> call recv_handle_ --> process(recv)[处理信息] --> response_hadle_(recv) --> ReqHandle() --> response()[回发信息]
- H:收到回发的信息 --> 放入到recv_queue_中处理 --> 在Customer中的Reciving中处理
- H:当tracker_.first == tracker_.second时,释放app->wait()
参考引用:
[1] http://blog.csdn.net/stdcoutzyx/article/details/51241868
[2] http://blog.csdn.net/cyh_24/article/details/50545780
[3] https://www.zybuluo.com/Dounm/note/529299
[4] http://blog.csdn.net/KangRoger/article/details/73307685
【防止爬虫转载而导致的格式问题——链接】:
http://www.cnblogs.com/heguanyou/p/7868596.html
MXNet之ps-lite及parameter server原理的更多相关文章
- [Distributed ML] Parameter Server & Ring All-Reduce
Resource ParameterServer入门和理解[较为详细,涉及到另一个框架:ps-lite] 一文读懂「Parameter Server」的分布式机器学习训练原理 并行计算与机器学习[很有 ...
- 转:Parameter Server 详解
Parameter Server 详解 本博客仅为作者记录笔记之用,不免有很多细节不对之处. 还望各位看官能够见谅,欢迎批评指正. 更多相关博客请猛戳:http://blog.csdn.net/c ...
- 【分布式计算】MapReduce的替代者-Parameter Server
原文:http://blog.csdn.net/buptgshengod/article/details/46819051 首先还是要声明一下,这个文章是我在入职阿里云1个月以来,对于分布式计算的一点 ...
- PS Lite 笔记
本文讲解的 PS Lite 源码版本限定如下: GitHub: https://github.com/dmlc/ps-lite/tree/master Commit: f45e2e78a7430be0 ...
- parameter server学习
关于parameter server的学习: https://www.zybuluo.com/Dounm/note/517675 机器学习系统相比于其他系统而言,有一些自己的独特特点.例如: 迭代性: ...
- ROS参数服务器(Parameter Server)
操作演示,对参数服务器的理解:点击打开链接 rosparam使得我们能够存储并操作ROS 参数服务器(Parameter Server)上的数据.参数服务器能够存储整型.浮点.布尔.字符串.字典和列表 ...
- 百度DMLC分布式深度机器学习开源项目(简称“深盟”)上线了如xgboost(速度快效果好的Boosting模型)、CXXNET(极致的C++深度学习库)、Minerva(高效灵活的并行深度学习引擎)以及Parameter Server(一小时训练600T数据)等产品,在语音识别、OCR识别、人脸识别以及计算效率提升上发布了多个成熟产品。
百度为何开源深度机器学习平台? 有一系列领先优势的百度却选择开源其深度机器学习平台,为何交底自己的核心技术?深思之下,却是在面对业界无奈时的远见之举. 5月20日,百度在github上开源了其 ...
- Spark job server原理初探
Spark job server是一个基于Spark的服务系统,提供了管理SparkJob,context,jar的RestFul接口. 专注标注原文链接 http://www.cnblogs.com ...
- Ps回调函数.拦截驱动模块原理+实现.
目录 一丶简介 二丶原理 1.原理 2.代码实现 3.效果 一丶简介 主要是讲解.内核中如何拦截模块加载的. 需要熟悉.内核回调的设置 PE知识. ShellCode 二丶原理 1.原理 原理是通过回 ...
随机推荐
- SqlServer与Linq 无限递归目录树且输出层级
ALTER VIEW [dbo].[view_TreeLevel] AS WITH cte AS ( SELECT a.ModuleID , a.Module_Name , a.Module_Desc ...
- ASP.NET/MVC 配置log4net启用写错误日志功能
<?xml version="1.0" encoding="utf-8"?> <!-- 有关如何配置 ASP.NET 应用程序的详细信息,请访 ...
- 使用MxNet新接口Gluon提供的预训练模型进行微调
1. 导入各种包 from mxnet import gluon import mxnet as mx from mxnet.gluon import nn from mxnet import nda ...
- 知识树杂谈Java面试(4)
一. Java集合 1. 集合分类: Collection.Map. 2. Collection: 3. Map 4. 注意点 a. List 有序.可重复:Set 无序.不可重复:Map 键值 ...
- PHP中header的作用
1.跳转: //若等待时间为0,则与header("location:")等效. //Header("Location:http://localhost//sessio ...
- hibernate利用mysql的自增张id属性实现自增长id和手动赋值id并存
我们知道在mysql中如果设置了表id为自增长属性的话,insert语句中如果对id赋值(值没有被用到过)了,则插入的数据的id会为用户设置的值,并且该表的id的最大值会重新计算,以插入后表的id最大 ...
- zabbix杂文
ps:这是从我原来记录的地方直接copy的,很杂乱,不过主要我想记录当时的思路,乱就乱了...... 背景: 这是进公司的第一个正式任务(之前在测试环境熟悉),所以基本上最近一段时间都在弄这个东西,一 ...
- 接口测试思路,jmeter,接口测试流程
接口测试总结 一:接口测试思想 接口测试:通过向服务器端发送请求,获取响应与预期结果做对比的一种服务端黑盒测试过程. 解释:接口就是将浏览器,客户端,手机端,或者服务器调用另一个服务器的请求抽离出来测 ...
- Fedora 下 Google-Chrome 经常出现僵尸进程的权宜办法
对于Chrome_ProcessL 和Chrome_FileThre这两僵尸进程,估计遇到过的人都对其各种无奈吧,放任不管吧,越来越多,然后卡死,只能另开个X环境或者在其他的TTY里干掉他俩再切回去, ...
- Unix时代的开创者Ken Thompson
自图灵奖诞生以来,其获得者一直都是计算机领域的科学家与学者,而在所有这些界的图灵奖中只有唯一的一届有个例外,那就是Ken Thompson与Dennis M. Ritchie,他们都是计算机软件工程师 ...