spark-submit参数说明--on YARN
示例: spark-submit [--option value] <application jar> [application arguments]
|
参数名称 |
含义 |
|
--master MASTER_URL |
yarn |
|
--deploy-mode DEPLOY_MODE |
Driver程序运行的地方:client、cluster |
|
--class CLASS_NAME |
The FQCN of the class containing the main method of the application. For example, org.apache.spark.examples.SparkPi. 应用程序主类名称,含包名 |
|
--name NAME |
应用程序名称 |
|
--jars JARS |
Driver和Executor依赖的第三方jar包 |
|
--properties-file FILE |
应用程序属性的文件路径,默认是conf/spark-defaults.conf |
|
以下设置Driver |
|
|
--driver-cores NUM |
Driver程序使用的CPU核数(只用于cluster),默认为1 |
|
--driver-memory MEM |
Driver程序使用内存大小 |
|
--driver-library-path |
Driver程序的库路径 |
|
--driver-class-path |
Driver程序的类路径 |
|
--driver-java-options |
|
|
以下设置Executor |
|
|
--num-executors NUM |
The total number of YARN containers to allocate for this application. Alternatively, you can use the spark.executor.instances configuration parameter. 启动的executor的数量,默认为2 |
|
--executor-cores NUM |
Number of processor cores to allocate on each executor 每个executor使用的CPU核数,默认为1 |
|
--executor-memory MEM |
The maximum heap size to allocate to each executor. Alternatively, you can use the spark.executor.memory configuration parameter. 每个executor内存大小,默认为1G |
|
--queue QUEUE_NAME |
The YARN queue to submit to. 提交应用程序给哪个YARN的队列,默认是default队列 |
|
--archives ARCHIVES |
|
|
--files FILES |
用逗号隔开的要放置在每个executor工作目录的文件列表 |
1.部署模式概述
2.部署模式:Cluster
In cluster mode, the driver runs in the ApplicationMaster on a cluster host chosen by YARN.
This means that the same process, which runs in a YARN container, is responsible for both driving the application and requesting resources from YARN.
The client that launches the application doesn't need to continue running for the entire lifetime of the application.
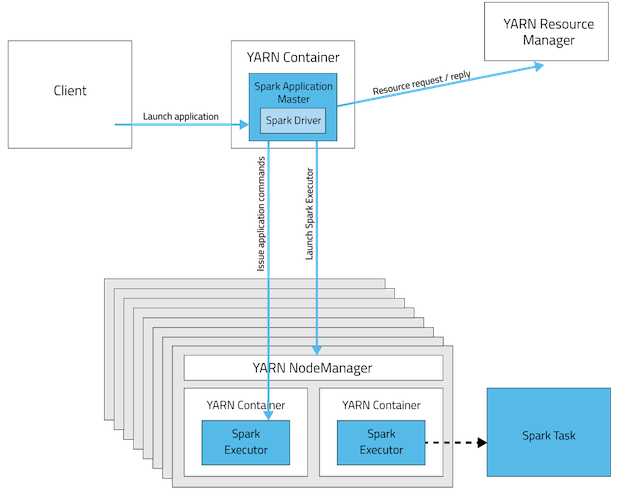
Cluster mode is not well suited to using Spark interactively.
Spark applications that require user input, such as spark-shell and pyspark, need the Spark driver to run inside the client process that initiates the Spark application.
3.部署模式:Client
In client mode, the driver runs on the host where the job is submitted.
The ApplicationMaster is merely present to request executor containers from YARN.
The client communicates with those containers to schedule work after they start:
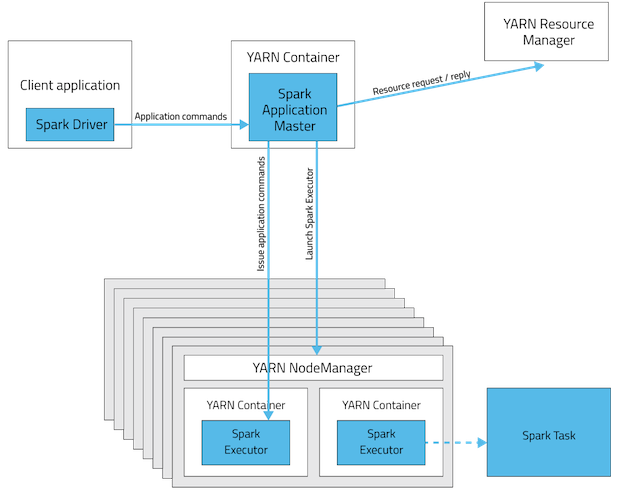
4.参考文档:
https://www.cloudera.com/documentation/enterprise/5-4-x/topics/cdh_ig_running_spark_on_yarn.html
http://spark.apache.org/docs/1.3.0/running-on-yarn.html
spark-submit参数说明--on YARN的更多相关文章
- spark submit参数及调优
park submit参数介绍 你可以通过spark-submit --help或者spark-shell --help来查看这些参数. 使用格式: ./bin/spark-submit \ ...
- spark submit参数及调优(转载)
spark submit参数介绍 你可以通过spark-submit --help或者spark-shell --help来查看这些参数. 使用格式: ./bin/spark-submit \ -- ...
- Spark On Yarn:提交Spark应用程序到Yarn
转载自:http://lxw1234.com/archives/2015/07/416.htm 关键字:Spark On Yarn.Spark Yarn Cluster.Spark Yarn Clie ...
- 【原创】大数据基础之Spark(1)Spark Submit即Spark任务提交过程
Spark2.1.1 一 Spark Submit本地解析 1.1 现象 提交命令: spark-submit --master local[10] --driver-memory 30g --cla ...
- Spark作业提交至Yarn上执行的 一个异常
(1)控制台Yarn(Cluster模式)打印的异常日志: client token: N/A diagnostics: Application application_1584359 ...
- spark submit local遇到路径hdfs的问题
有时候第一次执行 spark submit --master local[*] 单机模式的时候,可以对linux本地路径进行输出.但是有时候提交到yarn的时候,是自动加上hdfs的路径这没问题, 但 ...
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- spark任务提交到yarn上命令总结
spark任务提交到yarn上命令总结 1. 使用spark-submit提交任务 集群模式执行 SparkPi 任务,指定资源使用,指定eventLog目录 spark-submit --class ...
- spark submit参数调优
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
随机推荐
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- websocket做手机页面聊天与PC页面聊天一对一的即时通讯
当时要写这个需求的时候,很头痛,手机端页面的客服功能,相当于QQ这样一个一对一聊天室功能了,瞬间蒙蔽的我也不知道用什么去写这个东西,一开始用ajax,定时器去写,写着写着发现这尼玛不在同一个页面怎么做 ...
- python - dict.setdefault
index = dict.serdefault(key,default) 尝试往dict中插入新键值key,如果key已存在就原dict不变,否则插入key:defalut:返回值为key在dict中 ...
- Fedora 23建立wifi热点(Android手机可用)
在ubuntu14.04下使用ap-hotspot,速度还不错.但是在15.04下就用不了了,不知为啥.现在使用fedora23,在学校还是挺需要给手机连wifi的,于是google看看ap-hots ...
- laravel webpack填坑(陆续更)
ie Promise支持需引入babel-polyfill, 在官方文档中js函数介绍有点少导致按babel-polyfill官方引入时找不到北 //webpack.mix.jsmix.js(['no ...
- laravel 500错误的一个解决办法
我从svn上update下来了开发环境的目录,结果当我访问本地的根目录的时候却报了500错误,百度了许多,也看了很多博客,发现都没有解决我的问题,所以我觉得我的解决办法值得一写,当你从svn上upda ...
- AndroidStudio cannot resolve symbol 解决办法 清楚缓存
<?xml version="1.0" encoding="utf-8"?><RelativeLayout xmlns:android=&qu ...
- 谈谈微服务中的 API 网关(API Gateway)
前言 又是很久没写博客了,最近一段时间换了新工作,比较忙,所以没有抽出来太多的时间写给关注我的粉丝写一些干货了,就有人问我怎么最近没有更新博客了,在这里给大家抱歉. 那么,在本篇文章中,我们就一起来探 ...
- 算法提高 9-3摩尔斯电码 map
算法提高 9-3摩尔斯电码 时间限制:1.0s 内存限制:256.0MB 问题描述 摩尔斯电码破译.类似于乔林教材第213页的例6.5,要求输入摩尔斯码,返回英文.请不要使用"z ...
- mysql读写分离的操作动作依据(读写分离基本依据)
读的操作: 1.select 2.show 3.explain explain显示了MySQL如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 4.desc ...