Hadoop伪分布式部署
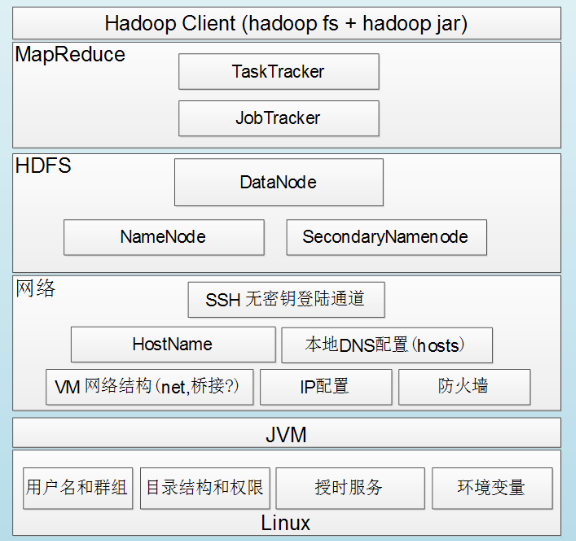
一、Hadoop组件依赖关系:
步骤
1)关闭防火墙和禁用SELinux
切换到root用户
关闭防火墙:service iptables stop
Linux下开启/关闭防火墙的两种方法
1.永久性生效,重启后不会恢复:
开启:chkconfig iptables on
关闭:chkconfig iptables off
2.即时生效,重启后恢复
开启:service iptables start
关闭:service iptables stop
禁用SELinux
vim /etc/sysconfig/selinux 设置SELinux=disabled
2)设置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
3)修改主机名(hostname)
vim /etc/sysconfig/network
4)IP与hostname绑定
作用:可以在window浏览器主页上输入IP地址加端口号访问linux下Hadoop的运行进程
vim /etc/hosts
内容显示如下
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.217.150 linux.chaofn.org linux
然后在window下的C:\Windows\System32\drivers\etc目录下有一个hosts文件,打开写入
192.168.217.150 linux.chaofn.org linux
5)设置SSH自动登录(所有守护进程通过SSH协议进行通信)
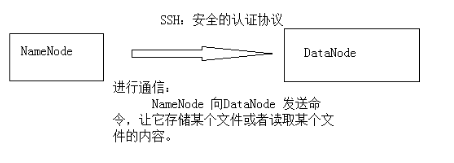
免秘钥设置,方便namenode向datanode的访问
切换到普通用户
输入命令 ssh-keygen -t rsa
默认是在~/.ssh/目录下
drwx------ 2 chaofn chaofn 4096 May 20 20:00 .ssh 权限为700,要改为644
进入.ssh目录,有两个文件id_rsa id_rsa.pub,一个是私钥,一个是公钥
然后复制一份id_rsa.pub,命令:cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys(这个操作实现了权限的更改)
测试.命令 ssh localhost
ssh linux.chaofn.org
6)Hadoop环境变量配置:
vim /etc/profile 添加如下内容:
#HADOOP
export HADOOP_HOME=/home/chaofn/opt/setup/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin
7)修改conf目录下的配置文件
配置core-site.xml

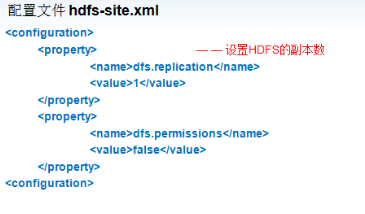
配置hdfs-site.xml
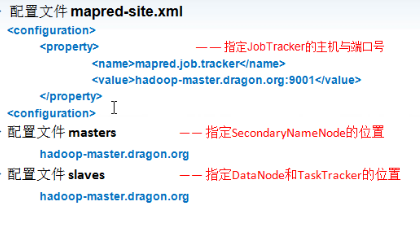
配置mapred-site.xml、masters、slaves
8)格式化namenode
命令:hadoop namenode -format
注意格式化过程中出现的错误提示,仔细检查
9)启动Hadoop
命令:start-all.sh(启动方式有很多种)
通过jps命令查看五个进程是否全部启动
通过window的网页界面查看
输入hadoop-master.dragon.org:50030(我的域名是linux.chaofn.org)查看是否启动
注意一定要关闭linux下的防火墙,不然window无法访问
Hadoop伪分布式部署的更多相关文章
- ubuntu hadoop伪分布式部署
环境 ubuntu hadoop2.8.1 java1.8 1.配置java1.8 2.配置ssh免密登录 3.hadoop配置 环境变量 配置hadoop环境文件hadoop-env.sh core ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2) https://hadoop.apache.org/releases.html 准备工作 关闭防火墙 (也可放行) # 停止防火墙 systemctl stop f ...
- Hadoop1 Centos伪分布式部署
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- Hadoop伪分布式的搭建
主要分为三个步骤:1.安装vmware虚拟机运行软件 2.在vmware虚拟机中安装linux操作系统 3.配置hadoop伪分布式环境 Hadoop环境部署-JDK部分------------ ...
- 基于Centos搭建 Hadoop 伪分布式环境
软硬件环境: CentOS 7.2 64 位, OpenJDK- 1.8,Hadoop- 2.7 关于本教程的说明 云实验室云主机自动使用 root 账户登录系统,因此本教程中所有的操作都是以 roo ...
- hadoop3.1伪分布式部署
1.环境准备 系统版本:CentOS7.5 主机名:node01 hadoop3.1 的下载地址: http://mirror.bit.edu.cn/apache/hadoop/common/hado ...
- Hadoop-01 搭建hadoop伪分布式运行环境
Linux中配置Hadoop运行环境 程序清单 VMware Workstation 11.0.0 build-2305329 centos6.5 64bit jdk-7u80-linux-x64.r ...
随机推荐
- DataBase MongoDB基础知识记录
MongoDB基础知识记录 一.概念: 讲mongdb就必须提一下nosql,因为mongdb是nosql的代表作: NoSQL(Not Only SQL ),意即“不仅仅是SQL” ,指的是非关系型 ...
- (转)为Xcode添加删除行、复制行快捷键
转摘链接:http://www.jianshu.com/p/cc6e13365b7e 在使用eclipse过程中,特喜欢删除一行和复制一行的的快捷键.而恰巧Xcode不支持这两个快捷键,再一次的恰巧让 ...
- Hive实际应用小结
1.简介 Hive是数据仓库平台,构建在Hadoop之上用来处理结构化数据.Hive是一个SQL解析引擎,能够将SQL语句转化成MapReduce作业并在Hadoop上执行,从而使得查询和分析更加方便 ...
- 树形dp系列
1.火车站开饭店 最大独立集裸题 #include<iostream> #include<cstdio> #include<cstdlib> #include< ...
- bzoj 4310: 跳蚤
Description 很久很久以前,森林里住着一群跳蚤.一天,跳蚤国王得到了一个神秘的字符串,它想进行研究. 首先,他会把串分成不超过 k 个子串,然后对于每个子串 S,他会从S的所有子串中选择字典 ...
- C#序列化总结
贴一下自己序列化的代码: public class XMLUtil { /// <summary> /// XML & Datacontract Serialize & D ...
- cp 命令详解
作用: cp 指令用于复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录, 则它会把前面指定的所有文件或目录复制到此目录下, 若同时指定多个文件或目录, 而最后的目的 ...
- 记录python学习过程中的一些小心得
1.python中一切皆对象,内置数据结构也是对象.处理一个对象就是利用它带有的方法和属性,对该对象进行处理,一步步达到我们想要的结果. 2.编程时,先构思好我们处理的对象是什么,具有哪些属性和方法, ...
- js必须掌握的基础
好多人想要学习前端……自学或者培训那么我们在学习过程中到底需要掌握那些基础知识呢!下面分类了JS中必备的知识也是必须要了解学会的!看一看你是否已经将JS的基础知识都了如指掌了呢? 事件: onmous ...
- 理解JavaScript原型
Javascript原型总会给人产生一些困惑,无论是经验丰富的专家,还是作者自己也时常表现出对这个概念某些有限的理解,我认为这样的困惑在我们一开始接触原型时就已经产生了,它们常常和new.constr ...