Hadoop伪分布式部署
一、Hadoop组件依赖关系:
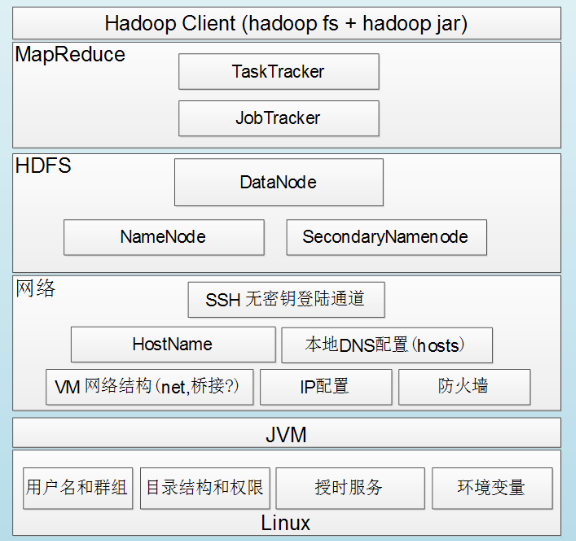
步骤
1)关闭防火墙和禁用SELinux
切换到root用户
关闭防火墙:service iptables stop
Linux下开启/关闭防火墙的两种方法
1.永久性生效,重启后不会恢复:
开启:chkconfig iptables on
关闭:chkconfig iptables off
2.即时生效,重启后恢复
开启:service iptables start
关闭:service iptables stop
禁用SELinux
vim /etc/sysconfig/selinux 设置SELinux=disabled
2)设置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
3)修改主机名(hostname)
vim /etc/sysconfig/network
4)IP与hostname绑定
作用:可以在window浏览器主页上输入IP地址加端口号访问linux下Hadoop的运行进程
vim /etc/hosts
内容显示如下
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.217.150 linux.chaofn.org linux
然后在window下的C:\Windows\System32\drivers\etc目录下有一个hosts文件,打开写入
192.168.217.150 linux.chaofn.org linux
5)设置SSH自动登录(所有守护进程通过SSH协议进行通信)
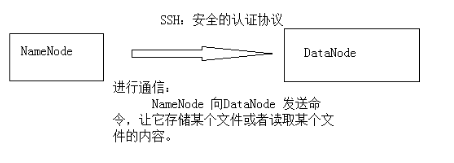
免秘钥设置,方便namenode向datanode的访问
切换到普通用户
输入命令 ssh-keygen -t rsa
默认是在~/.ssh/目录下
drwx------ 2 chaofn chaofn 4096 May 20 20:00 .ssh 权限为700,要改为644
进入.ssh目录,有两个文件id_rsa id_rsa.pub,一个是私钥,一个是公钥
然后复制一份id_rsa.pub,命令:cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys(这个操作实现了权限的更改)
测试.命令 ssh localhost
ssh linux.chaofn.org
6)Hadoop环境变量配置:
vim /etc/profile 添加如下内容:
#HADOOP
export HADOOP_HOME=/home/chaofn/opt/setup/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin
7)修改conf目录下的配置文件
配置core-site.xml

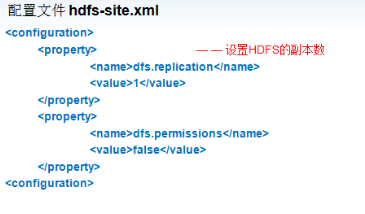
配置hdfs-site.xml
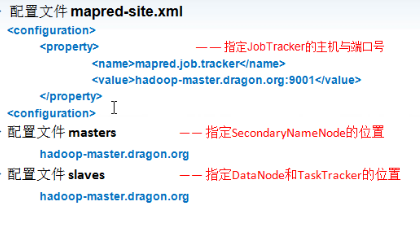
配置mapred-site.xml、masters、slaves
8)格式化namenode
命令:hadoop namenode -format
注意格式化过程中出现的错误提示,仔细检查
9)启动Hadoop
命令:start-all.sh(启动方式有很多种)
通过jps命令查看五个进程是否全部启动
通过window的网页界面查看
输入hadoop-master.dragon.org:50030(我的域名是linux.chaofn.org)查看是否启动
注意一定要关闭linux下的防火墙,不然window无法访问
Hadoop伪分布式部署的更多相关文章
- ubuntu hadoop伪分布式部署
环境 ubuntu hadoop2.8.1 java1.8 1.配置java1.8 2.配置ssh免密登录 3.hadoop配置 环境变量 配置hadoop环境文件hadoop-env.sh core ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2) https://hadoop.apache.org/releases.html 准备工作 关闭防火墙 (也可放行) # 停止防火墙 systemctl stop f ...
- Hadoop1 Centos伪分布式部署
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- Hadoop伪分布式的搭建
主要分为三个步骤:1.安装vmware虚拟机运行软件 2.在vmware虚拟机中安装linux操作系统 3.配置hadoop伪分布式环境 Hadoop环境部署-JDK部分------------ ...
- 基于Centos搭建 Hadoop 伪分布式环境
软硬件环境: CentOS 7.2 64 位, OpenJDK- 1.8,Hadoop- 2.7 关于本教程的说明 云实验室云主机自动使用 root 账户登录系统,因此本教程中所有的操作都是以 roo ...
- hadoop3.1伪分布式部署
1.环境准备 系统版本:CentOS7.5 主机名:node01 hadoop3.1 的下载地址: http://mirror.bit.edu.cn/apache/hadoop/common/hado ...
- Hadoop-01 搭建hadoop伪分布式运行环境
Linux中配置Hadoop运行环境 程序清单 VMware Workstation 11.0.0 build-2305329 centos6.5 64bit jdk-7u80-linux-x64.r ...
随机推荐
- 轨迹系列——Socket总结及实现基于TCP或UDP的809协议方法
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 在上一篇博客中我详细介绍了809协议的内容.809协议规范了通 ...
- Swift3.0 创建工程常用的类、三方、以及扩展 1.5
搭建项目常用的方法属性,欢迎追加 三方: source 'https://github.com/CocoaPods/Specs.git' platform :ios, '8.0' use_framew ...
- [HDU - 5170GTY's math problem 数的精度类
题目链接:HDU - 5170GTY's math problem 题目描述 Description GTY is a GodBull who will get an Au in NOI . To h ...
- 记vue API 知识点
1. v-cloak指令:这个指令保持在元素上直到关联实例结束编译.和 CSS 规则如 [v-cloak] { display: none } 一起用时,这个指令可以隐藏未编译的 Mustache 标 ...
- ES6 let和const命令(2)
为什么要使用块级作用域 在ES5中只有全局作用域和函数作用域,没有块级作用域,因此带来了这些麻烦 内层变量可能会覆盖外层变量 var tmp = new Date(); console.log(tmp ...
- Linux Centos 使用 yum 安装java
centos 使用 yum 安装java 首先,在你的服务器上运行一下更新. yum update 然后,在您的系统上搜索,任何版本的已安装的JDK组件. rpm -qa | grep -E '^op ...
- 阅读MDN文档之StylingBoxes(五)
目录 BoxModelRecap Box properties Overflow Background clip Background origin Outline Advanced box prop ...
- linux 文件权限的基础知识
由于自己总是记不住linux里权限的一些知识,因此简单总结如下: 查看文件权限 // 列出所有文件 ls -al // 最前面的一串10个字母的字符串 // 可能像 drwxrwxr-x // 第一位 ...
- DCL的失效:现实与初衷的背离
最近看了Brian Goetz写的一篇有关DCL的文章:Double-checked locking: Clever, but broken.( 2001年发表于JavaWorld上) 这篇文章讲述了 ...
- MySQL5.6中date和string的转换和比较
Conversion & Comparison, involving strings and dates in MySQL 5.6 我们有张表,表中有一个字段dpt_date,SQL类型为da ...