Keepalived+Haproxy高可用负载均衡群集
介绍
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上.
haproxy 配置中分成五部分内容,分别如下:
- global:参数是进程级的,通常是和操作系统相关。这些参数一般只设置一次,如果配置无误,就不需要再次进行修改
- defaults:配置默认参数,这些参数可以被用到frontend,backend,Listen组件
- frontend:接收请求的前端虚拟节点,Frontend可以更加规则直接指定具体使用后端的backend
- backend:后端服务集群的配置,是真实服务器,一个Backend对应一个或者多个实体服务器
- Listen Fronted和backend的组合体
安装使用
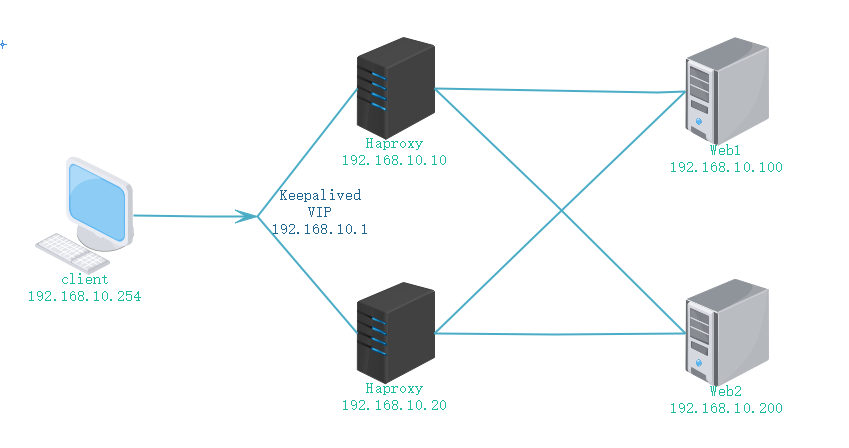
使用以上图的拓扑来配置使用haproxy
1.配置各服务器的IP地址
略
2.安装Haproxy(两台负载均衡器配置一样)
#编译安装
[root@haproxy ~]# tar zxvf haproxy-1.4..tar.gz -C /usr/src/
[root@haproxy ~]# cd /usr/src/haproxy-1.4./
[root@haproxy haproxy-1.4.]# make TARGET=linux26 PREFIX=/usr/local/haproxy
[root@haproxy haproxy-1.4.]# make install PREFIX=/usr/local/haproxy
参数解释:linux26表示linux的内核版本号
可以使用uname -r查看
[root@haproxy ~]# uname -r
2.6.-.el6.x86_64 #创建启动文件
[root@haproxy ~]# cp /usr/src/haproxy-1.4./examples/haproxy.init /etc/init.d/haproxy
[root@haproxy ~]# chmod +x /etc/init.d/haproxy
[root@haproxy ~]# ln -s /usr/local/haproxy/sbin/haproxy /usr/sbin/ #创建配置文件
[root@haproxy ~]# mkdir /etc/haproxy
[root@haproxy ~]# cp /usr/src/haproxy-1.4./examples/haproxy.cfg /etc/haproxy/
3.修改Haproxy配置文件(两台负载均衡器配置一样)
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
修改为:
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
#log loghost local0 info
maxconn
chroot /usr/share/haproxy
uid
gid
daemon
#debug
#quiet
defaults
log global
mode http
option httplog
option dontlognull
retries
redispatch
maxconn
contimeout
clitimeout
srvtimeout
listen web_pool_server 192.168.10.1:
option httpchk /index.html
balance roundrobin
server inst1 192.168.10.100: check inter fall
server inst2 192.168.10.200: check inter fall
启动服务:
[root@haproxy ~]# /etc/init.d/haproxy restart
Shutting down haproxy: [FAILED]
Starting haproxy: [WARNING] / () : parsing [/etc/haproxy/haproxy.cfg:]: keyword 'redi 'option redispatch' instead.
[ALERT] / () : [/usr/sbin/haproxy.main()] Cannot chroot(/usr/share/haproxy).
[FAILED]
会出现如上错误,解决方法:
方法一:创建此目录(主要用于存放一些临时数据文件)
[root@haproxy ~]# mkdir /usr/share/haproxy
方法二,将haproxy配置文件中的此行注释掉
#chroot /usr/share/haprox
haproxy配置项介绍:
Haproxy配置文件爱你通常分为三部分(global、defaults、listen),global为全局配置、defaults为默认配置、listen为应用组件配置。
配置说明如下(可参考:http://freehat.blog.51cto.com/1239536/1347882):
###########全局配置#########
global
log 127.0.0.1 local0 #[日志输出配置,所有日志都记录在本机,通过local0输出]
log 127.0.0.1 local1 notice #定义haproxy 日志级别[error warringinfo debug]
daemon #以后台形式运行harpoxy
nbproc #设置进程数量
pidfile /home/haproxy/haproxy/conf/haproxy.pid #haproxy 进程PID文件
ulimit-n #ulimit 的数量限制
maxconn #默认最大连接数,需考虑ulimit-n限制
#chroot /usr/share/haproxy #chroot运行路径
uid #运行haproxy 用户 UID
gid #运行haproxy 用户组gid
#debug #haproxy 调试级别,建议只在开启单进程的时候调试
#quiet ########默认配置############
defaults
log global
mode http #默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK
option httplog #日志类别,采用httplog
option dontlognull #不记录健康检查日志信息
retries #两次连接失败就认为是服务器不可用,也可以通过后面设置
option forwardfor #如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端ip
option httpclose #每次请求完毕后主动关闭http通道,haproxy不支持keep-alive,只能模拟这种模式的实现
#option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器,以后将不支持
option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
maxconn #默认的最大连接数
timeout connect 5000ms #连接超时
timeout client 30000ms #客户端超时
timeout server 30000ms #服务器超时
#timeout check #心跳检测超时
#timeout http-keep-alive10s #默认持久连接超时时间
#timeout http-request 10s #默认http请求超时时间
#timeoutqueue 1m #默认队列超时时间
balance roundrobin #设置默认负载均衡方式,轮询方式
#balance source # 设置默认负载均衡方式,类似于nginx的ip_hash
#balnace leastconn #设置默认负载均衡方式,最小连接数 ########统计页面配置########
listen admin_stats
bind 0.0.0.0: #设置Frontend和Backend的组合体,监控组的名称,按需要自定义名称
mode http #http的7层模式
option httplog #采用http日志格式
#log 127.0.0.1 local0 err #错误日志记录
maxconn #默认的最大连接数
stats refresh 30s #统计页面自动刷新时间
stats uri /stats #统计页面url
stats realm XingCloud\ Haproxy #统计页面密码框上提示文本
stats auth admin:admin #设置监控页面的用户和密码:admin,可以设置多个用户名
stats auth Frank:Frank #设置监控页面的用户和密码:Frank
stats hide-version #隐藏统计页面上HAProxy的版本信息
stats admin if TRUE #设置手工启动/禁用,后端服务器(haproxy-1.4.9以后版本) ########设置haproxy 错误页面#####
errorfile /home/haproxy/haproxy/errorfiles/.http
errorfile /home/haproxy/haproxy/errorfiles/.http
errorfile /home/haproxy/haproxy/errorfiles/.http
errorfile /home/haproxy/haproxy/errorfiles/.http
errorfile /home/haproxy/haproxy/errorfiles/.http ########frontend前端配置##############
bind *:
#这里建议使用bind *:80的方式,要不然做集群高可用的时候有问题,vip切换到其他机器就不能访问了。
acl web hdr(host) -i www.abc.com
#acl后面是规则名称,-i是要访问的域名,
acl img hdr(host) -i img.abc.com
如果访问www.abc.com这个域名就分发到下面的webserver 的作用域。
#如果访问img.abc.com.cn就分发到imgserver这个作用域。
use_backend webserver if web
use_backend imgserver if img ########backend后端配置##############
backend webserver #webserver作用域
mode http
balance roundrobin
#banlance roundrobin 轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数
option httpchk /index.html HTTP/1.0 #健康检查
#检测文件,如果分发到后台index.html访问不到就不再分发给它
server web1 10.16.0.9: cookie weight check inter rise fall
server web2 10.16.0.10: cookie weight check inter rise fall
#cookie 1表示serverid为1,check inter 是检测心跳频率
#rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用,weight代表权重
backend imgserver
mode http
option httpchk /index.php
balance roundrobin
server img01 192.168.137.101: check inter fall
server img02 192.168.137.102: check inter fall ########tcp配置#################
listen test1
bind 0.0.0.0:
mode tcp
option tcplog #日志类别,采用tcplog
maxconn
#log 127.0.0.1 local0 debug
server s1 10.18.138.201: weight
server s2 10.18.102.190: weight
haproxy.cfg
4.安装Keepalived并配置(参数说明可参考:http://www.cnblogs.com/zhichaoma/p/7620443.html)
[root@keepalived ~]# yum -y install kernel-devel openssl-devel popt-devel
[root@keepalived ~]# tar zxvf keepalived-1.2..tar.gz -C /usr/src/
[root@keepalived ~]# cd /usr/src/keepalived-1.2./
[root@keepalived keepalived-1.2.]# ./configure --prefix=/ --with-kernel-dir=/usr/src/kernels/2.6.-.el6.x86_64/ && make && make install
主 修改为:
global_defs {
router_id R1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id
priority
advert_int
authentication {
auth_type PASS
auth_pass
}
virtual_ipaddress {
192.168.10.1
}
}
备修改为:
global_defs {
router_id R2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id
priority
advert_int
authentication {
auth_type PASS
auth_pass
}
virtual_ipaddress {
192.168.10.1
}
}
[root@keepalived ~]# service keepalived start
[root@keepalived ~]# ip a
5.配置web节点服务器
安装Web服务,创建网站测试页面
[root@Web ~]# yum -y install httpd
[root@Web ~]# service httpd start
Web1的首页:
[root@Web ~]# echo "web site test 1" > /var/www/html/index.html
Web2的首页:
[root@Web ~]# echo "web site test 2" > /var/www/html/index.html
6.测试
使用客户机访问VIP(192.168.10.1)地址,是否有web页面轮询(因为两台web服务器使用的首页不同很容易可以看出效果),断掉一台haproxy服务器,验证另一台服务器是否可以接管调度服务
Keepalived+Haproxy高可用负载均衡群集的更多相关文章
- haproxy+keepalived实现高可用负载均衡
软件负载均衡一般通过两种方式来实现:基于操作系统的软负载实现和基于第三方应用的软负载实现.LVS就是基于Linux操作系统实现的一种软负载,HAProxy就是开源的并且基于第三应用实现的软负载. HA ...
- haproxy+keepalived实现高可用负载均衡(转)
软件负载均衡一般通过两种方式来实现:基于操作系统的软负载实现和基于第三方应用的软负载实现.LVS就是基于Linux操作系统实现的一种软负载,HAProxy就是开源的并且基于第三应用实现的软负载. ...
- LVS+Keepalived 实现高可用负载均衡
前言 在业务量达到一定量的时候,往往单机的服务是会出现瓶颈的.此时最常见的方式就是通过负载均衡来进行横向扩展.其中我们最常用的软件就是 Nginx.通过其反向代理的能力能够轻松实现负载均衡,当有服务出 ...
- LVS+Keepalived实现高可用负载均衡(转)
LVS+Keepalived实现高可用负载均衡 一.原理 1.概要介绍 如果将TCP/IP划分为5层,则Keepalived就是一个类似于3~5层交换机制的软件,具 ...
- 【架构师之路】 LVS+Keepalived实现高可用负载均衡
一.原理 1.概要介绍 如果将TCP/IP划分为5层,则Keepalived就是一个类似于3~5层交换机制的软件,具有3~5层交换功能,其主要作用是检测web服务器的状态, ...
- Linux 笔记 - 第十八章 Linux 集群之(三)Keepalived+LVS 高可用负载均衡集群
一.前言 前两节分别介绍了 Linux 的高可用集群和负载均衡集群,也可以将这两者相结合,即 Keepalived+LVS 组成的高可用负载均衡集群,Keepalived 加入到 LVS 中的原因有以 ...
- LVS+Keepalived 实现高可用负载均衡集群
LVS+Keepalived 实现高可用负载均衡集群 随着网站业务量的增长,网站的服务器压力越来越大?需要负载均衡方案!商业的硬件如 F5 ,Array又太贵,你们又是创业型互联公司如何有效 ...
- HAProxy & Keepalived L4-L7 高可用负载均衡解决方案
目录 文章目录 目录 HAProxy 负载均衡器 应用特性 性能优势 会话保持 健康检查 配置文件 负载均衡策略 ACL 规则 Web 监控平台 Keepalived 虚拟路由器 核心组件 VRRP ...
- Nginx keepalived实现高可用负载均衡详细配置步骤
Keepalived是一个免费开源的,用C编写的类似于layer3, 4 & 7交换机制软件,具备我们平时说的第3层.第4层和第7层交换机的功能.主要提供loadbalancing(负载均衡) ...
随机推荐
- SpringBoot开发案例之整合Dubbo分布式服务
前言 在 SpringBoot 很火热的时候,阿里巴巴的分布式框架 Dubbo 不知是处于什么考虑,在停更N年之后终于进行维护了.在之前的微服务中,使用的是当当维护的版本 Dubbox,整合方式也是使 ...
- SQL Server-聚焦事务、隔离级别详解(二十九)
前言 事务一直以来是我最薄弱的环节,也是我打算重新学习SQL Server的出发点,关于SQL Server中事务将分为几节来进行阐述,Always to review the basics. 事务简 ...
- 史上最全的Spring Boot配置文件详解
Spring Boot在工作中是用到的越来越广泛了,简单方便,有了它,效率提高不知道多少倍.Spring Boot配置文件对Spring Boot来说就是入门和基础,经常会用到,所以写下做个总结以便日 ...
- ajax请求基于restFul的WebApi(post、get、delete、put)
近日逛招聘软件,看到部分企业都要求会编写.请求restFul的webapi.正巧这段时间较为清闲,于是乎打开vs准备开撸. 1.何为restFul? restFul是符合rest架构风格的网络API接 ...
- 《React Native 精解与实战》书籍连载「配置 iOS 与 Android 开发环境」
此文是我的出版书籍<React Native 精解与实战>连载分享,此书由机械工业出版社出版,书中详解了 React Native 框架底层原理.React Native 组件布局.组件与 ...
- Python入门-Hello Word
1.python语言介绍 Python创始人:Guido Van Rossum 2.python是一种解释型.动态类型计算机程序设计语言. 解释型:程序无需编译成二进制代码,而是在执行时对语句一条一条 ...
- UnderWater+SDN论文之四
Open Source Suites for Underwater Networking:WOSS and DESERT Underwater Source: IEEE Network, 2014 仿 ...
- Eclipse中Git的使用以及IDEA中Git的使用
一.Eclipse中Git解决冲突步骤: 1.进行文件对比,将所有的文件添加到序列. 2.commit文件到本地仓库. 3.pull将远程仓库的代码更新到本地,若有冲突则会所有的文件显示冲突状态(真正 ...
- 消息队列queue
一.queue 在多线程编程中,程序的解耦往往是一个麻烦的问题,以及在socket网络编程中也会有这样的问题.recv 和send之间,如果服务端有消息,问题需要发送给客户端,而那边的recv 被主程 ...
- form-data、x-www-form-urlencoded的区别
form-data可以上传文件格式的,比如mp3.jpg这些:x-www-form-urlencoded不能选择格式文件,只能传key-value这种string格式的内容.